Scientific Foundations
Motion estimation and motion segmentation with MRF models
Assumptions (i.e., data models) must be formulated to relate the observed image intensities to motion, and other constraints (i.e., motion models) must be added to solve problems like
motion segmentation, optical flow computation, or motion recognition. The motion models are supposed to capture known, expected or learned properties of the motion field ; this implies
to somehow introduce spatial coherence or more generally contextual information. The latter can be formalized in a probabilistic way with local conditional densities as in Markov models. It
can also rely on predefined spatial supports (e.g., blocks or pre-segmented regions). The classic mathematical expressions associated with the visual motion information are of two types. Some
are continuous variables to represent velocity vectors or parametric motion models. The others are discrete variables or symbolic labels to code motion detection (binary labels), motion
segmentation (numbers of the motion regions or layers) or motion recognition output (motion class labels).
In the past years, we have addressed several important issues related to visual motion analysis, in particular with a focus on the type of motion information to be estimated and the way
contextual information is expressed and exploited. Assumptions (i.e., data models) must be formulated to relate the observed image intensities to motion, and other constraints (i.e., motion
models) must be added to solve problems like motion segmentation, optical flow computation, or motion recognition. The motion models are supposed to capture known, expected or learned
properties of the motion field ; this implies to somehow introduce spatial coherence or more generally contextual information. The latter can be formalized in a probabilistic way with
local conditional densities as in Markov models. It can also rely on predefined spatial supports (e.g., blocks or pre-segmented regions). The classic mathematical expressions associated with
the visual motion information are of two types. Some are continuous variables to represent velocity vectors or parametric motion models. The others are discrete variables or symbolic labels to
code motion detection (binary labels), motion segmentation (numbers of the motion regions or layers) or motion recognition output (motion class labels). We have also recently introduced new
models, called mixed-state models and mixed-state auto-models, whose variables belong to a domain formed by the union of discrete and continuous values. We briefly describe here how such models
can be specified and exploited in two central motion analysis issues: motion segmentation and motion estimation.
The brightness constancy assumption along the trajectory of a moving point
p(
t)in the image plane, with
p(
t) = (
x(
t),
y(
t)), can be expressed as
dI(
x(
t),
y(
t),
t)/
dt= 0, with
Idenoting the image intensity function. By applying the chain rule, we get the well-known motion constraint equation:

where
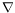
Idenotes the spatial gradient of the intensity, with
I= (
Ix,
Iy), and
Itits partial temporal derivative. The above equation can be straightforwardly extended to the case where a parametric motion model is considered, and we can write:

where
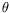 denotes the vector of motion model parameters.
denotes the vector of motion model parameters.
One important step ahead in solving the motion segmentation problem was to formulate the motion segmentation problem as a statistical contextual labeling problem or in other words as a
discrete Bayesian inference problem. Segmenting the moving objects is then equivalent to assigning the proper (symbolic) label (i.e., the region number) to each pixel in the image. The
advantages are mainly two-fold. Determining the support of each region is then implicit and easy to handle: it merely results from extracting the connected components of pixels with the same
label. Introducing spatial coherence can be straightforwardly (and locally) expressed by exploiting
mrfmodels. Here, by motion segmentation, we mean the competitive partitioning of the image into motion-based homogeneous regions. Formally, we have to
determine the hidden discrete motion variables (i.e., region numbers)
l(
i)where
idenotes a site (usually, a pixel of the image grid; it could be also an elementary block). Let
l= {
l(
i),
i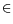
S}. Each label
l(
i)takes its value in the set
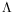 = {1, ..,
= {1, ..,
Nreg}where
Nregis also unknown. Moreover, the motion of each region is represented by a motion model (usually, a 2
daffine motion model of parameters
which have to be conjointly estimated; we have also explored non-parametric motion modeling
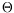 = {
= {
k,
k= 1, ..,
Nreg}. The data model of relation (
Ewhose expression can be written in the general following form:
![Im3 ${E{(l,\#920 ,N_{reg})}=\munder \#8721 {i\#8712 S}\#961 _1{[r_\#952 _{l(i)}{(i)}]}+\munder \#8721 {i\#8764 j}\#961 _2{[l{(i)},l{(j)}]}~,}$](math_image_3.png)
where
 designates a two-site clique. We first considered
designates a two-site clique. We first considered
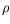 1(
1(
x) =
x2for the data-driven term in (
Ewas carried out on
land
in an iterative alternate way, and the number of regions
Nregwas determined by introducing an extraneous label and using an appropriate statistical test. We later chose a robust estimator for
1
Specifying (simple)
mrfmodels at a pixel level (i.e., sites are pixels and a 4- or 8-neighbor system is considered) is efficient, but remains limited to express more
sophisticated properties on region geometry or to handle extended spatial interaction. Multigrid
mrfmodels
By definition, the velocity field formed by continuous vector variables is a complete representation of the motion information. Computing optical flow based on the data model of equation (
 can be given by:
can be given by:
![Im6 ${E{(\#119856 ,\#950 )}=\munder \#8721 {p\#8712 S}\#961 _1{[r{(p)}]}~+\munder \#8721 {p\#8764 q}\#961 ... 56 {(q)}\#8741 ,\#950 }{(p_{p\#8764 q}^')}{]+}\munder \#8721 {A\#8712 \#967 }\#961 _3{(\#950 _A)}~,}$](math_image_6.png)
where
Sdesignates the set of pixel sites,
r(
p)is defined in (
S'= {
p'}the set of discontinuity sites located midway between the pixel sites and
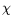 is the set of cliques associated with the neighborhood system chosen on
is the set of cliques associated with the neighborhood system chosen on
S'. We first used quadratic functions and the motion discontinuities were handled by introducing a binary line process
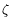
 can be optional.
