Overall Objectives
Background
TALARIS stands for
Traitment Automatique des Langues: Representation, Inference, et Semantique. As this name suggests, the aim of the TALARIS team is to investigate semantic phenomena (broadly construed)
in natural language from a computational perspective. More concretely, TALARIS's goal is to develop grammars (with a special emphasis on French) with a semantic dimension, to explore the
linguistic and computational issues involved in such areas as natural language generation, textual entailment recognition, discourse and dialogue modeling, pragmatics, and multilinguality, and
to investigate the interplay between representation and inference in computational semantics for natural language.
Organization
The work of the TALARIS team can be subdivided into four overlapping and mutually supporting categories.
Computational Semantics. These theme is devoted to the theoretical and computational issues involved in building semantic representations for natural language. Special emphasis is placed
on developing large scale semantic coverage for the French Language.
Discourse, Dialogue and Pragmatics. This theme is devoted to developing theoretical and computational models of discourse and dialogue precessing, and investigating the inferential
impact of pragmatic factors (that is, the factors affecting how humans being actually use language).
Logics for Natural Language and Knowledge Representation. The theme is devoted to theoretical and computational tools for working with logics suitable for natural language inference and
knowledge representation. Special emphasis is place on hybrid logic, higher order logic, and discourse representation theory (DRT).
Multilinguality for Multimedia. This theme is devoted to creating generic ISO-based mechanisms for representing and dealing with multilingual textual information. The center of this
activity is the MLIF (Multi Lingual Information Framework) specification platform for elementary multilingual units.
Overall Objectives
The major long term computational goals of the TALARIS team are:
The creation of a large scale computational semantics framework for French that supports deep semantic analysis and surface realisation (the production of sentences from
meaning representations),
The creation of dialogue systems (in particular, for French) that support flexible and realistic interaction with the user.
The creation of efficient inference systems for logics that are capable of representing natural language content and the background knowledge required to support
reasoning.
These computational goals will be pursued in the context of theoretical investigations that will rigorously map out the required scientific and mathematical context.
Highlights
The main highlight of 2007 is simply this: it is the first year of TALARIS's existence! Like many other INRIA project teams, TALARIS was born out of a previously existing project — but the
past year has been marked by heavy personnel changes. The result is a smaller team that is tightly focused on the goals just listed.
But our birthday year was marked by another highlight — the successful inauguration of a brand new
Erasmus MundusMasters degree in
Language and Communication Technology(for detailed information, see
[http://
lct-master.
org]). This degree, which is taught as one of the tracks of the Masters in Cognitive Science at the University of Nancy 2, is designed to attract to Europe the very best
international students in computational linguistics. Students must spend one year at each of two partner universities in two different European countries (in addition to the University of
Nancy 2, they can choose between the University of Bolzano in Italy, Charles University in the Czech Republic, the University of Groningen in the Netherlands, the University of the
Saarland in Germany, and the University of Malta in Malta).
Needless to say, this Masters degree is not just relevant to TALARIS — indeed it is interesting precisely because it is relevant to the entire Nancy computational linguistics and language
engineering community (which includes such LORIA based teams as CALLIGRAMME, ORPAILLEUR, PAROLE and READ and the Lexique team at ATILF). Nonetheless, TALARIS members (notably Carlos Areces,
Patrick Blackburn and Claire Gardent) were heavily involved in setting up the program — and so its successful start in 2007 is special cause for celebration in the team. Seven
Erasmus MundusMasters students (3 first year, 4 second year) chose to come to Nancy 2 this year; we hope this success will be repeated in the remaining four years of the
program.
Computational Linguistics and Computational Logic
computational semantics
computational logic
knowledge representation
inference
linguistic resources
logic engineering
empirical studies
We said above that the central research theme of TALARIS was computational semantics (where “semantics” is broadly construed to cover various pragmatic and discourse level phenomena) and
that TALARIS is particularly focused on investigating the interplay between representation and inference. Another way of putting this would be to say that the scientific foundations of
TALARIS's work boil down to the motto:
computational linguisticsmeets
computational logicand
knowledge representation.
From computational linguistics we take the large linguistic and lexical semantics resources, the parsing and generation algorithms, and the insight that (whenever possible) statistical
information should be employed to cope with ambiguity. From computational logic and knowledge representation we take the various languages and methodologies that have been developed for
handling different forms of information (such as temporal information), the computational tools (such as theorem provers, model builders, model checkers, sat-solvers and planners) that have
been devised for working with them, together with the insight that, whenever possible, it is better to work with inference tools that have been tuned for particular problems, and moreover that,
whenever possible, it is best to devote as little computational energy to inference as possible.
This picture is somewhat idealized. For example, for many languages (and French is one of them) the large scale linguistic resources (lexicons, grammars, WordNet, FrameNet, PropBank, etc.)
that exist for English are not yet available. In addition, the syntax/semantics interface often cannot be taken for granted, and existing inference tools often need to be adapted to cope with
the logics that arise in natural language applications (for example, existing provers for Description Logic, though excellent, do not cope with temporal reasoning). Thus we are not simply
talking about bringing together known tools, and investigating how they work once they are combined — often a great deal of research, background work and development is needed. Nonetheless, the
ideal of bringing together the best tools and ideas from computational linguistics, knowledge representation and computational logic and putting them to work in coordination is the guiding
line.
Another simplification involved in the “computational linguistics meet computational logic and knowledge representation” motto is that often the goal is to find out when the use of
computational logic can be
avoidedor
minimized. Logical inference can be computationally expensive, and if simpler statistical methods can be used, or if only computationally tractable inference methods (such as model
checking) are required, then it is highly desirable to turn to them. Empirically inspired heuristics are needed so that the tools of computational logic are only applied when truly needed, and
only to the smallest problems possible.
