Application Domains
Building a Large Scale Distributed System for Computing
The main application domain of the Large Scale Distributed System developed in Grand-Large is high performance computing. The two main programming models associated with our platform (RPC
and MPI) allow to program a large variety of distributed/parallel algorithms following computational paradigms like bag of tasks, parameter sweep, workflow, dataflow, master worker, recursive
exploration with RPC, and SPMD with MPI. The RPC programming model can be used to execute concurrently different applications codes, the same application code with different parameters and
library function codes. In all these cases, there is no need to change the code. The code must only be compiled for the target execution environment. LSDS are particularly useful for users
having large computational needs. They could typically be used in Research and Development departments of Pharmacology, Aerospace, Automotive, Electronics, Petroleum, Energy, Meteorology
industries. LSDS can also be used for other purposes than CPU intensive applications. Other resources of the connected PCs can be used like their memory, disc space and networking capacities. A
Large Scale Distributed System like XtremWeb can typically be used to harness and coordinated the usage of these resources. In that case XtremWeb deploys on Workers services dedicated to
provide and manage a disc space and the network connection. The storage service can be used for large scale distributed fault tolerant storage and distributed storage of very large files. The
networking service can be used for server tests in real life conditions (workers deployed on Internet are coordinated to stress a web server) and for networking infrastructure tests in real
like conditions (workers of known characteristics are coordinated to stress the network infrastructure between them).
Security and Reliability of Network Control Protocols
The main application domain for self-stabilizing and secure algorithms is LSDS where correct behaviours must be recovered within finite time. Typically, in a LSDS (such as a high performance
computing system), a protocol is used to control the system, submit requests, retrieve results, and ensure that calculus is carried out accordingly to its specification. Yet, since the scale of
the system is large, it is likely that nodes fail while the application is executing. While nodes that actually perform the calculus can fail unpredictably, a self-stabilizing and secure
control protocol ensures that a user submitting a request will obtain the corresponding result within (presumably small) finite time. Examples of LSDS where self-stabilizing and secure
algorithms are used, include global computing platforms, or peer to peer file sharing systems. Another application domain is routing protocols, which are used to carry out information between
nodes that are not directly connected. Routing should be understood here in its most general acceptance, e.g. at the network level (Internet routing) or at the application level (on virtual
topologies that are built on top of regular topologies in peer to peer systems). Since the topology (actual or virtual) evolves quickly through time, self-stabilization ensures that the routing
protocol eventually provides accurate information. However, for the protocol to be useful, it is necessary that it provides extra guarantees either on the stabilization time (to recover quickly
from failures) or on the routing time of messages sent when many faults occur. Finally, additional applications can be found in distributed systems that are composed of many autonomous agents
that are able to communicate only to a limited set of nodes (due to geographical or power consumption constraints), and whose environment is evolving rapidly. Examples of such systems are
wireless sensor networks (that are typically large of 10000+ nodes), mobile autonomous robots, etc. It is completely unrealistic to use centralized control on such networks because they are
intrinsically distributed; still strong coordination is required to provide efficient use of resources (bandwidth, battery, etc.).
End-User Tools for Computational Science and Engineering
Another Grand Large application domain is Large Scale Programming for Computational Science and Engineering. Two main approaches are proposed. First, we have to experiment and evaluate such
programming. Second, we have to develop tools for end-users.
In addition to the classical supercomputing and the GRID computing based on virtual organization, the large scale P2P approach proposes new computing facilities for computational scientists
and engineers. Thus, on one hand, it exists many applications, some of them are classical, such as Computational Fluid Dynamic or Quantum Physic ones, for example, and others are news and very
strategic such as Nanotechnologies, which will have to use a lot of computing power for long period of time in the close future. On another hand, it emerges a new large scale programming
paradigm for existing computers which can be accessible by scientific and engineer end-users for all classical application domains but also by new ones, such as some Non-Governmental
Organisations. During a first period, many applications would be based on large simulations rather than classical implicit numerical methods, which are more difficult to adapt for such large
problems and new programming paradigm. Nevertheless, we expected that more complex implicit methods would be adapted in the future for such programming. The potential number of peer and the
planed evolution of network communications, especially multicast ones, would permit to contribute to solve some of the larger grand challenge scientific applications.