can be optional.
Fluid motion analysis
Analyzing fluid motion is essential in number of domains and can rarely be handled using generic computer vision techniques. In this particular application context, we study several
distinct problems. We first focus on the estimation of dense velocity maps from image sequences. Fluid flows velocities cannot be represented by a single parametric model and must generally
be described by accurate dense velocity fields in order to recover the important flow structures at different scales. Nevertheless, in contrast to standard motion estimation approach, adapted
data model and higher order regularization are required in order to incorporate suitable physical constraints. In a second step, analyzing such velocity fields is also a source of concern.
When one wants to detect particular events, to segment meaningful areas, or to track characteristic structures, dedicated methods must be devised and studied.
Since several years, the analysis of video sequences showing the evolution of fluid phenomena has attracted a great deal of attention from the computer vision community. The applications
concern domains such as experimental visualization in fluid mechanics, environmental sciences (oceanography, meteorology, ...), or medical imagery.
In all these application domains, it is of primary interest to measure the instantaneous velocity of fluid particles. In oceanography, one is interested to track sea streams and to observe
the drift of some passive entities. In meteorology, both at operational and research levels, the task under consideration is the reconstruction of wind fields from the displacements of clouds
as observed in various satellite images. In medical imaging, the issue can be to visualize and analyze blood flow inside the heart, or inside blood vessels. The images involved in each domain
have their own characteristics and are provided by very different sensors. The huge amount of data of different kinds available, the range of applicative domains involved, and the technical
difficulties in the processing of all these specific image sequences explain the interest of the image analysis community.
Extracting dense velocity fields from fluid images can rarely be done with the standard computer vision tools. The latter were originally designed for quasi-rigid motions with stable salient
features, even if these techniques have proved to be more and more efficient and provide accurate results for natural images
 ), along with the spatial smoothness assumption of the motion field. These estimators are defined as the minimizer of the following energy function:
), along with the spatial smoothness assumption of the motion field. These estimators are defined as the minimizer of the following energy function:
![Im9 ${\#8747 _\#937 \#961 {[\#8711 f·w+\mfrac {\#8706 f}{\#8706 t}]}d\#119852 +\#945 \#8747 _\#937 \#961 {(\#8741 \#8711 w\#8741 )}d\#119852 .}$](math_image_9.png)
The penalty function
is usually the
L2norm, but it may be substituted for a robust function attenuating the effect of data that deviate significantly from the brightness constancy assumption
Contrary to usual video image sequence contents, fluid images exhibit high spatial and temporal distortions of the luminance patterns. The design of alternative approaches dedicated to fluid
motion thus constitutes a widely-open research problem. It requires to introduce some physically relevant constraints which must be embedded in a higher-order regularization functional

The first term comes from an integration of the continuity equation (assuming the velocity of a point is constant between instants
tand
t+
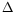
t). Such a data model is a “fluid counterpart” of the usual “Displaced Frame Difference” expression. Instead of expressing brightness constancy, it explains a loss or
gain of luminance due to a diverging motion. The second term is a smoothness term designed to preserve divergence and vorticity blobs. This regularization term is nevertheless very difficult to
implement. As a matter of fact, the associated Euler-Lagrange equations consist in two fourth-order coupled
pde's, which are tricky to solve numerically. We proposed to simplify the problem by introducing auxiliary functions, and by defining the following
alternate smoothness function:

The new auxiliary scalar functions
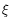 and
can be respectively seen as estimates of the divergence and the curl of the unknown motion field, and
and
can be respectively seen as estimates of the divergence and the curl of the unknown motion field, and
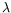 is a positive parameter. The first part of each integral enforces the displacement to comply with the current divergence and vorticity estimates
and
, through a quadratic goodness-of-fit enforcement. The second part associates the divergence and the vorticity estimates with a robust first-order regularization enforcing piece-wise
smooth configurations. From a computational point of view, such a regularizing function only implies the numerical resolution of first-order
pde's. It may be shown that, at least for the
is a positive parameter. The first part of each integral enforces the displacement to comply with the current divergence and vorticity estimates
and
, through a quadratic goodness-of-fit enforcement. The second part associates the divergence and the vorticity estimates with a robust first-order regularization enforcing piece-wise
smooth configurations. From a computational point of view, such a regularizing function only implies the numerical resolution of first-order
pde's. It may be shown that, at least for the
L2norm, the regularization we proposed is a smoothed version of the original second-order div-curl regularization.