To ensure that theoretically plausible ideas really are applicable, and to gain insight as to when empirically oriented methods can be usefully employed, TALARIS focuses on concrete semantic
phenomena (for example, tense and aspect, presupposition and anaphora resolution, dialogue structure, etc.). By carefully examining the empirical data, we aim to determine which phenomena
require inference and which not; which can be dealt with using weak logics and which not; which can be handled statistically and which not; what scales up successfully and what does not...
Semantics and Inference
Over the next decade, progress in natural language semantics will likely depend on obtaining a deeper understanding of the role played by inference. One of the simplest levels at which
inference enters natural language is as a disambiguation mechanism. Utterances in natural language are typically highly ambiguous: inference allows human beings to (seemingly effortlessly)
eliminate the irrelevant possibilities and isolate the intended meaning. But inference can be used in many other processes, for example, in the integration of new information into a known
context. This is important when generating natural language utterances. For this task we need to be sure that the utterance we generate is suitable for the person being addressed. That is, we
need to be sure that the generated representations fit in well with the recipient's knowledge and expectations of the world, and it is inference which guides us in achieving this.
Much recent semantic research actively addresses such problems by systematically integrating inference as a key element. This is an interesting development, as such work redefines the
boundary between semantics and pragmatics. For example, van der Sandt's algorithm for presupposition resolution (a classic problem of pragmatics) uses inference to guarantee that new
information is integrated in a coherent way with the old information.
The TALARIS team investigates such semantic/pragmatic problems from various angles (for example, from generation and discourse analysis perspectives) and tries to combine the insights
offered by different approaches. For example, for some applications (e.g., the textual entailment task) shallow syntactic parsing combined with fast inference in description logic may be the
most suitable approach. In other cases, deep analysis of utterances or sentences and the use of a first-order inference engine may be better. Our aim is to explore these approaches and their
limitations.
Linguistic Resources
In an ideal world, computational semanticists would not have to worry overly much about linguistic resources. Large scale lexica, treebanks, and wide coverage grammars (supported by fast
parsers and offering a flexible syntax semantics interface) would be freely available and easy to combine and use. The semanticist could then focus on modeling semantic phenomena and their
interactions.
Needless to say, in reality matters are not nearly so straightforward. For a start, for many languages (including French) there are no large-scale resources of the sort that exist for
English. Furthermore even in the case of English, the idealized situation just sketched does not obtain. For example, the syntax/semantics interface cannot be regarded as a solved problem:
phenomena such as gapping and VP-ellipsis (where a verb, or verb phrase, in a coordinated sentence is missing and has to be somehow “reconstructed” from the previous context) still offer
challenging problems for semantic construction.
Thus a team like TALARIS simply cannot focus exclusively on semantic issues: it must also have competence in developing and maintaining a number of different lexical resources (and in
particular, resources for French).
TALARIS is involved in such aspects in a number of ways. For example, it participates in the development of an open source syntactic an synonymic lexicon for French, in an attempt to lay the
ground for a French version of FrameNet; and it also works on developing a large scale, reversible (i.e., usable both for parsing and for generation) Tree Adjoining Grammar for French.
Logic Engineering
Once again, in the ideal world, not only would computational semanticists not have to worry about the linguistic resources at their disposal, but they would not have to worry about the
inference tools available either. These could be taken for granted, applied as needed, and the semanticist could concentrate on developing linguistically inspired inference architectures. But
in spite of the spectacular progress made in automated theorem proving (both for very expressive logics like predicate logics, and for weak logics like description logics) over the last decade,
we are not yet in the ideal world. The tools currently offered by the automated reasoning community still have a number of drawbacks when it comes to natural language applications.
For a start, most of the efforts of the first-order automated reasoning community have been devoted to theorem proving; model building, which is also a required technology for natural
language processing, is nowhere nearly as well developed, and far fewer systems are available. Secondly, the first-order reasoning community has adopted a resolutely `classical' approach to
inference problems: their provers focus exclusively on the satisfiability problem. The description logic community has been much more flexible, offering architectures and optimisations which
allow a greater range of problems to be handled more directly. One reason for this has been that historically, not all description logics offered full Boolean expressivity. So there is a long
tradition in description logic of treating a variety of inference problems directly, rather than via reduction to satisfiability. Thirdly, many of the logics for which optimised provers exists
do not directly offer the kinds of expressivity required for natural language applications. For example, it is hard to encode temporal inference problems in implemented versions of description
logics. Fourth, for very strong logics (notably higher-order logics) few implementations exists and their performance is currently inadequate.
These problems are not insurmountable, and TALARIS members are actively investigating ways of overcoming them. For a start, logics such as higher-order logic, description logic and hybrid
logic are nowadays thought of as various fragments of (or theories expressed in) first-order logic. That is, first-order logic provides a unifying framework that often allows transfer of tools
or testing methodologies to a wide range of logics. For example, the hybrid logics used in TALARIS (which can be thought of as more expressive versions of description logics) make heavy use of
optimization techniques from first-order theorem proving.
Moreover — and from a logical perspective, this is the most interesting point — the interaction between natural language and computational logic is not a one way street. The problems that
arise in natural language may well be significant for developments in computational logic. As an example of this, early versions of the CURT software (an educational system for computational
semantics developed by Patrick Blackburn and Johan Bos) made use of a standard first-order model builder called MACE. The inference problems that the system generated were then used as tests
when the PARADOX model builder was developed, leading to considerable performance improvements. Similarly, natural language applications have also inspired significant performance enhancements
to the RACER description logic prover. Feedback from natural language to logic is likely to be an important theme in future developments.