Simulations and large implicit methods would always have to compute linear algebra routines, which will be our first targeted numerical methods (we also remark that the powerful worldwide
computing facilities are still rated using a linear algebra benchmark [http:/www.top500.org]). We will especially first focus on divide-and-conquer and block-based matrix methods to solve dense
problems and on iterative hybrid methods to solve sparse matrix problems. As these applications are utilized for many applications, it is possible to extrapolate the results to different
scientific domains.
Many smart tools have to be developed to help the end-user to program such environments, using up-to-date component technologies and languages. At the actual present stage of maturity of
this programming paradigm for scientific applications, the main goal is to experiment on large platforms, to evaluate and extrapolate performance, and to propose tools for the end-users; with
respect to many parameters and under some specify hypothesis concerning scheduling strategies and multicast speeds
Software
XtremWeb
XtremWeb is an open source middleware, generalizing global computing plarforms for a multi-user and multi-parallel programming context. XtremWeb relies on the notion of services to deploy a
Desktop Grid based on a 3 tiers architecture. This architecture gathers tree main services: Clients, Coordinators and Workers. Clients submit requests to the coordinator which uses the worker
resources to execute the corresponding tasks. Currently tasks concern computation but we are also considering the integration of storage and communication capabilities. Coordinator sub-services
provide resource discovery, service construction, service instantiation and data repository for parameters and results. A major concern is fault tolerance. XtremWeb relies on passive
replication and message logging to tolerate Clients mobility, Coordinator transient and definitive crashes and Worker volatility.
The Client service provides a Java API which unifies the interactions between the applications and the Coordinator. Three client applications are available: the Java API that can be used in
any Java applications, a command line (shell like) interface and a web interface allowing users to easily submit requests, consult status of their tasks and retrieve results. A second major
issue is the security. The origins of the treats are the applications, the infrastructure, the data (parameters and results) and the participating nodes. Currently XtremWeb provides user
authentication, application sandboxing and communication encryption. We have developed deployment tools for harnessing individual PCs, PCs in University or Industry laboratories and PCs in
clusters. XtremWeb provides a RPC interface for bag of tasks, parameter sweep, master worker and workflow applications. Associated with MPICH-V, XtremWeb allows the execution of unchanged MPI
applications on Desktop Grids.
XtremWeb has been tested extensively harnessing a thousand of Workers and computing a million of tasks. XtremWeb is deployed in several sites: University of Lille, University of Geneva,
University of Tsukuba, University of Paris Sud, University of California San Diego. In this last site, XtremWeb is the Grid engine of the Paris Sud University Desktop Grid gathering about 500
PCs. Two multi-parametric applications are to be used in production since the beginning of 2004: Aires belonging to the HEP Auger project and a protein conformation predictor using a molecular
dynamic simulator.
BitDew
The BitDew framework is a programmable environment for data management and distribution on computational Desktop Grids.
BitDew is a subsystem which could be easily integrated into other Desktop Grid systems (XtremWeb, BOINC, Condor etc..). Currently, Desktop Grids are mostly limited to embarrassingly parallel
applications with few data dependencies. BitDew objective is to broaden the use of Desktop Grids. The BitDew framework will enable the support for data-intense parameter sweep applications,
long-running applications which requires distributed checkpoint services, workflow applications and maybe in the future soft-realtime and stream processing applications.
BitDew offers programmers a simple API for creating, accessing, storing and moving data with ease, even on highly dynamic and volatile environments.
The BitDew programming model relies on 5 abstractions to manage the data : i) replication indicates how many occurrences of a data should be available at the same time on the network, ii)
fault-tolerance controls the policy in presence of machine crash, iii) lifetime is an attribute absolute or relative to the existence of other data, which decides the life cycle of a data in
the system, iv) placement drives movement of data according to dependency rules, v) distribution gives the runtime environment hints about the protocol to distribute the data. Programmers
define for every data these simple criteria, and let the BitDew runtime environment manage operations of data creation, deletion, movement, replication, and fault-tolerance operation.
SimBOINC
SimBOINC is a simulator for heterogeneous and volatile desktop grids and volunteer computing systems. The goal of this project is to provide a simulator by which to test new scheduling
strategies in BOINC, and other desktop and volunteer systems, in general. SimBOINC is based on the SimGrid simulation toolkit for simulating distributed and parallel systems, and uses SimGrid
to simulate BOINC (in particular, the client CPU scheduler, and eventually the work fetch policy) by implementing a number of required functionalities.