Once given a reliable description of the fluid motion, another important issue consists in extracting and characterizing structures of interest such as singular points or in deriving
potential functions. The knowledge of the singular points is precious to understand and predict the considered flows, but it also provides compact and hierarchical representations of the flow
Object tracking with non-linear probabilistic filtering
Tracking problems that arise in target motion analysis (
tma
) and video analysis are highly non-linear and multi-modal, which precludes the use of Kalman filter and its classic variants. A powerful way to address this class of difficult filtering
problems has become increasingly successful in the last ten years. It relies on sequential Monte Carlo (
smc
) approximations and on importance sampling. The resulting sample-based filters, also called particle filters, can, in theory, accommodate any kind of dynamical models and observation
models, and permit an efficient tracking even in high dimensional state spaces. In practice, there is however a number of issues to address when it comes to difficult tracking problems such
as long-term visual tracking under drastic appearance changes, or multi-object tracking.
The detection and tracking of single or multiple targets is a problem that arises in a wide variety of contexts. Examples include sonar or radar
tmaand visual tracking of objects in videos for a number of applications (e.g., visual servoing, tele-surveillance, video editing, annotation and
search). The most commonly used framework for tracking is that of Bayesian sequential estimation. This framework is probabilistic in nature, and thus facilitates the modeling of uncertainties
due to inaccurate models, sensor errors, environmental noise, etc. The general recursions update the posterior distribution of the target state
 , also known as the filtering distribution, where
, also known as the filtering distribution, where
 denotes all the observations up to the current time step, through two stages:
denotes all the observations up to the current time step, through two stages:

where the prediction step follows from marginalization, and the new filtering distribution is obtained through a direct application of Bayes' rule. The recursion requires the
specification of a dynamic model describing the state evolution
 , and a model for the state likelihood in the light of the current measurements
, and a model for the state likelihood in the light of the current measurements
 . The recursion is initialized with some distribution for the initial state
. The recursion is initialized with some distribution for the initial state
 . Once the sequence of filtering distributions is known, point estimates of the state can be obtained according to any appropriate loss function, leading to, e.g., Maximum
A Posteriori(
map) and Minimum Mean Square Error (
mmse) estimates.
. Once the sequence of filtering distributions is known, point estimates of the state can be obtained according to any appropriate loss function, leading to, e.g., Maximum
A Posteriori(
map) and Minimum Mean Square Error (
mmse) estimates.
The tracking recursion yields closed-form expressions in only a small number of cases. The most well-known of these is the Kalman Filter (
kf) for linear and Gaussian dynamic and likelihood models. For general non-linear and non-Gaussian models the tracking recursion becomes analytically
intractable, and approximation techniques are required. Sequential Monte Carlo (
smc) methods
The basic idea behind particle filters is very simple. Starting with a weighted set of samples
 approximately distributed according to
approximately distributed according to
 , new samples are generated from a suitably designed proposal distribution, which may depend on the old state and the new measurements, i.e.,
, new samples are generated from a suitably designed proposal distribution, which may depend on the old state and the new measurements, i.e.,
 ,
,
 . Importance sampling theory indicates that a consistent sample is maintained by setting the new importance weights to
. Importance sampling theory indicates that a consistent sample is maintained by setting the new importance weights to

where the proportionality is up to a normalizing constant. The new particle set
 is then approximately distributed according to
. Approximations to the desired point estimates can then be obtained by Monte Carlo techniques. From time to time it is necessary to resample the particles to avoid degeneracy of the
importance weights. The resampling procedure essentially multiplies particles with high importance weights, and discards those with low importance weights.
is then approximately distributed according to
. Approximations to the desired point estimates can then be obtained by Monte Carlo techniques. From time to time it is necessary to resample the particles to avoid degeneracy of the
importance weights. The resampling procedure essentially multiplies particles with high importance weights, and discards those with low importance weights.
In many applications, the filtering distribution is highly non-linear and multi-modal due to the way the data relate to the hidden state through the observation model. Indeed, at the heart
of these models usually lies a data association component that specifies which part, if any, of the whole current data set is “explained” by the hidden state. This association can be implicit,
like in many instances of visual tracking where the state specifies a region of the image plane. The data, e.g., raw color values or more elaborate descriptors, associated to this region only
are then explained by the appearance model of the tracked entity. In case measurements are the sparse outputs of some detectors, as with edgels in images or bearings in
tma, associations variables are added to the state space, whose role is to specify which datum relates to which target (or clutter).