Empirical Studies
The role of empirical methods (model learning, data extraction from corpora, evaluation) has greatly increased in importance in both linguistics and computer science over the last fifteen
years. TALARIS members have been working for many years on the creation, management and dissemination of linguistic resources reusable by the scientific community, both in the context of
implementation of data servers, and in the definition of standardized representation formats like TAG-ML. In addition, they have also worked on the applications of linguistic ideas in
multimodal settings and multimedia.
The work in this area is in concordance with our scientific projects. As we said above, one of the most important points that needs to be understood about logical inference is how its use
can be minimized and intelligently guided. Ultimately, such minimization and guidance must be based on empirical observations concerning the kinds of problems that arise repeatedly in natural
language applications.
Finally, is should be remarked that the emphasis on empirical studies lends another dimension to what is meant by inference. While much of TALARIS's focus is on symbolic approaches to
inference, statistical and probabilistic methods, either on their own or blended with symbolic approaches, are likely to play an increasingly important role in the future. TALARIS researchers
are well aware of the importance of such approaches and are interested in exploring their strengths and weaknesses, and where relevant, intend to integrate them into their work.
Application Domains
Modular Grammar Building.
The development of large scale grammars is a complex task which usually involves factorising information as much as possible. While good grammar writing and factorisation environments exist
for “non tree grammars” (e.g., HPSG, LFG), this is not the case for “tree based grammars” such as TAG, Interaction Grammars or Tree Description Grammars. The Extended Metagrammar Compiler (XMG)
developed at TALARIS remedies this shortcoming while additionally providing a clean and modular way to describe several linguistic dimensions thereby supporting the production of tree grammars
with semantic information
Referential Expressions
TALARIS has a longstanding interest in the semantics and the processing of referential expressions. In recent years, an extensive corpus annotation has been carried out on 5.000 definite
descriptions
Surface Realization
The tree adjoining grammar for French developed by TALARIS associates with each NL expression not only a syntactic tree but also a semantic representation. Interestingly, the semantic
calculus used is reversible in that the association between strings and semantic representations is non-directional (declarative). We put this feature to work and have been working over the
years towards developing a surface realiser for French called GenI
Textual Entailment.
In essence, the textual entailment recognition task is an inference task, namely deciding whether the information contained in a given text
T1can be inferred from the information provided by another text
T2.
It is crucial to be able to answer this question. One important characteristic of natural language is the large number of ways in which it can express the same information. Many natural
language processing applications like question answering, information retrieval, generation, and anaphora resolution need to deal with this diversity efficiently and accurately, and recognising
textual entailments is a key step towards this.
Textual entailment recognition is a difficult task. The approach we are experimenting with is to encode lexical information as a description logic ontology (or a hybrid logic theory) and
then to use logical inference to compute the result.
Computational Logics and Computational Semantics.
Members of TALARIS are among the main figures proposing the idea of using inference (and in particular, using computational tools like model builders and theorem provers) as an integral part
of different tasks in computational semantics, mainly during semantic construction
Hybrid Automated Deduction
TALARIS main contribution in this topic has been the design of resolution calculi for hybrid logics, that were then implemented into the HyLoRes theorem prover. In particular, TALARIS
members have proved that such calculi can be enhanced with optimisations of order and selection functions without losing completeness. Moreover, the first `effective' (i.e., directly
implementable) termination proof for
 has been recently established and the technique is being extended to more expressive languages
has been recently established and the technique is being extended to more expressive languages
During this year, and making use of modularized code from
HyLoRes, we have implemented a tableaux based prover for hybrid logics called
HTab
We have also started to explore other decision methods (e.g., game based decision methods) which are useful for non-standard semantics like topological semantics. The prover
HyLoBanis an example of this work
Multimedia
MLIF (Multi Lingual Information Framework) is being designed as a generic ISO-based mechanism for representing and dealing with multilingual textual information. A preliminary version of
MLIF has been associated to digital media within the ISO/IEC MPEG context and dealing with subtitling of video content, dialogue prompts, menus in interactive TV, and descriptive information
for multimedia scenes. MLIF comprises a flexible specification platform for elementary multilingual units that may be either embedded in other types of multimedia content or used autonomously
to localise existing content.
Software
The eXtended Meta-Grammar (
XMG) Compiler and Tools
A metagrammar compiler generates automatically a grammar from a reduced description called a MetaGrammar. This description captures the linguistic properties underlying the syntactical rules
of a grammar. Various past and present TALARIS members have been working on metagrammar compilation since 2001 and several tools have been developed within this framework starting with the MGC
system of Bertrnad Gaiffe (now of ATILF,
Analyse et Traitment Informatique de la Langue Francaisea Nancy-based CNRS unit) to the newly developed
XMGsystem of Crabbé et al.
The
XMGsystem is a 2nd generation compiler that proposes (a) a representation language allowing the user to describe in a factorised and flexible way the
linguistic information contained in the grammar, and (b) a compiler for this language (using a Warren Abstract Machine-like architecture). An innovative feature of this compiler is the fact
that it makes it possible to describe several linguistic dimensions, and in particular it is possible to define a natural Syntax/Semantics interface within the Metagrammar.
The compiler actually supports two syntactic formalisms (Tree Adjoining Grammars and Interaction Grammars) and the description both of the syntactic and of the semantic dimension of natural
language. The generated grammars are in XML format, which makes them easy to reuse. Plug-ins have been realised with the LLP2 parser, with Eric de la Clergerie's DyALog parser and with the
GenIgenerator. Future work concerns the modularisation and the extension of
XMGto define a library of languages describing linguistic data allowing the user to describe his own target formalism.
Developed under the supervision of Denys Duchier, the
XMGcompiler is the result of an intensive collaboration with CALLIGRAMME. It has been implemented in Oz/Mozart and runs under the Linux, Mac, and
Windows platforms. It is available with tools easing its use with parsers and generators (tree viewer, duplicate remover, anchoring module, metagrammar browser).