SimBOINC simulates a client-server platform where multiple clients request work from a central server. In particular, we have implemented a client class that is based on the BOINC client,
and uses (almost exactly) the client's CPU scheduler source code. The characteristics of client (for example, speed, project resource shares, and availability), of the workload (for example,
the projects, the size of each task, and checkpoint frequency), and of the network connecting the client and server (for example, bandwidth and latency) can all be specified as simulation
inputs. With those inputs, the simulator will execute and produce an output file that gives the values for a number of scheduler performance metrics, such as effective resource shares, and task
deadline misses.
XtremLab
Since the late 1990's, DG systems, such as SETI@Home, have been the largest and most powerful distributed computing systems in the world, offering an abundance of computing power at a
fraction of the cost of dedicated, custom-built supercomputers. Many applications from a wide range of scientific domains – including computational biology, climate prediction, particle
physics, and astronomy – have utilized the computing power offered by DG systems. DG systems have allowed these applications to execute at a huge scale, often resulting in major scientific
discoveries that would otherwise had not been possible.
The computing resources that power DG systems are shared with the owners of the machines. Because the resources are volunteered, utmost care is taken to ensure that the DG tasks do not
obstruct the activities of each machine's owner; a DG task is suspended or terminated whenever the machine is in use by another person. As a result, DG resources are volatile in the sense that
any number of factors can cause the task of a DG application to not complete. These factors include mouse or keyboard activity, the execution of other user applications, machine reboots, or
hardware failures. Moreover, DG resources are heterogeneous in the sense that they differ in operating systems, CPU speeds, network bandwidth, memory and disk sizes. Consequently, the design of
systems and applications that utilize these system is challenging.
The long-term overall goal of XtremLab is to create a testbed for networking and distributed computing research. This testbed will allow for computing experiments at unprecedented scale
(i.e., thousands of nodes or more) and accuracy (i.e., nodes that are at the "ends" of the Internet).
Currently, the short-term goal of XtremLab is to determine a more detailed picture of the Internet computing landscape by measuring the network and CPU availability of many machines. While
DG systems consist of volatile and heterogeneous computing resources, it unknown exactly how volatile and heterogeneous these computing resources are. Previous characterization studies on
Internet-wide computing resources have not taken into account causes of volatility such as mouse and keyboard activity, other user applications, and machine reboots. Moreover, these studies
often only report coarse aggregate statistics, such as the mean time to failure of resources. Yet, detailed resource characterization is essential for determining the utility of DG systems for
various types of applications. Also this characterization is a prerequisite for the simulation and modelling of DG systems in a research area where many results are obtained via simulation,
which allow for controlled and repeatable experimentation.
For example, one direct application of the measurements is to create a better BOINC CPU scheduler, which is the software component responsible for distributing tasks of the application to
BOINC clients. We plan to use our measurements to run trace-driven simulations of the BOINC CPU scheduler in effort to identify ways it can be improved, and for testing new CPU schedulers
before they are widely deployed.
We conduct availability measurements by submitting real compute-bound tasks to the BOINC DG system. These tasks are executed only when the host is idle, as determined by the user's
preferences and controlled the BOINC client. These tasks continuously perform computation and periodically record their computation rates to file. These files are collected and assembled to
create a continuous time series of CPU availability for each participating host. Utmost care will be taken to ensure the privacy of participants. Our simple, active trace method allows us to
measure exactly what actual compute power a real, compute-bound application would be able to exploit. Compared to other passive measurement techniques, our method is not as susceptible to OS
idiosyncracies (e.g. with process scheduling) and takes into account keyboard and mouse activity, and host load, all of which directly impact application execution.