In this large context of
smctracking techniques, two sets of important open problems are of particular interest for Vista:
selection and on-line estimation of observation models with multiple data modalities: except in cases where detailed prior is available on state dynamics (e.g., in a
number of
tmaapplications), the observation model is the most crucial modeling component. A sophisticated filtering machinery will not be able to compensate
for a weak observation model (insufficiently discriminant and/or insufficiently complete). In most adverse situations, a combination of different data modalities is necessary. Such a fusion
is naturally allowed by
smc, which can accommodate any kind of data model. However, there is no general means to select the best combination of features, and, even more
importantly, to adapt online the parameters of the observation models associated to these features. The first problem is a difficult instance of discriminative learning with heterogeneous
inputs. The second problem is one of online parameter estimation, with the additional difficulty that the estimation should be mobilized only parsimoniously in time, at instants that must
be automatically determined (adaptation when the entities are momentarily invisible or simply not detected by the sensors will always cause losses of track). These problems of feature
selection, online model estimation, and data fusion, have started to receive a great deal of attention in the visual tracking community, but proposed tools remain ad-hoc and restricted to
specific cases.
multiple-object tracking with data association: when tracking jointly multiple objects, data association rapidly poses combinatorial problem. Indeed, the observation
model takes the form of a mixture with a large number components indexed by the set of all admissible associations (whose enumeration can be very expensive). Alternatively, the association
variables can be incorporated within the state space, instead of being marginalized out. In this case, the observation model takes a simpler product form, but at the expense of a dramatic
dimension increase of the space in which the estimation must be conducted.
In any case, strategies have thus to be designed to keep low the complexity of the multi-object tracking procedure. This need is especially acute when
smctechniques, already often expensive for a single object, are required. One class of approach consists in devising efficient variants of
particle filters in the high-dimensional product state space of joint target hypotheses. Efficiency can be achieved, to some extent, by designing layered proposal distributions in the
compound target-association state space, or by marginalizing out approximately the association variables. Another set of approaches lies in a crude, yet very effective approximation of the
joint posterior over the product state space into a product of individual posteriors, one per object. This principle, stemming from the popular
jpdaf(joint probabilistic data association filter) of the trajectography community, is amenable to
smcapproximation. The respective merits of these different approaches are still partly unclear, and are likely to vary dramatically from one
context to another. Thorough comparisons and continued investigation of new alternatives are still necessary.
Software
Motion2
dsoftware - parametric motion model estimation
Fabien
Spindler (Lagadic team)
Patrick
Bouthemy
Motion2
dis a multi-platform object-oriented library to estimate 2
dparametric motion models in an image sequence. It can handle several types of motion models, namely, constant (translation), affine, and quadratic
models. Moreover, it includes the possibility of accounting for a global variation of illumination. The use of such motion models has been proved adequate and efficient for solving problems
such as optic flow computation, motion segmentation, detection of independent moving objects, object tracking, or camera motion estimation, and in numerous application domains, such as dynamic
scene analysis, video surveillance, visual servoing for robots, video coding, or video indexing. Motion2
dis an extended and optimized implementation of the robust, multi-resolution and incremental estimation method (exploiting only the spatio-temporal
derivatives of the image intensity function) we defined several years ago
Motion2
dFree Edition is the version of Motion2
davailable for development of Free and Open Source software only (no commercial use). It is provided free of charge under the terms of the
qPublic License. It includes the source code and makefiles for Linux, Solaris, SunOS, and Irix. The latest version (last release 1.3.11, January
2005) is available for download.
Motion2
dProfessional Edition provided for commercial software development. This version also supports Windows 95/98 and
nt.
More information on Motion2
dcan be found at
[http://
www.
irisa.
fr/
vista/
Motion2D]and the software can be donwloaded at the same Web address.
d-Change software - motion detection
Fabien
Spindler (Lagadic team)
Patrick
Bouthemy
d-change is a multi-platform object-oriented software to detect mobile objects in an image sequence acquired by a static camera. It includes two
versions : the first one relies on Markov models and supplies a pixel-based binary labeling, the other one introduces rectangular models enclosing the mobile regions to be detected. It
simultaneously exploits temporal differences between two successive images of the sequence and differences between the current image and a reference image of the scene without any mobile
objects (this reference image is updated on line). The algorithm provides the masks of the mobile objects (mobile object areas or enclosing rectangles according to the considered version) as
well as region labels enabling to follow each region over the sequence.
DenseMotion software - Estimation of 2D dense motion fields
Thomas
Corpetti
Patrick
Heas
Etienne
Mémin
This code allows the computation from two consecutive images of a dense motion field. The estimator is expressed as a global energy function minimization. The code enables the choice of
different data model and different regularization functional depending on the targeted application. Generic motion estimator for video sequences or dedicated motion estimator for fluid flows
can be specified. This estimator allows in addition the users to specify additional correlation based matching measurements. It enables also the inclusion of a temporal smoothing prior relying
on a velocity vorticity formulation of the Navier-Stoke equation for Fluid motion analysis applications. The different variants of this code correspond to research studies that have been
published in IEEE transaction on Pattern Analysis and machine Intelligence, Experiments in Fluids, IEEE transaction on Image Processing, IEEE transaction on Geo-Science end Remote Sensing. The
binary of this code can be freely downloaded on the
fluidweb site
[http://
fluid.
irisa.
fr].