The system is currently being used and tested by Owen Rambow (University of Columbia, USA) and Laura Kallmeyer (University of Tuebingen, Germany).
Version: 1.1.4
License: CeCILL
Last update: 27/09/2005
Web site:
[http://
sourcesup.
cru.
fr/
xmg/
]
Documentation:
[http://
sourcesup.
cru.
fr/
xmg/
#Documentation]
Authors: Benoit Crabbé, Denys Duchier, Joseph Le Roux, Yannick Parmentier
Contact: Benoit Crabbé, Yannick Parmentier
Frolog
Frolog is a dialogue system based on current technology from computational linguistics, artificial intelligence planning and theorem proving. It implements a text adventure game engine that
uses natural language processing techniques to analyse the player's input and generate the system's output.
The Frolog core is implemented in Prolog, but it uses external tools for the most heavy-loaded tasks. It performs syntactic analysis of the input based on an English grammar developed using
XMGand computes a flat semantic representation using the
SemConstsemantic construction tool. It then uses the constructed semantic representation and an off-the-shelf planner to interpret the player's
intention and change the world model accordingly. The world is modelled as a knowledge base in description logics, and accessed using the Description Logic theorem prover
Racer. Finally, the results of the action, or descriptions of objects, are generated automatically, using the
GenIgenerator.
Frolog's main utility is to serve as a laboratory in order to test pragmatic theories about presupposition accommodation. However, it will also result in the first integrated system to use
SemTag(the LORIA toolbox for TAG-based Parsing and Generation).
Version: 0.9
License: GPL
Last update: 2007-11-26
Web site:
[http://
trac.
loria.
fr/
projects/
frolog/
wiki]
Documentation:
[http://
trac.
loria.
fr/
projects/
frolog/
wiki/
Documentation]
Authors: Luciana Benotti, Alejandra Lorenzo, Laura Perez
Contact: Luciana Benotti
GenIGenerator
The
GenIgenerator is a successor of the InDiGen generator. Also based on a chart algorithm, it is implemented in Haskell (one of the leading functional
programming languages available nowadays) and aims for modularity, re-usability and extensibility. The system is “stand-alone” as we use the Glasgow Haskell compiler to obtain executable code
for Windows, Solaris, Linux and Mac OS X.
The
GenIgenerator uses efficient datatypes and intelligent rule application to minimise the generation of redundant structures. It also uses a notion of
polarities as a means first, of coping with lexical ambiguity and second, of selecting variants obeying given syntactic constraints.
The grammar used by the
GenIgenerator is produced using the MetaGrammar Compiler and covers the basic syntactic structures of French as described in Anne Abeillé's book “An
electronic grammar for French”.
The system can process the output of the
XMGMetagrammar compiler mentioned above.
Version: 0.8
License: GPL
Last update: 2005-10-17
Web site:
[http://
wiki.
loria.
fr/
wiki/
GenI]
Documentation:
[http://
wiki.
loria.
fr/
wiki/
GenI/
Manual]
Project(s):
GenI
Authors: Carlos Areces, Claire Gardent, Eric Kow
Contact: Claire Gardent
HyLoRes, a Resolution Based Theorem Prover for Hybrid Logics
HyLoResis a resolution based theorem prover for hybrid logics (it is complete for the hybrid language H(@,
 ), a very expressive but undecidable language, and it implements a decision method for the sublanguage H(@)). It implements a version of the “given clause” algorithm which is the
underlying framework of many current state of the art resolution-based theorem provers for first-order logic; and uses heuristics of order and selection function to prune the search space on
the space of possible generated clauses.
), a very expressive but undecidable language, and it implements a decision method for the sublanguage H(@)). It implements a version of the “given clause” algorithm which is the
underlying framework of many current state of the art resolution-based theorem provers for first-order logic; and uses heuristics of order and selection function to prune the search space on
the space of possible generated clauses.
HyLoResis implemented in Haskell, and compiled with the Glasgow Haskell compiler (thus, users need no additional software to use the prover). We have
also developed a graphical interface.
The interest of
HyLoResis twofold: on one hand it is the first mature theorem prover for hybrid languages, and on the other, it is the first modern resolution based
prover for modal-like languages implementing optimisations and heuristics like order resolution with selection functions.
Version: 2.4
License: GPL
Last update: 2007-12-01
Web site:
[http://
trac.
loria.
fr/
projects/
hylores]
Documentation:
[http://
trac.
loria.
fr/
projects/
hylores]
Authors: Carlos Areces, Daniel Gorín and Juan Heguiabehere
Contact: Carlos Areces
HTab, a Tableau Based Theorem prover for Hybrid Logics
The main goal behind
HTabis to make available an optimised tableaux prover for hybrid logics, using algorithms that ensure termination. We ultimately aim to cover a number
of frame conditions (i.e., reflexivity, symmetry, antisymmetry, etc.), as far as we can ensure termination. Moreover, we are interested in providing a range of inference services beyond
satisfiability checking. For example, the current version of
HTabincludes model generation (i.e.,
HTabcan generate a model from a saturated open branch in the tableau).
HTaband
HyLoResare actually being developed in coordination, and a generic inference system involving both provers is being designed. The aim is to take
advantage of the dual behaviour existing between the resolution and tableaux algorithms: while resolution is usually most eficient for unsatisfiable formulas (i.e., a contradiction can be
reported as soon as the empty clause is derived), tableaux methods are better suited to handle satisfiable formulas (i.e., a saturated open branch in the tableaux represents a model for the
input formula).
