Scientific Foundations
General Overview
proof search
proof normalization
In the specification of computational systems, logics are generally used in one of two approaches. In the
computation-as-modelapproach, computations are encoded as mathematical structures, containing such items as nodes, transitions, and state. Logic is used in an external sense to make
statements
aboutthose structures. That is, computations are used as models for logical expressions. Intensional operators, such as the modals of temporal and dynamic logics or the triples of Hoare
logic, are often employed to express propositions about the change in state. This use of logic to represent and reason about computation is probably the oldest and most broadly successful use
of logic in computation.
The
computation-as-deductionapproach, uses directly pieces of logic's syntax (such as formulas, terms, types, and proofs) as elements of the specified computation. In this much more rarefied
setting, there are two rather different approaches to how computation is modeled.
The
proof normalizationapproach views the state of a computation as a proof term and the process of computing as normalization (know variously as
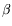 -reduction or cut-elimination). Functional programming can be explained using proof-normalization as its theoretical basis
-reduction or cut-elimination). Functional programming can be explained using proof-normalization as its theoretical basis
The
proof searchapproach views the state of a computation as a sequent (a structured collection of formulas) and the process of computing as the process of searching for a proof of a
sequent: the changes that take place in sequents capture the dynamics of computation. Logic programming can be explained using proof search as its theoretical basis
The divisions proposed above are informal and suggestive: such a classification is helpful in pointing out different sets of concerns represented by these two broad approaches (reductions,
confluence, etc, versus unification, backtracking search, etc). Of course, a real advance in computation logic might allow us merge or reorganize this classification.
Although type theory has been essentially designed to fill the gap between these two kinds of approaches, it appears that each system implementing type theory up to now only follows one of
the approaches. For example, the Coq system implementing the Calculus of Inductive Constructions (CIC) uses proof normalization while the Twelf system
The Parsifal team works on both the proof normalization and proof search approaches to the specification of computation.
Reasoning about logic specifications
higher-order abstract syntax
lambda-tree syntax
fixed points
definitions
LINC
generic judgments
Once a computational system (e.g., a programming language, a specification language, a type system) is given a logic (relational) specifications, how do we reason about the formal properties
of such specifications? New results in proof theory are being developed to help answer this question.
The traditional architecture for systems designed to help reasoning about the formal correctness of specification and programming languages can generally be characterized at a high-level as
follows:
First: Implement mathematics.This often involves choosing between a classical or constructive (intuitionistic) foundation, as well as a choosing abstraction mechanism (eg, sets or
functions). The Coq and NuPRL systems, for example, have chosen intuitionistically typed
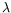 -calculus for their approach to the formalization of mathematics. Systems such as HOL
-calculus for their approach to the formalization of mathematics. Systems such as HOL
Such an approach to formal methods is, of course, powerful and successful. There is, however, growing evidence that many of the proof search specifications that rely on such intensional
aspects of logic as bindings and resource management (as in linear logic) are not served well by encoding them into the traditional data structures found in such systems. In particular, the
resulting encoding can often be complicated enough that the
essential logical characterof a problem is obfuscated.
Despeyroux, Pfenning, Leleu, and Schürmann proposed two different type theories
A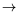
Bwhile general functions (for case and iteration reasoning) live in the full functional space
 . These works give a possible answer to the problem of extending the Edinburgh Logical Framework, well suited for describing expressions with binding, with recursion and induction
principles internalized in the logic (as done in the Calculus of Inductive Constructions). However, extending these systems to dependent types seems to be difficult (see
. These works give a possible answer to the problem of extending the Edinburgh Logical Framework, well suited for describing expressions with binding, with recursion and induction
principles internalized in the logic (as done in the Calculus of Inductive Constructions). However, extending these systems to dependent types seems to be difficult (see
The LINC logic of
First, LINC is an intuitionistic logic for which provability is described similarly to Gentzen's LJ calculus
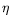 -equivalence. This core logic provides support for
-tree syntax, a particular approach to
higher-order abstract syntax. Considering a classical logic extension of LINC is also of some interest, as is an extension allowing for quantification at predicate type.