2DLayeredMotion software - Estimation of 2D independent mesoscale layered atmospheric motion fields
Patrick
Heas
Etienne
Mémin
Nicolas
Papadakis
This software enables to estimate a stack of 2D horizontal wind fields corresponding to a mesoscale dynamics of atmospheric pressure layers. This estimator is formulated as the minimization
of a global energy function. It relies on a vertical decomposition of the atmosphere into pressure layers. This estimator uses pressure data and classification clouds maps and top of clouds
pressure maps (or infra-red images). All these images are routinely supplied by the EUMETSAT consortium which handles the Meteosat and MSG satellite data distribution. The energy function
relies on a data model built from the integration of the mass conservation on each layer. The estimator also includes a simplified and filtered shallow water dynamical model as temporal
smoother and second-order div-curl spatial regularizer. The estimator may also incorporate correlation-based vector fields as additional observations. These correlation vectors are also
routinely provided by the Eumetsat consortium. This code corresponds to research studies published in IEEE transaction on Geo-Science and Remote Sensing. It can be freely downloaded on the
fluidweb site
[http://
fluid.
irisa.
fr].
3DLayeredMotion software - Estimation of 3D interconnected layered atmospheric motion fields
Patrick
Heas
Etienne
Mémin
This software extends the previous 2D version. It allows (for the first time to our knowledge) the recovery of 3D wind fields from satellite image sequences. As with the previous techniques,
the atmosphere is decomposed into a stack of pressure layers. The estimation relies also on pressure data and classification clouds maps and top of clouds pressure maps. In order to recover the
3D missing velocity information, physical knowledge on 3D mass exchanges between layers has been introduced in the data model. The corresponding data model appears to be a generalization of the
previous data model constructed from a vertical integration of the continuity equation. This research study has been recently accepted for publication in IEEE trans. on Geo-Science and Remote
Sensing. A detailed description of the technique can be found in an Inria research report. The binary of this code can be freely downloaded on the
fluidweb site
[http://
fluid.
irisa.
fr].
Low-Order-Motion - Estimation of low order representation of fluid motion
Anne
Cuzol
Nicolas
Gengembre
Etienne
Mémin
This code enables the estimation of a low order representation of a fluid motion field from two consecutive images.The fluid motion representation is obtained using a discretization of the
vorticity and divergence maps through regularized Dirac measure. The irrotational and solenoidal components of the motion fields are expressed as linear combinations of basis functions obtained
through the Biot-Savart law. The coefficient values and the basis function parameters are obtained as the minimizer of a functional relying on an intensity variation model obtained from an
integrated version of the mass conservation principle of fluid mechanics. Different versions of this estimation are available. The code which includes a Matlab user interface can be downloaded
on the
fluidweb site
[http://
fluid.
irisa.
fr]. This program corresponds to a research study that has been published in the International Journal on computer Vision.
VTrack software - generic interactive visual tracking platform
Nicolas
Gengembre
Patrick
Pérez
As part of a past research contract with
ft-rd, we have developed an interactive tracking platform (Windows Visual
c++ development with Microsoft
mfcand Intel Open
cv). It includes both state-of-the-art generic tracking methods (template matching, feature tracking, kernel-based tracking with global color
characterization, particle filtering) and original developments, as well as a number of visualization features for enhanced experimental and demonstration experiences. The flexible architecture
and the rich
hciallow easy design, implementation and test of novel trackers.
ObjectDet software - learning and detection of visual object classes
Ivan
Laptev
ObjectDet is an open source efficient
c++implementation of object detection that extends our previous method
Earlier version of the software with pre-trained classifiers is available for download from
[http://
www.
irisa.
fr/
vista/
Equipe/
People/
Laptev/
download.
html]. An updated release including the module for object training is planed to be made available before the end of 2007. Linux and Windows platforms are supported.
SAFIR-nD - image denoising software
Charles
Kervrann
Jérôme
Boulanger
The
safir-n
dsoftware written in
c++,
javaand
matlab, enables to remove additive Gaussian and non-Gaussian noise in a still 2
dor 3
dimage or in a 2
dor 3
dimage sequence (with no motion computation). The method is unsupervised. It is based on a pointwise selection of small image patches of fixed size in
(a data-driven adapted) spatial or space-time neighborhood of each pixel (or voxel). The main idea is to associate with each pixel (or voxel) the weighted sum of intensities within an adaptive
2
dor 3
d(or 2
dor 3
d+ time) neighborhood and to use image patches to take into account complex spatial interactions. The neighborhood size is selected at each spatial or
space-time position according to a bias-variance criterion. The algorithm requires no tuning of control parameters (already calibrated with statistical arguments) and no library of image
patches. The method has been applied to real noisy images (old photographs,
jpeg-coded images, videos, ...) and is exploited in different biomedical application domains (fluorescence microscopy, video-microscopy,
mriimagery,
x-ray imagery, ultrasound imagery, ...). This algorithm outperforms most of the best published denoising methods for still images or image
sequences.