Version: 1.2.1
License: GPL
Last update: 2007-12-01
Web site:
[http://
trac.
loria.
fr/
projects/
htab]
Documentation:
[http://
trac.
loria.
fr/
projects/
htab]
Authors: Carlos Areces, Guillaume Hoffmann
Contact: Guillaume Hoffmann
HyLoBan, a Game Based Theorem Prover for Topological Hybrid Logics
HyLoBanis a game-based prover, resulting from a direct implementation of Sustretov's game-based proofs of the PSPACE-completeness of the hybrid logics
of T0 and T1 topological spaces. The interest of this approach is that termination is guaranteed and in addition the underlying game-based architecture is of independent interest; its
disadvantage is that (at present) it is still extremely ineficient.
Version: 0.2
License: GPL
Last update: 2007-12-01
Web site:
[http://
trac.
loria.
fr/
projects/
hyloban]
Documentation:
[http://
trac.
loria.
fr/
projects/
hyloban]
Authors: Carlos Areces, Guillaume Hoffmann, Dmitry Sustretov
Contact: Guillaume Hoffmann
hGEN, a Random Formula Generator
hGen is a random CNF (conjunctive normal form) generator of formulas for sublanguages of H(@,
, A, P). It is an extension of the latest proposal of Patel-Schneider and Sebastiane, nowadays considered the standard testing environment for classical modal logics. The random
generator is used for assessing the performance of different provers.
Version: 1.1
License: GPL
Last update: 2007-12-01
Web site:
[http://
trac.
loria.
fr/
projects/
hgen]
Documentation:
[http://
trac.
loria.
fr/
projects/
hgen]
Authors: Carlos Areces, Daniel Gorín, Juan Heguiabehere and Guillaume Hoffmann
Contact: Carlos Areces
SynLex: Extracting a Syntactical Lexicon from the LADL Tables
Maurice Gross' grammar lexicon contains extremely rich and exhaustive information about the morphosyntactic and semantic properties of French syntactic functors (verbs, adjectives, nouns).
Yet its use within natural language processing systems is still restricted.
The aim of our work is to translate this information into a format which is more suitable for use by NLP systems and also compatible with the state of the art practice in lexical data
representation.
The lexicon should assign to each verb a set of subcategorisation frames. Frames are defined by a list of atoms (e.g., A0 V A1 ) representing the verb and its arguments, and by a list of
atoms/feature structure pairs specifying the feature values associated with each of these atoms.
Two sets of subcategorisation lexicons (called LADL-SynLex and NLP-SynLex) were extracted from the LADL tables. The current SynLex contains the LADL- and NLP-SynLex lexicons for the
LADL-tables 1, 2, 4, 5, 7, 8, 10, 11, 13, 14 and 16 which amounts to roughly 2.000 verb usages. Work is underway to process the remaining available tables which should yield a description of
roughly 6.500 verbs.
SynLex is the result of joint work between TALARIS, ATILF and CALLIGRAMME
[http://
www.
loria.
fr/
~gardent/
ladl].
Last update: 2005-10-14
Web site:
[http://
www.
loria.
fr/
~gardent/
ladl/
]
Documentation:
[http://
www.
loria.
fr/
~gardent/
ladl/
]
Project(s): SynLex
Authors: Claire Gardent, Guy Perrier, Bruno Guillaume, Ingrid Falk
Contact: Claire Gardent
MEDIA
In the framework of the MEDIA project, software has been developed to process transcriptions of a spoken dialogue corpus and to provide a semantic representation of their task-related
content. This software contains a tokeniser, a TAG parser (LLP2), a TAG grammar, an OWL ontology and a set of rules in description logic, and works together with a reasoner such as RACER. The
modularity of its architecture and the use of the Java programming language enable this software to be run on multiple platforms and to be easily adapted to other transactional contexts besides
hotel reservation (it original application domain). This software aims to be further improved to implement reference resolution and dialogic contextual understanding (during the second stage of
the MEDIA project) and eventually to be embedded in dialogue systems.
Version: 0.3
License: GPL
Last update: 08/11/2005
Project(s): MEDIA
Authors and Contact: Alexandre Denis
CURT (Clever Use of Reasoning Tools)
The CURT (Clever Use of Reasoning Tools) family is a series of simple dialogue systems which illustrate how tools for building semantic representations can be combined with inference
tools.
The behaviour of the different CURT programs is as follows: the user extends CURT's knowledge by entering English sentences, and can query it about its acquired knowledge.
The CURT family is composed of Baby CURT (the backbone of the CURT system using no inference services), Rugrat CURT (including either a simple free variable tableau prover or resolution
prover to check the consistency of the current dialog), Clever CURT (which performs consistency checking by running a sophisticated first-order theorem prover and model checker in parallel),
Sensitive CURT (which checks in addition for informativeness of the discourse), Scrupulous CURT (which eliminates equivalent interpretations), Knowledgeable CURT (which adds lexical and world
knowledge) and Helpful CURT (which is able to handle simple natural language questions from the user).
A multilingual version of CURT is being developed (covering French, Romanian and Spanish).
Version: 1.0
License: GPL
Last update: 2005-10-11
Web site:
[http://
www.
comsem.
org]
Documentation:
[http://
www.
comsem.
org]
Authors: Carlos Areces, Patrick Blackburn, Johan Bos, Sébastien Hinderer, Daniela Solomon
Contact: Carlos Areces, Patrick Blackburn, Sébastien Hinderer.
Nessie
Nessie is a library providing facilities for semantic construction. It is written in OCaml and uses typed lambda-calculus and first-order logic as underlying formalisms. It allows the user
to flexibly build terms and term trees; and once a lambda-term tree is built, its semantic representation can be efficiently computed.
For test purposes, this library has been interfaced with CURT's parser.
