Expressive power of models and formalisms for concurrency
Jesus
Aranda
Romain
Beauxis
Diletta Romana
Cacciagrano
Catuscia
Palamidessi
Frank
Valencia
On the Expressive Power of Restriction in CCS with Replication
Busi et al.
In
 is the fragment of CCS
!not allowing restrictions under the scope of a replication.
is the fragment of CCS
!not allowing restrictions under the scope of a replication.
 is the restriction-free fragment of CCS
!. The third variant is
is the restriction-free fragment of CCS
!. The third variant is
 which extends CCS
which extends CCS
 with PhillipÕs priority guards. We have shown that the use of unboundedly many restrictions in CCS
!is necessary for obtaining Turing expressiveness in the sense of Busi et al. We have done this by showing that there is no encoding of RAMs into CCS
which preserves and reflects convergence. We have also proved that up to failures equivalence, there is no encoding from CCS
!into CCS
nor from CCS
into CCS
with PhillipÕs priority guards. We have shown that the use of unboundedly many restrictions in CCS
!is necessary for obtaining Turing expressiveness in the sense of Busi et al. We have done this by showing that there is no encoding of RAMs into CCS
which preserves and reflects convergence. We have also proved that up to failures equivalence, there is no encoding from CCS
!into CCS
nor from CCS
into CCS
 . As lemmata for the above results we have proved that convergence is decidable for CCS
and that language equivalence is decidable for CCS
. As corollary it follows that convergence is decidable for restriction-free CCS. Finally, we have shown the expressive power of priorities by providing an encoding of RAMs in CCS
. As lemmata for the above results we have proved that convergence is decidable for CCS
and that language equivalence is decidable for CCS
. As corollary it follows that convergence is decidable for restriction-free CCS. Finally, we have shown the expressive power of priorities by providing an encoding of RAMs in CCS
 : Not only does the encoding preserve and reflect convergence but it also preserves and reflects divergence (the existence of infinite computations). This is to be contrasted with the
result of Busi et al. mentioned above.
: Not only does the encoding preserve and reflect convergence but it also preserves and reflects divergence (the existence of infinite computations). This is to be contrasted with the
result of Busi et al. mentioned above.
Fairness
In
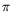 -calculus. We have followed Costa and Stirling's approach for CCS-like languages
-calculus. We have followed Costa and Stirling's approach for CCS-like languages
Linearity vs. persistence
In
On the asynchronous nature of the asynchronous
-calculus
In
a). To this purpose we have defined a calculus
 where channels are represented explicitly as special buffer processes. The base language for
is the (synchronous)
-calculus, except that ordinary processes communicate only via buffers. We have compared this calculus with
where channels are represented explicitly as special buffer processes. The base language for
is the (synchronous)
-calculus, except that ordinary processes communicate only via buffers. We have compared this calculus with
a, and we have shown that there is a strong correspondence between
aand
in the case that buffers are bags: there are indeed encodings which map each
aprocess into a strongly asynchronous bisimilar
process, and each
process into a weakly asynchronous bisimilar
aprocess. In case the buffers are queues or stacks, on the contrary, the correspondence does not hold. We have shown indeed that it is not possible to translate a stack or a queue into
a weakly asynchronous bisimilar
aprocess. Actually, for stacks we have shown an even stronger result, namely that they cannot be encoded into weakly (asynchronous) bisimilar processes in a
-calculus without mixed choice.
Foundations of information hiding
Romain
Beauxis
Christelle
Braun
Konstantinos
Chatzikokolakis
Mario Sergio
Ferreira Alvim Junior
Catuscia
Palamidessi
Vladimiro
Sassone
Information hiding refers to the problem of protecting private information while performing certain tasks or interactions, and trying to avoid that an adversary can infer such information.
Particular cases of this property are anonymity and privacy.
The systems for information hiding often use random mechanisms to obfuscate the link between the observables and the information to be protected. The random mechanisms can be described
probabilistically, while the value of the secret may be totally unpredictable, irregular, and hence expressible only nondeterministically. Nondeterminism can also be present due to the
interaction of the various component of the system.