FAST-2D-SAFIR software - fast denoising of large 2D images
Charles
Kervrann
The
fast-2
d-
safirsoftware written in
c++ enables to remove mixed Gaussian-Poisson noise in large 2
dimages, typically
10
3×10
3pixels, in few seconds. The method is unsupervised and is a simplified version of the method related to the
safir-n
dsoftware. The method is based on a locally piecewise constant modeling of the image with an adaptive choice of a window around each pixel. The
restoration technique associates with each pixel the weighted sum of data points within the window. The method has been applied to real microarray images routinely used in medical
practices.
Contracts and Grants with Industry
Cifre grant with Thomson-R&D on visual tracking
Patrick
Pérez
Vijay
Badrinarayanan
no. Inria 2029, duration 36 months.
This contract started in March 2006 is associated with the supervision of V. Badrinarayanan's thesis funded by a Cifre grant. It concerns the problem of robust tracking of
arbitrary objects in arbitrary videos. The first goal is the design of novel probabilistic ingredients to improve the robustness of existing tracking tools, with a first contribution on
information-theoretic uncertainty assessment in probabilistic tracking as a generic tool for multiple cue fusion and intermittent adaptation. The second goal concerns the application, and
possibly the specialization, of proposed generic techniques to tasks of interest to Thomson. Two scenarios are especially targeted: blurring of selected objects (typically faces) in
tvnews for business unit Thomson Grass Valley, and object colorization in film post-production for business unit Technicolor. In both cases, robust
tracking tools (tracking a bounding box in the first case and the precise object outline in the second case) allowing the partial automatization of painstaking tasks are sought. Part of the
work already conducted has given rise to the filing of the following European patent: “Method for tracking an object in a sequence of images and device implementing said method” by Vijay. B, P.
Pérez, F. Le Clerc, L. Oisel.
Cifre grant with Thomson-R&D on video inpainting
Patrick
Pérez
Matthieu
Fradet
no. Inria 2210, duration 36 months.
This contract started in March 2007 is associated with the supervision of M. Fradet's thesis funded by a Cifre grant. It concerns the problem of semi-automatic object removal for film
and television post-production. The first goal is, for a given static mask to be filled-in, to design a local motion analysis approach (estimation and segmentation) that allows the
interpolation of motion information within the region and the effective filling of the region based on current and surrounding frames as well as measured and interpolated motion information.
The second step will aim at combining previous tool with tracking tools developed in
CEA-Cesta contract: Target tracking in a dense environment
Jean-Pierre
Le Cadre
Adrien
Ickowicz
no. Inria 1542, duration 7 months.
The aim of the multitarget tracking is to associate elementary measurements corresponding to feasible trajectories. This association step is made jointly with a tracking step and both are
completely entangled. This means that this problem is largely different from classical target tracking. There is fundamentally uncertainty about the origin of the measurements. To solve such
problems, a wide variety of methods are available. Roughly, they can be divided in two categories: the probabilistic methods (e.g.,
jpdaf, pmht), and combinatorial ones. However, a major problem remains for initializing multitarget algorithms. While integer programming or flow
approaches have been developed for solving it rigorously, a basic tool is to limit the arborescence complexity via merging and pruning (the
mht). In contrast to the “elementary” target tracking framework, there is a strong need for defining convenient tool for the performance of data
association. The probability of correct association and the track purity index are sensible tools. In this context, we have shown that a linear regression framework allows us to conduct
explicit calculations. More precisely, the probability of correct association has been derived as an explicit function of the scenario parameters: scan number, mean track distance, measurement
variance, probability of detection, etc. By this way, it is possible to derive a measure of track-to-track interaction. In a dense target environment, the problem becomes still more complicated
since we have to investigate the effects of permutations.
DGA (REI)- contract: dynamic scene analysis with camera networks
Jean-Pierre
Le Cadre
Adrien
Ickowicz
Patrick
Bouthemy
no. Inria 2338, duration: 30 months.
This contract deals with surveillance of large zones via a network of video sensors. Of course, sensor outputs can be treated in a centralized architecture. However, centralized
architectures suffer from serious drawbacks. Communication constraints (e.g. bandwidth) are frequently evoked, but still more fundamentally we have to face many problems inherent of this
architecture, like:
Sensor calibration, positioning and synchronisation.
False alarms, multiple objects, occlusions, etc.