Future developments of Nessie will include an extension to other logics (modal logic, hybrid logic...), interfaces with French grammars (e.g., those generated by the
XMGsystem), interface with inference tools, etc.
Last update: 2005-10-11
Authors: Sébastien Hinderer
Contact: Sébastien Hinderer
DeDe Corpus
DeDe is a corpus of roughly 50.000 words where around 5.000 definite descriptions have been annotated as coreferential, contextually dependent, non referential or autonomous. The corpus
consists of articles from the newspaper
Le Mondeand is annotated with Multext-based morphosyntactic information
Authors: Claire Gardent, Hélène Manuelian Contact: Claire Gardent
SemFRaG
A TAG grammar developed with the
XMGmetagrammar compiler and which describes both the syntax and the semantics of natural language expressions. Syntactically, the grammars covers the
TSNLP testsuite and work is in progress to acquire an equivalent semantic coverage. Used both for parsing and for generation.
Authors: Claire Gardent, Benoit Crabbé
Contact: Claire Gardent
FRoG — French Resource Grammar
An HPSG grammar of French developed with the LKB platform. The grammar incorporates a treatment of interface phenomena (syntax-semantics, phonology-syntax, morphology-syntax) in a
constraint-based framework designed for bidirectionality (parsing and generation).
Version: 0.1
License: LGPL-LR
Last update: 01/11/2005
Project(s): Delph-In
Authors and Contact: Jesse Tseng
LLP2
LLP2 is an LTAG Parser based on the bottom up algorithm described in Patrice Lopez's thesis. The present version is restricted to TIG. The parser is compliant with the TAGML2 resources
format and is capable of processing a graph of words as input. Furthermore, an external utterance segmenter can be plugged in. The distribution comes with graphical exploration and debugging
tools.
Version: 1.0
Last update: 31/05/2005
Web site:
[http://
www.
loria.
fr/
~azim/
LLP2/
help/
fr/
]
Documentation:
[http://
www.
loria.
fr/
~azim/
LLP2/
help/
fr/
]
Project(s): Passage
Authors and Contact: Azim Roussanaly
New Results
Introduction
To structure our discussion of of the new results for TALARIS in 2007, we shall discuss the four main themes in turn:
Computational Semantics
Discourse, Dialogue and Pragmatics
Logics for Natural Language and Knowledge Representation,
Multilinguality for Multimedia
Computational Semantics
The Computational Semantics group in TALARIS focuses on two main points:
The development of a computational infrastructure for the semantic processing of French
The interfacing of natural language processing (NLP) systems with knowledge based inference
The bulk of the work in these area is led by Claire Gardent, who guides the work of Marilisa Amoia, Paul Bedaride, Ingrid Falk, Eric Kow, Yannick Parmentier, Sylvain Schmitz, and Fabienne
Venant. In addition, Patrick Blackburn and Sébastien Hinderer work on computational semantics (though applications in French are not the focus of their work). Many of the tools produced by
Computational Semantics group are used by other TALARIS researchers, notably from the Discourse, Dialogue and Pragmatics group.
Computational Semantics for French
In 2007, work concentrated mainly on finalising a basic parsing and generating architecture for the semantic processing of French. This involves developing, integrating and evaluating
several modules including: a syntactic lexicon (
SynLeX) and a lexicon for verb synonyms (
Syn2), a grammar (
SemFrag), a module for semantic construction (
SemConst) and a module for surface realisation (
GenI). The computational semantic group also initiated and organised in collaboration with CALLIGRAMME a workshop on
XMG, a grammar writing environmment developed in Nancy.
SynLeX.
A verbal syntactic lexicon lists for each verb the type and the number of its arguments. Such a lexicon is required for any NLP application involving either parsing or generation.
However until recently, no such lexicon was available for French. Over the last three years, TALARIS has worked on extracting such a lexicon from a large scale linguistic resource manually
developed under Maurice Gross' guidance namely, the LADL tables. Although these tables are extremely rich, they cannot directly be used in NLP for two reasons. First, their format does not
fit the requirements of NLP systems and second, much of its information (in particular inter-dependencies) is only implicitly represented. To remedy these shortcomings, we devised a method
to extract the relevant information from these tables and translate it into a format amenable to NLP
Syn2.
To reason about the meaning of text, lexical semantic knowledge is necessary and in particular, knowledge about synonyms (to detect that two sentences carry the same meaning, it is
necessary to be able to detect synonymous words). Together with ATILF, we initiated the MISN CPER operation Syn2 whose aim is to merge 5 synonym dictionaries on the basis of the TLFi
definitions. In a first step, we defined a method based on similarity measures between definitions which permits regrouping synonyms by senses. It remains to be seen how this method
performs on the data. Next we intend to evaluate and compare several variants of the proposed methods wrt a gold standard. Once the best method is identified, a unique synonym lexicon will
be created which assigns a word and its possible meanings, the sets of synonyms corresponding to each given meaning.
SemFrag.
To parse and generate sentences a grammar is required. CALLIGRAMME and TALARIS have been developing over the last 5 years medium size grammars for French using the
XMGgrammar writing environment developed by Denys Duchier, Yannick Parmentier and Joseph LeRoux. The TALARIS grammar
SemFragis a Tree Adjoining Grammar augmented with a unification based compositional semantics. A distinguishing feature of
SemFragis its reversibility: the grammar can be used with a parser to derive the semantic representation of a sentence or conversely, with a
realiser to produce the sentences associated by the grammar with a given meaning. In
SemConst.
To derive semantic representations from sentences, we use
SemFragtogether with Eric de la Clergerie's TAG parser and a semantic construction module implemented by Claire Gardent. The module is available
on the web and was presented both at TALN (the French NLP conference) and at ACL (Association for Computational Linguistics)
GenI.