The XtremLab project webpage is at
[http://xtremlab.lri.fr]
MPICH-V
Currently, MPICH-V proposes 7 protocols: MPICH-V1, MPICH-V2, MPICH-Vcl, MPICH-Pcl and 3 algorithms for MPICH-Vcausal. MPICH-V1 implements an original fault tolerant protocol specifically
developed for Desktop Grids relying on uncoordinated checkpoint and remote pessimistic message logging. It uses reliable nodes called Channel Memories to store all in transit messages. MPICH-V2
is designed for homogeneous networks like clusters where the number of reliable component assumed by MPICH-V1 is too high. It reduces the fault tolerance overhead and increases the tolerance to
node volatility. This is achieved by implementing a new protocol splitting the message logging into message payload logging and event logging. These two elements are stored separately on the
sender node for the message payload and on a reliable event logger for the message events. The third protocol, called MPICH-Vcl, is derived from the Chandy-Lamport global snapshot algorithm. It
implements coordinated checkpoint without message logging. This protocol exhibits less overhead than MPICH-V2 for clusters with low fault frequencies. MPICH-Pcl is a blocking implementation of
Chandy-Lamport algorithm. It consists in exchanging messages for emptying every communication channel before checkpointing all processes. MPICH-Vcausal concludes the set of message logging
protocols, implementing a causal logging. It provides less synchrony than the pessimistic logging protocols, allowing messages to influence the system before the sender can be sure that non
deterministic events are logged, to the cost of appending some information to every communication. This sum of information may increase with the time, and different causal protocols, with
different cut techniques, have been studied with the MPICH-V project.
The protocols developped during the first phase of the MPICH-V project are now being integrated into the two main open-source distributions of MPI, namely MPICH2 and OpenMPI. During this
integration, we focus on keeping the best performances (i.e. introducing the smallest changes in the library communication driver). Eventually, the fault-tolerance properties of these two
distributions should be provided by the Grand-Large project.
In addition to fault tolerant properties, MPICH-V:
provides a full runtime environment detecting and re-launching MPI processes in case of faults;
works on high performance networks such as Myrinet, Infiniband, etc (the performances are still divided by two);
allows the migration of a full MPI execution from one cluster to another, even if they are using different high performance networks.
The software, papers and presentations are available at
[http://www.mpich-v.net/]
YML
The complexity of P2P platforms is important. An end-user cannot manage manually such complexity. We provide a set of tools designed to develop and execute large coarse grain applications on
peer-to-peer systems. We developed and did the first experimentations of the YML framework for parallel programming on P2P architectures.
The main part of YML project is a high level language for scientific end-users to develop parallel programs for P2P platforms. This language integrates two different aspects. The first
aspect is a component description language. The second aspect is a way to link components: a coordination language called YvetteML. This language can express graphs of components. These graphs
represent applications. The goal of this split is to manage complex coupled applications on peer-to-peer systems.
We designed a framework to take advantage of YML language. It is composed of two directories and the YML Daemon. The daemon written in C++ uses information contained in both directories to
compile and execute YML applications on top of a peer to peer system. We identify first the two main roles of the daemon. Each role relies on a specific directory. This strict separation
enhances portability of applications and permits optimization during the execution stage in real-time. Currently we provide support for the XtremWeb peer to peer middleware and the OmniRPC grid
computing software.
To illustrate our approach, we did first experimentations for basic linear algebra routines on an XtermWeb P2P platform with a small number of peers. We did performance evaluations and
discussed on the necessity to introduce a new accurate performance model for this new computing paradigm.
YML project was launched at the ASCI CNRS lab in 2001 and is developed now in collaboration with the University of Versailles. YML is under integration into SPIN to propose a GUI ASP.
The Scientific Programming InterNet (SPIN)
SPIN (Scientific Programming on the InterNet), is a scalable, integrated and interactive set of tools for scientific computations on distributed and heterogeneous environments. These tools
create a collaborative environment allowing the access to remote resources.
The goal of SPIN is to provide the following advantages: Platform independence, Flexible parameterization, Incremental capacity growth, Portability and interoperability, and Web integration.
The need to develop a tool such as SPIN was recognized by the GRID community of the researchers in scientific domains, such as linear algebra. Since the P2P arrives as a new programming
paradigm, the end-users need to have such tools. It becomes a real need for the scientific community to make possible the development of scientific applications assembling basic components
hiding the architecture and the middleware. Another use of SPIN consists in allowing to build an application from predefined components ("building blocks") existing in the system or developed
by the developer. The SPIN users community can collaborate in order to make more and more predefined components available to be shared via the Internet in order to develop new more specialized
components or new applications combining existing and new components thanks to the SPIN user interface.