Overall, there is strong need for extracting a global picture at the network level. This means that we have to focuse on the level of information we can extract at the sensor level and how
to fuse them. Work has been done on the first point, using both simulated and real video sequences. The less informative level of information is the binary one. However, there is a fundamental
difference between a
{0, 1}information and
{-, + }information. A "general"
{0, 1}information corresponds to a detection
/non-detection information. Such architecture has been widely studied in a distributed detection framework, but is not well suited to our context. However
{0, 1}information is especially interesting if the detection process includes geographic constraints like proximity, field-of-view, etc. The
{-, + }information corresponds to a motion information: the object gets closer or is going far away. At the network level, this is a very rich information
which can present definite advantages (robustness, multi-target tracking). However, its interest depends on the network density. So, it is also necessary to consider various and complementary
decentralized architectures according to the sensing capabilities, the target behaviors and, overall, the combinatorial complexity of the problem. Work has been done for defining processings
and architectures adapted to this context.
An internship work (André Silva de Oliveira) has been devoted to the processing of image sequences for extracting the binary information. After considering the divergence of a local motion
model, its estimation and use on real data, we turned toward a temporal analysis of the bearing information. More precisely, bearing rates and bearing rate changes give us an estimate of the
(local) target behavior. It is thus possible to derive a local estimate of the ratio
 , through purely passive measurements, at the sensor level. Although this analysis is purely local, it performs satisfactorily on simulated sequences. Its performance has been
investigated and the method appears relatively robust to an imperfect knowledge of the focal length.
, through purely passive measurements, at the sensor level. Although this analysis is purely local, it performs satisfactorily on simulated sequences. Its performance has been
investigated and the method appears relatively robust to an imperfect knowledge of the focal length.
Grant from Dupont De Nemours
Etienne
Mémin
University of Rennes contract, duration 24 months
In 2006, Dupont De Nemours company has provided an excellency unrestricted grant to E. Mémin to support his activities in the field of “Developing computational and visualization
capabilities to extract object motion fields and fluid flow fields from high-speed imaging”.
European initiatives
FP6-IST FLUID
Nicolas
Gengembre
Patrick
Heas
Étienne
Mémin
Nicolas
Papadakis
no. Inria 737, duration 36 months
The
fluidproject is a
fp6
strepsproject labeled in the Future and Emerging Technologies Open scheme program. The goal of this selective Information Society Technologies
program of basic researches is to enable a range of ideas for future and emerging technologies to be explored and realised.
The fluid project has started in November 2004. E. Mémin is the scientific coordinator of the project. This 3-year project aims at studying and developing new methods for the
estimation, the analysis and the description of complex fluid flows from image sequences. The consortium is composed of five academic partners (Inria, Cemagref, University of Mannheim,
University of Las Palmas de Gran Canaria and the
lmd, “Laboratoire de Météorologie Dynamique”) and one industrial partner (La Vision company) specialized in
piv(Particle Image Velocimetry) system. The project gathers computer vision scientists, fluid mechanicians and meteorologists. The first objective
of the project consists in studying novel and efficient methods to estimate and analyze fluid motions from image sequences. The second objective is to guarantee the applicability of the
developed techniques to a large range of experimental fluid visualization applications. To that end, two specific areas are considered: meteorological applications and experimental fluid
mechanics for industrial evaluation and control. From the application point of view, the project particularly focus on 2
dand 3
dwind field estimation, and on 2
dand 3
dparticle image velocimetry. A reliable structured description of the computed fluid flow velocity field will further allow us to address the
tracking of turbulent structures in the flows.
During the third year of this project we have pursue the effort on the design of methodologies that aim at coupling fluid dynamical model and image data. These couplings have been settled
either within a stochastic filtering framework or either within a variational assimilation framework.
Concerning the stochastic filtering, we have defined a filter that allows us to built a bridge between two different sequential Monte-Carlo techniques Ensemble Kalman Filter routinely used
in environmental sciences and the particle filter used in signal and image processing. A very promising technique leading to a gain of robustness for a cheaper computational cost has emerged.
This technique has been assessed on 2D turbulent flows.
As for the variational assimilation framework, we have proposed several schemes that enables the estimation of coherent motion fields with respect to a given dynamical law. This framework
allows the tracking from image sequences of features leaving in space of infinite dimension such as curves and motion.
We have also applied this framework to the estimation of low order dynamical systems. Such a system is obtained through a Galerkin projection of the Navier-Stokes equation on a modal
representation of the flow under concern using a truncated singular value decomposition of the autocorrelation matrix of experimental velocity measurements (Proper Orthogonal Decomposition).
The proposed estimation relies on an optimal control of the initial condition and the coefficient of the unknown dynamical system. This new method appears to be very stable and allows the
estimation of a larger number of modes to represent the flow.
In a meteorological context we have investigated the particular issue of wind fields estimation for a stratified atmosphere into layers. We have also proposed for the very first time
solutions to estimate the vertical component of wind fields from 2D satellite pressure images organized in successive layers.