The problem of the scheduler
It has been observed recently that in security the combination of nondeterminism and probability can be harmful, in the sense that the resolution of the nondeterminism can reveal the
outcome of the probabilistic choices even though they are supposed to be secret
Information theory
In
In
Bayes risk
The degree of protection provided by a protocol can be expressed in terms of the probability of error associated to the inference of the secret information. In
Compositional analysis of information hiding
In
Bounds on the leakage of the inputÕs distribution
In information hiding, an adversary that tries to infer the secret information has a higher probability of success if it knows the distribution on the secrets. In
Specification and verification of security protocols
Srecko
Brlek
Simon
Kramer
Catuscia
Palamidessi
Angelo
Troina
The probabilistic applied
-calculus
In order to obtain a language suitable for the specification and verification of a large class of security protocols, we aim at enriching the probabilistic
-calculus with value passing, encryption and decryption, other primitive functions, and data types, along the lines of the
applied
-calculus
Some preliminary work in this direction is represented by
Cryptographic protocol logic: Satisfaction for (timed) DolevÐYao cryptography
In
A General definition of malware
In
Reducing provability to knowledge in multi-agent systems
In
Dolev-Yao encryption is Urquhart-Routley implication
In
Concurrent Constraint Programming
Romain
Beauxis
Moreno
Falaschi
Catuscia
Palamidessi
Carlos
Olarte
Frank
Valencia
A smooth probabilistic extension of concurrent constraint programming
Concurrent constraint programming (
ccp,
In
Universal timed concurrent constraint programming
In
 calculus allows for the specification of mobile behaviours in the sense of Milner's
-calculus: Generation and communication of private channels or links. We first endowed
with an
operationalsemantics and then with a
symbolicsemantics to deal with problematic operational aspects involving infinitely many substitutions and divergent internal computations. The novelty of the symbolic semantics is to
use
temporal constraintsto represent finitely infinitely-many substitutions. We have also showed that
has a strong connection with Pnueli's temporal logic, and we have exploited this connection to prove reachability properties of
processes. As a compelling example, we have used
to exhibit the secrecy flaw of the Needham-Schroeder security protocol.
calculus allows for the specification of mobile behaviours in the sense of Milner's
-calculus: Generation and communication of private channels or links. We first endowed
with an
operationalsemantics and then with a
symbolicsemantics to deal with problematic operational aspects involving infinitely many substitutions and divergent internal computations. The novelty of the symbolic semantics is to
use
temporal constraintsto represent finitely infinitely-many substitutions. We have also showed that
has a strong connection with Pnueli's temporal logic, and we have exploited this connection to prove reachability properties of
processes. As a compelling example, we have used
to exhibit the secrecy flaw of the Needham-Schroeder security protocol.
The expressiveness of universal timed ccp: Undecidability of Monadic FLTL and Closure Operators for Security
In
More precisely, we have showed that in contrast to
tcc,
utccis Turing-powerful by encoding Minsky machines. The encoding proposed makes use of a monadic constraint system allowing us to prove a new result for a fragment of FLTL: The
undecidability of the validity problem for monadic FLTL without equality and function symbols. This result justifies the restriction imposed in previous decidability results on the
quantification of flexible-variables. We have also shown that, as in
tcc,
utccprocesses can be semantically represented as partial closure operators. The representation has been proved to be fully abstract wrt the input-output behavior of processes for a
meaningful fragment of the
utcc. This has shown that mobility can be captured as closure operators over an underlying constraint system. As an application of the semantic study of
utcc, we have identified a language for security protocols that can be represented as closure operators over a cryptographic constraint system.
Abstract interpretation
In
Model checking
Romain
Beauxis
Catuscia
Palamidessi
Model checking is the main tool that we aim at developing for the verification of security protocols.
In
Modeling biological systems
Jesus
Aranda
Sylvain
Pradalier
Frank
Valencia
Stochastic bigraphs
In
The
 calculus
calculus
In
Timed concurrent constraint programming for biological applications
In