The surface realiser
GenItakes as input
SemFragand a semantic representation and produces as output the set of strings associated by the grammar with the input semantic representation.
In
XMG workshop.
The
XMGgrammar writing environment was developed by Denys Duchier, Yannick Parmentier and Joseph LeRoux in 2006 and is now used by a medium size
international (France, Germany, Israel, USA) community. To assess the needs of the users and better plan further extensions, TALARIS and CALLIGRAMME organised a 2 day workshop in Nancy
[http://
www.
loria.
fr/
~parmenti/
WSP-XMG/
]which gathered 31 participants from 4 countries and 12 distinct institutions. The workshop resulted in a number of changes to
XMGincluding the addition of a graphical interface for visualising and manipulating an
XMGhierarchy and the adaptation of the framework to Multi Components Tree Adjoining Grammars
NLP and Inference
Work on inference has concentrated on textual entailment recognition for English.
Discourse, Dialogue and Pragmatics
The Discourse, Dialogue and Pragmatics group in TALARIS focuses on two main themes:
The study of grounding, mutual understanding, and collaboration.
The study of presupposition and information accommodation for a planning-based perspective.
The bulk of the work in this area is conducted by Matthieu Quignard, Patrick Blackburn, Alexandre Denis, Luciana Benotti, Daniel Coulon and Carlos Areces. The group is making increasingly
heavy use of the tools provided by the Computational Semantics group (notably the
GenIgenerator,
XMGbased grammars, and the
SemConstgrammar constructor), a trend that is likely to continue. In addition, the group is making increasing use of a inference tools, which leads to
links with the themes explored by the the Logics for Natural Language and Knowledge Representation group. Indeed, this is as it should. Linguistics have long viewed pragmatics, the study of how
natural languages are actually used, as providing an insight into a level of meaning over an above (though mediated by) the meanings provided by pragmatics. And, crucially, this level of
meaning crucially involves inference. Thus, in a sense this group provides a bridge between the semantically and logically oriented work of the other themes.
Grounding and Mutual Understanding
One of the most difficult problems in discourse is guaranteeing mutual understanding. Early AI approaches to dialog (that is, work from the 1970s and 1980s) tended to ignore the problem:
such models assumed perfect understanding or had very crude models of repair.
From a theoretical perspective such approaches are very bad. Dialog is essentially one long mutual effort at negotiating and checking understanding. Moreover, from a practical perspective
such a model leads to inflexible dialogue systems.
One of the successes of the group this year was to propose a detailed computational model of the process of
grounding, that is, the exchange of signals that takes place during the process of accepting/rejecting dialog information
This model has now been implemented, and forms part of the ongoing work by Alexander Denis and Matthieu Quignard on obtaining a detailed computational model of dialog suitable for
implementing robust dialogue systems — one of the long term goals of the group.
Presupposition and Information Accommodation
A pervasive feature of the way we use natural language is the heavy use made of inference to smooth the process on communication. We don't have to spell everything out: we rely on the fact
that the people we talk with have lots of knowledge and experience that lets them find their way to the correct interpretation.
For example, when giving people instructions, we typically don't give all the details: if we ask someone to make a salad, we typically don't tell them that they should wash the lettuce as
a part of this process. We rely on the fact that people can successfully “fill in” such tacit actions. The study of such linguistic inferences belongs to the area known as pragmatics, and in
particular, the study of presupposition and accommodation.
An explicit computational model of part of this process was given by Luciana Benotti
This work is currently being extended by Luciana Benotti and Patrick Blackburn. A reimplementation, called Frolog, of this system is nearing completion. This reimplementation allows all
language processing and inference and planning tasks to be handed over to external modules so that the ideas can be applied in more sophisticated settings.
Logics for Natural Language and Knowledge Representation
The Logics for Natural Language and Knowledge representation focuses on two main points:
The theoretical study of hybrid logic (propositional, first-order, and higher-order) and the implementation of efficient proof methods for them.
Investigating other logics of relevance to natural language and knowledge representation, notably description logic, dedicated planning methods, and discourse
representation theory (DRT).
The bulk of the work in this area is conducted by Carlos Areces, Patrick Blackburn, Dmitry Sustretov, Guillaume Hoffmann, Daniel Gorín and Sergio Mera. The inference methods studied by this
group are relevant to the work of the Computational Semantics group and the Discourse, Dialogue and Pragmatics group, in particular the work of Luciana Benotti on presupposition and information
accomodation (which makes heavy used of description logic and planning) and Paul Bedaride's work on textual entailment (which explores the use of description and hybrid logics).
Automated Theorem Proving for Hybrid Logics
During 2007, this topic received an important impulse. On the one hand,
HyLoRes, the resolution based theorem prover for hybrid logics, has finally arrived to a very stable stage of developement. Important work has been
done during this year, on modularization, testing and performance improving. A graphical interface has been developed, and model generation capabilities included. More importantly, we have
started working in the two topics which we want to address during the next year: paralelization and moving into a client-server architecture. We will discuss these two topics in more detail
below.
Taking advantage of the modularized code of
HyLoRes, the second important result of 2007 was the development of
HTab, a tableaux based prover for hybrid logics
 exists,
HTabhas a number of particularities that make it a potentially useful tool. It has already outperformed HyLoTab
exists,
HTabhas a number of particularities that make it a potentially useful tool. It has already outperformed HyLoTab
After our experience in designing and developing
HyLoResand
HTab, we are currently in the process of drawing the main lines of a new system that we call
InToHyLo.
InToHyLois actually an integrated collection of tools that work in collaboration to offer a varied spectrum of inference services for different
hybrid logics. The system will be developed under the GPL licence and the source code will be available on-line. In addition to the core inference tools, we will also make available the
testing environment used to test
InToHyLooptimizations and heuristics, in order to encourage independent development.