SPIN was launched at ASCI CNRS lab in 1998 and is now developed in collaboration with the University of Versailles, PRiSM lab. SPIN is currently under adaptation to incorporate YML, cf.
above. Nevertheless, we study another solution based on the Linear Algebra KErnel (LAKE), developped by the Nahid Emad team at the University of Versailles, which would be an alternative to
SPIN as a component oriented integration with YML.
V-Grid
This project started officially in September 2004. V-Grid is a virtualization software for large scale distributed system emulation. This software allows folding a distributed systems 100 or
1000 times larger than the experimental testbed. V-Grid virtualizes distributed systems nodes on PC clusters, providing every virtual node its proper and confined operating system and execution
environment. Thus compared to large scale distributed system simulators or emulators (like MicroGrid), V-Grid virtualizes and schedules a full software environment for every distributed system
node. V-Grid research concerns emulation realism and performance. A first work concerns the definition and implementation of metrics and methodologies to compare the merits of distributed
system virtualisation tools. Since there is no previous work in this domain, it is important to define what and how to measure in order to qualify a virtualization system relatively to realism
and performance. We defined a set of metrics and methodologies in order to evaluate and compared virtualisation tools for sequential system. For example a key parameter for the realism is the
event timing: in the emulated environment, events should occur with a time consistent with a real environment. An example of key parameter for the performance is the linearity. The performance
degradation for every virtual machine should evolve linearly with the increase of the number of virtual machines. We conducted a large set of experiments, comparing several virtualisation tools
including Vserver, VMware, User Mode Linux, Xen, etc. The result demonstrates that none of them provides both enough realism and performance. As a consequence, we are currently studying
approaches to cope with these limits. We have made a virtual patform on the GDX cluster with the Vserver virtualization tool. On this platform, we have launched more than 20K virtual machines
(VM) with a folding of 100 (100 VM on each physical marchine). However, some recent experiments have shown that a too high folding factor may cause a too long execution time because of some
problems like swapping. Currently, we are conducting experiments on another platform based on the virtualization tool named Xen which has been strongly improved since 2 years. We expect to get
better result with Xen than with Vserver.
PVC: Private Virtual Cluster
Current complexity of Grid technologies, the lack of security of Peer-to-Peer systems and the rigidity of VPN technologies make sharing resources belonging to different institutions still
technically difficult.
We propose a new approach called "Instant Grid" (IG), which combines various Grid, P2P and VPN approaches, allowing simple deployment of applications over different administration domains.
Three main requirements should be fulfilled to make Instant Grids realistic: simple networking configuration (Firewall and NAT), no degradation of resource security, no need to re-implement
existing distributed applications.
Private Virtual Cluster, is a low-level middle-ware that meets Instant Grid requirements. PVC turns dynamically a set of resources belonging to different administration domains into a
virtual cluster where existing cluster runtime environments and applications can be run. The major objective of PVC is to establish direct connections between distributed peers. To connect
firewall protected nodes in the current implementation, we have integrated three techniques: UPnP, TCP/UDP Hole Punching and a novel technique Traversing-TCP.
One of the major application of PVC is the third generation desktop Grid middleware. Unlike BOINC and XtremWeb (which belog to the second generation of desktop Grid middleware), PVC allows
the users to build their Desktop Grid environment and run their favorite batch scheduler, distributed file system, resource monitoring and parallel programming library and runtime software. PCV
ensures the connectivity layer and provide a virtual IP network where the user can install and run existing cluster software.
By offering only the connectivity layer, PVC allows to deploy P2P systems with specific applications, like file sharing, distributed computing, distributed storage and archive, video
broadcasting, etc.
OpenWP
Distributed applications can be programmed on the Grid using workflow languages, object oriented approaches (Proactive, IBIS, etc.), RPC programming environments (Grid-RPC, DIET), component
based environments (generaly based on Corba) and parallel programming libraries like MPI.
For high performance computing applications, most of the existing codes are programmed in C, Fortran and Java. These codes have 100,000 to millions of lines. Programmers are not inclined to
rewrite then in a "non standard" programming language, like UPC, CoArray Fortran or Global Array. Thus environments like MPI and OpenMPI remain popular even if they require hybrid approaches
for programming hierarchical computing infrastructures like cluster of multi-processors equipped with multi-core processors.