Cooperations with the Cemagref Rennes and the LMD (Laboratoire de Météorologie Dynamique) have enabled us to assess the relevance of the proposed methods either in the context of
experimental fluid mechanics or for meteorological applications.
FP6 PEGASE: helicoPter and aEronef naviGation Airborne System Experimentation
Patrick
Bouthemy
Jean-Pierre
Le Cadre
no. Inria 1832, duration 36 months
pegaseis a multisciplinary European project involving 15 partners (industrial and academic) gathering the major actors of the domain. It is headed
by Dassault Aviation. The kick-off-meeting was held in October 2006. For civil aviation, it is widely recognized that approaches, landings and take-offs, or more generally, maneuvers or
navigation in the terminal zone, are among the most critical tasks in aircraft operation.
pegaseis a feasibility study of a new navigation system which should allow a three-dimensional truly autonomous approach and guidance for airports
and helipads and improves the integrity and accuracy of
gnssdifferential navigation systems. The purpose of the
pegaseproject is to prepare the development of an autonomous, all weather conditions, localization and guidance system based upon correlation
between vision sensors output and a ground reference database. The work package
wp6 will be led by Inria (Lagadic project-team) and is gathering academic labs (Inria - project-teams Icare, Lagadic and Vista -,
cnrs,
epfl,
ethz,
itjsi) and industrial partners (Dassav,
eads, Euroimage,...). Its aim is to develop new methods in image processing, visual tracking and visual servoing to implement the functionalities
required in the
pegasenavid system, in connection with other
wps. Concurrent image processing methods will be implemented and tested on real image sequences, and synthesized image sequences. Its
kick-off-meeting has been held in Turin (March 2007) and an important work has been done for defining flight models, real image sequences, etc. The Vista team is more specifically involved in
two tasks: the tracking of points of interest on the first hand and the aircraft positioning on the second one. For the second task, inputs are the tracked points of interest and the flight
model is used to have an accurate estimate of the aircraft trajectory.
FP6-IST NEO Muscle
Ivan
Laptev
Patrick
Bouthemy
Alexandre
Hervieu
no. Inria 104A04950, duration 48 months
The Vista team is involved in the
fp6 Network of Excellence
muscle(“Multimedia Understanding through Semantics, Computation and Learning”) started in April 2004. It gathers over forty research groups all over
Europe from public institutes, universities or research labs of companies. Due to the convergence of several strands of scientific and technological progress, one is witnessing the emergence
of unprecedented opportunities for the creation of a knowledge driven society. Indeed, databases are accruing large amounts of complex multimedia documents, networks allow fast and almost
ubiquitous access to an abundance of resources and processors have the computational power to perform sophisticated and demanding algorithms. However, progress is hampered by the sheer amount
and diversity of the available data. As a consequence, access can only be efficient if based directly on content and semantics, the extraction and indexing of which is only feasible if
achieved automatically.
muscleaims at creating and supporting a pan-European Network of Excellence to foster close collaboration between research groups in multimedia
datamining on one hand and machine learning on the other hand, in order to make breakthrough progress toward different objectives.
Vista was a part of the
muscleshowcase project “Content-Based Copy Detection for Videos and Still Images” and provided implementation of space-time interest point detection
for the video copy detection demonstrator. I. Laptev collaborated with
inria-Imedia on the evaluation of methods for video copy detection and published a joint paper. I. Laptev took part in the
muscle“Visual Saliency” e-team collaboration and visited
kthfor one week in Jan. 2007 where he worked on object recognition. P. Bouthemy and I. Laptev organized a special session devoted to
muscleresearch at the International Workshop on Content-based Multimedia Indexing (
cbmi'2006) held in Bordeaux, France, June 2007. Vista contributed to several
wpreports.
FP6-IST TN Visiontrain
Patrick
Bouthemy
Alexandre
Hervieu
no. Inria 850, duration 48 months
Visiontrain is a Marie Curie Research Training Network (belonging to the Computational and Cognitive Vision Systems chapter) which started in May 2005. Visiontrain addresses the
problem of understanding vision from both computational and cognitive points of view. The research approach will be based on formal mathematical models and on the thorough experimental
validation of these models. In order to achieve these ambitious goals, 11 academic partners plan to work cooperatively on a number of targeted research objectives:
(i)computational theories and methods for low-level vision,
(ii)motion understanding from image sequences,
(iii)learning and recognition of shapes, objects, and categories,
(iv)cognitive modeling of the action of seeing, and
(v)functional imaging for observing and modeling brain activity. A. Hervieu and P. Bouthemy participated to the Visiontrain meeting hold in Utrecht in May 2007 where
A. Hervieu gave a talk on “Trajectory-based video event recognition". A. Hervieu and T. Pecot attended the second Visiontrain one-week thematic (winter) school held at Les
Houches Physics School in March 2007 and devoted to “Computational and Neurophysiological Models for Visual Perception”.