The main inference task addressed by
InToHyLowill be satisfiability checking, but the system will also be able to offer more varied and complex services, like model generation, model
checking and instance retrieval. Initially,
InToHyLowill be created from the integration of
HyLoResand
HTab, and this is what we are going to discuss in detail below. But in the future we will consider the addition of other tools (like the
HyLoBan
The core idea behind
InToHyLois to take advantage of the inherent dual behavior existing between the resolution based and the tableaux based calculi: while the
resolution method performs better on unsatisfiable formulas (during resolution we only need to derive the empty clause to detect that a formula is unsatisfiable), the tableau method performs
better on satisfiable formulas (while constructing a tableau we only need to find a saturated open branch to detect that a formula is satisfiable).
We have already tested this intuition empirically: there are satisfiable formulas for which even the current version of
HTab(with only minimal optimizations) beats
HyLoRes, even though
HyLoResis on average far better performing than
HTab, see
Our first step will be to transform
HyLoResand
HTabinto server applications, while
HyLoRunwill act as a client application which will connect to the provers submitting queries and displaying the results.
HyLoRunwill detect whether
HyLoResand/or
HTabare running as servers and connect to them using either HTTP or TCP services. This architecture is the one used by the description logic prover
RACERand we believe that it has some important benefits:
To start with, the different components of
InToHyLo(currently, the two provers and the front-end) can evolve independently without interfering with applications making use of them, as
long as the communication protocols are maintained. In addition, new inference tools can be added as additional servers and only the front-end will need to be modified to offer these
additional services.
Secondly, and as we will further explain later, we want to investigate ways in which the two provers can collaborate while working in a given problem. With this idea in
mind, we want the provers to be able to exchange information (i.e., partial results) in a manner that is transparent to the user.
But the most important reason for choosing this architecture is that it lets us implement a notion of `proof state'. This idea is again a fundamental characteristic of
DL provers like
RACER: the user should be able to `load' a problem into the system, and then query it for answers. Perhaps many different queries will be posed to the prover about the same
problem, and the prover can take advantage of previous results to answer future queries.
As an example, let us discuss points (2) and (3) above for the case of
HyLoRes. With respect to point (2), given an input formula
 , during the computation of the saturated set of clauses corresponding to
,
HyLoRescan derive unit clauses which can be used by
HTabto close branches. Similarly, formulas which are common to all branches in a tableaux which is being constructed by
HTab, can be sent as unit clauses to be used by
HyLoRes. This idea is intuitively appealing, but care must be taken in coordinating the way that new nominals (which are used both by
HyLoResand
HTabto decompose modal formulas into simpler cases) are introduced.
, during the computation of the saturated set of clauses corresponding to
,
HyLoRescan derive unit clauses which can be used by
HTabto close branches. Similarly, formulas which are common to all branches in a tableaux which is being constructed by
HTab, can be sent as unit clauses to be used by
HyLoRes. This idea is intuitively appealing, but care must be taken in coordinating the way that new nominals (which are used both by
HyLoResand
HTabto decompose modal formulas into simpler cases) are introduced.
With respect to point (3), consider a formula
and suppose that we want to decide whether
 for formulas
for formulas
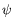 1, ...,
1, ...,
n. With the current version of
HyLoRes, we can only check formulas
 for satisfiability one by one, reporting that
everytime that the prover finds an inconsistency. In doing this, we are recomputing time and again the saturated set for
. It would be much more efficient to first load the formula
into
HyLoResas our current problem, and then send the queries
for satisfiability one by one, reporting that
everytime that the prover finds an inconsistency. In doing this, we are recomputing time and again the saturated set for
. It would be much more efficient to first load the formula
into
HyLoResas our current problem, and then send the queries
ione by one.
HyLoReswould then be able to compute only once the saturated set for
, and just expand it as necessary for each query
i.
Higher Order Hybrid Logics
Higher Order Logics is a classical formalism for natural language semantics semantics. In previous years, we have investigated how the addition of hybrid operators in the classical
framework of higher order logics can improve langauge modelling
This year we have taken up again this issue and we are currently working in a sound and complete axiomatization for higher order hybrid logics. We expect to obtain a general completeness
result (i.e., covering extensions of the basic axiomatization with pure formulas and existential saturation rules) as it is the case for first-order hybrid logics. Such a result would be of
interesting when providing semantics for different natural language phenomena (e.g., time and aspect) which assume special conditions on their formal models.
Multilinguality for Multimedia
Work in this domain is primarily carried out by Samuel Cruz-Lara, Nadia Bellelem, and Lotfi Bellelem. This is the most applied part of the TALARIS team and also the most independent. Their
work centers around:
MLIF (the Multi Lingual Information Framework) a generic ISO-based mechanism for representing and dealing with multilingual textual information.
The W3C's SMIL (Synchronized Multimedia Integration Language), which allows an author to describe the temporal behaviour of a multi-media presentation.
This has been a transitional year for the group. The group was responsible for the PASSEPARTOUT project in interactive television which came (very successfully) to an end on the 31 May 2007.
Since then the group has been involved in developing a number of research proposals though at the time of writing it was unclear whether these had been successful or not. One of the most
interesting of these is the BIONORM project. This is the name of a regional project whose main objective is to develop and to test a platform allowing to manipulate in a standard and
interoperable way, several results related to biological examinations published by biological medical laboratories.
In order to help the group achieve its goals, TALARIS recently expanded it: Lotfi Bellalem joined TALARIS in 30 September 2007. With the group thus increased in size, it is hoped that the
following years will see a closer integration of their work in the mainstream of TALARIS research. It is also possible that Samuel Cruz-Lara will request temporary attachment to INRIA to aid
this process.