Programming applications on the Grid add a novel level in the hierarchy by clustering the cluster of multi-processors. The programmer will face strong difficulties in adapting or programming
a new application for these runtime infrastructures featuring a deep hierarchy. Directive based parallel and distributed computing is appealing to reduce the programming difficulty by allowing
incremental parallelization and distribution. The programmer add directives on a sequential or parallel code and may check for every inserted directive its correction and performance
improvement.
We believe that directive based parallel and distributed computing may play a significant role in the next year for programming High performance parallel computers and Grids. We have started
the development of OpenWP. OpenWP is a directive based programming environment and runtime allowing expressing workflows to be executed on Grids. OpenWP is compliant with OpenMP and can be used
in conjunction with OpenMP or hybrid parallel programs using MPI + OpenMP.
OpenWP environment consists in a source to source compiler and a runtime. OpenWP parser, interpret the user directives and extract functional blocks from the code. These blocks are inserted
in a library distributed on all computing nodes. In the original program, the functional blocks are replaced by RPC calls and calls to synchronization. During the execution, the main program
launches non blocking RPC calls to functions on remote nodes and synchronize the execution of remote functions based on the synchronization directives inserted by the programmer in the main
code. Compared to OpenMP, OpenWP does not consider a shared memory programming approach. Instead, the source to source compiler insert data movements calls in the main code. Since the data set
can be large in Grid application, the OpenWP runtime organize the storage of data sets in a distributed way. Moreover, the parameters and results of RPC calls are passed by reference, using a
DHT. Thus, during the execution, parameter and result references are stored in the DHT along with the current position of the datasets. When a remote function is called, the DHT is consulted to
obtain the position of the parameter data sets in the system. When a remote function terminates its execution, it stores the result data sets and store a reference to the data set in the
DHT.
This environment is under construction. A prototype version is running.
FAult Injection Language (FAIL)
FAIL (FAult Injection Language) is a new project that was started in 2004. The goal of this project is to provide a controllable fault injection layer in existing distributed applications
(for clusters and grids). A new language was designed to implement expressive fault patterns, and a preliminary implementation of the distributed fault injector based on this language was
developped.
New Results
Large Scale Distributed Systems
Fault Tolerant MPICH-V
In
Programming the Grid
In
Private Virtual Cluster
Given current complexity of Grid technologies, the lack of security of P2P systems and the rigidity of VPN technologies make sharing resources belonging to different institutions still
technically difficult. In
V-Grid: a Large Scale Emulator
Virtualization tools are becoming popular in the context of Grid Computing because they allow running multi- ple operating systems on a single host and provide a confined execution
environment. In several Grid projects, virtualization tools are envisioned to run many virtual machines per host. This immediately raises the issue of virtualization scalability. In this
paper, we compare the scalability merits of 4 virtualization tools. First, from a simple experiment, we motivate the need for simple microbenchmarks. Second, we present a set of metrics and
related methodologies. We propose 4 microbenchmarks to measure the different scalability parameters for the different machine resources (CPU, memory disk and network) on 3 scalability metrics
(overhead, linearity and isolation). Third, we compare 4 virtual machine technologies (Vserver, Xen, UML and VMware). The results of this study demonstrate that all the compared tools present
different behaviors with respect to scalability, in terms of overhead, resource occupation and isolation. Thus this work will help user to select tools according to their application
characteristics
We have made a virtual patform on the GDX cluster with the Vserver virtualization tool. On this platform, we have been able to launch more than 20K virtual machines (VM) with a folding of
100 (100 VM on each physical marchine). However, some recent experiments have shown that a too big repliment factor may cause a bad execution time because of some problems like swapping.
Indeed, when you launch 100 VM on a physical machine, all the ressources are divided by 100 (memory, CPU time, bandwith, ...), so even a little application will use 100 times more memory and
can made the physical machine to swap. We have also tested a bittorrent transfert on this platform and we have observed that with a 100 folding factor, the execution time have not been
multiply by 100 as expected but by more than 100. It show that the continuous context changing between virtual machines cause very bad performances on hard disk cache.
Characterizing Intranet and Internet Desktop Grids
Desktop grids, which use the idle cycles of many desktop PC's, are currently the largest distributed systems in the world. Despite the popularity and success of many desktop grid projects,
the heterogeneity and volatility of hosts within desktop grids has been poorly understood. Yet, host characterization is essential for accurate simulation and modelling of such platforms. In
Also, in
Scheduling on Volatile and Heterogeneous Resources
Because desktop computing resources are volatile, achieving performance guarantees such as task completion rate is difficult. In
Large Scale Peer to Peer Performance Evaluations
In
In
Parallelizing and distributing the real symmetric eigenproblem has been extensively studied for supercomputers and highperformance clusters. Global computing introduces new constraints and
we must propose new algorithms adapted to this kind of environment. In
In
In
Volatility and Reliability Processing
Self-stabilization
Stabilizing distributed systems expect all the component processes to run predefined programs that are externally mandated. In Internet scale systems, this is unrealistic, since each
process may have selfish interests and motives related to maximizing its own payoff.
Also, we specify the conflict manager abstraction. Informally, a conflict manager guarantees that any two neighboring nodes can not enter their critical simultaneously (safety), and that
at least one node is able to execute its critical section (progress). The conflict manager
Also, in
A 1-adaptive self-stabilizing system is a self-stabilizing system that can correct any memory corruption of a single process in one computation step. 1-adaptivity means that if in a
legitimate state the memory of a single process is corrupted, then the next system transition will lead to a legitimate state and the system will recover a correct behavior. Thus 1-adaptive
self-stabilizing algorithms guarantee the very strong property that a single fault is corrected immediately and consequently that it cannot be propagated. Our aim in
We present in
Byzantine containment and resilience
As a new challenge of containing the unbounded influence of Byzantine processes in self-stabilizing protocols, we introduced a novel concept of strong stabilization. The strong
stabilization relaxes the requirement of strict stabilization so that processes beyond the containment radius are allowed to be disturbed by Byzantine processes, but only a limited number of
times. A self-stabilizing protocol is (t,c,f)-strongly stabilizing
Also, we study in
Sensor Networks
We quantify in
Also, we present in
The advent of large scale multi-hop wireless networks highlights problems of fault tolerance and scale in distributed system, motivating designs that autonomously recover from transient
faults and spontaneous reconfiguration. Self-stabilization provides an elegant solution for recovering from such faults. We present complexity analysis for a family of self-stabilizing vertex
coloring algorithms in the context of multi-hop wireless networks. Such coloring processes are used in several protocols for solving many different issues (clustering, synchronizing...).
Overall, our results
Benchmarking Fault-tolerance
We reviewed in
One important contribution to the community that is developing Grid middleware is the definition and implementation of benchmarks and tools to assess the performance and dependability of
Grid applications and the corresponding middleware. In
In a network consisting of several thousands computers, the occurrence of faults is unavoidable. Being able to test the behavior of a distributed program in an environment where we can
control the faults (such as the crash of a process) is an important feature that matters in the deployment of reliable programs. In
One of the topics of paramount importance in the development of Cluster and Grid middleware is the impact of faults since their occurrence probability in a Grid infrastructure and in
large-scale distributed system is actually very high. MPI (Message Passing Interface) is a popular abstraction for programming distributed computation applications. FAIL is an abstract
language for fault occurrence description capable of expressing complex and realistic fault scenarios. In
Mobile agents
We consider in
 (
(
log(
n/
q))memory bits to explore all n-node graphs. The proof implies that, for any set of q K-state robots, there exists a graph of size O(qK) that no robot of this set
can explore, which improves the O(KO(q)) bound by Rollik (1980). Our main result is an application of this latter result, concerning terminating graph exploration with one robot, i.e., in
which the robot is requested to stop after completing exploration. For this task, the robot is provided with a pebble, that it can use to mark nodes (without such a marker, even terminating
exploration of cycles cannot be achieved). We prove that terminating exploration requires
(
logn)bits of memory for a robot achieving this task in all n-node graphs.
Peer-to-peer systems design
In
Kleinberg showed how to augment meshes using random edges, so that they become navigable; that is, greedy routing computes paths of polylogarithmic expected length between any pairs of
nodes. Is such an augmentation is possible for all graphs? In
In
O(
nk3)-time algorithm that, given any
n-node width-
ktree-decomposition of a connected graph
G, returns a connected tree-decomposition of
Gof width
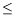
k.
k+ 1searchers, where
kis the minimum number of searchers required to clear the network in a monotone connected way, computed in the centralized and synchronous setting.