-equivalence. This core logic provides support for
-tree syntax, a particular approach to
higher-order abstract syntax. Considering a classical logic extension of LINC is also of some interest, as is an extension allowing for quantification at predicate type.
Second, LINC incorporates the proof-theoretical notion of
definition(also called
fixed points), a simple and elegant device for extending a logic with the if-and-only-if closure of a logic specification and for supporting inductive and co-inductive reasoning over
such specifications. This notion of definition was developed by Hallnäs and Schroeder-Heister
Third, LINC contains a new (third) logical quantifier
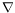 (nabla). After several attempts to reason about logic specifications without using this new quantifier
(nabla). After several attempts to reason about logic specifications without using this new quantifier
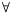 or
in the premise (body) of semantic definitions. In the presence of negations and implications, a difference between these two quantifiers does arise
or
in the premise (body) of semantic definitions. In the presence of negations and implications, a difference between these two quantifiers does arise
Focused proof systems
focused proof systems
There is a great deal of non-determinism that is present in the search for proofs (in the sense of automated deduction). The non-determinism involved with generating lemmas is one extreme:
when attempting to prove one formula it is possible to generate a potential lemma and then attempt to prove it and to use it to prove the original formula. In general, there are no clues as to
what is a useful lemma to construct. The famous “cut-elimination” theorem say that it is possible to prove theorems without using lemmas (that is, by restricting to
cut-freeproofs). Of course, cut-free proofs are not appropriate for all domains of computation logic since they can be vastly larger than proofs containing cuts. Even when restricting to
cut-free proofs make sense (as in logic programming, model checking, and some areas of automated reasoning), the construction of cut-free proofs still contains a great deal of
non-determinism.
Structuring the non-deterministic choices within the search for cut-free proofs has received increasing attention in recent years with the development of
focusing proofs systems. In such proof systems, there is a clear separation between non-deterministic choices for which no backtracking is required (“don't care non-determinism”) and
choices were backtracking may be required (“don't know non-determinism”). Furthermore, when a backtrackable choice is required, that choice actually extends over a series of inference rules,
representing a “focus” during the construction of a proof. One focusing-style proof systems was developed within the early work of providing a proof-theoretic foundations for logic programming
via
uniform proofs
Since a great deal of automated deduction (in the sense of logic programming, type inference, and model checking) is done in intuitionistic and classical logic, there is a strong need to
have comprehensive focusing results for these logics as well. In linear logic, the assignment of inference rules to the positive and negative phases is canonical (only the treatment of atomic
formulas is left as a non-canonical choice). Within intuitionistic and classical logic, a number of inference rules do not have canonical treatments. Instead, several focusing-style proof
systems have been developed one-by-one for these logics. A general scheme for putting all of these choices together has recently been developed within the team and will be described below.
Proof structure and proof certificates
proof certificates
There has been a good deal of concern in the proof theory literature on the nature of proofs as objects. An example of such a concern is the question as to whether or not two proofs should
be considered equal. Such considerations were largely of interest to philosophers and logicians. Computer scientists started to get involved with the structure of proofs more generally in
essentially two ways. The first is the extraction of algorithms from constructive proofs. The second is the use of proof-like objects to help make theorem proving systems more sophisticated
(proofs could be stored, edited, and replayed, for example).
It was not until the development of the topic of
proof carrying code (PCC)that computer scientists from outside the theorem proving discipline took a particular interesting in having proofs as actual data structure within computations.
In the PCC setting, proofs of safety properties need to be communicated from one host to another: the existence of the proof means that one does not need to trust the correctness of a piece of
software (for example, that it is not a virus). Given this need to produce, communicate, and check proofs, the actual structure and nature of proofs-as-objects becomes increasingly
important.
Often the term
proof certificate(or just
certificate) is used to refer to some data structure that can be used to communicate a proof so that it can be checked. A number of proposals have been made for possible structure of
such certificates: for examples, proof scripts in theorem provers such as Coq are frequently used. Other notions include oracle
The earliest papers on PCC made use of logic programming systems Twelf
Deep Inference and Categorical Axiomatizations
deep inference
category theory
Deep inference
One reason for using categories in proof theory is to give a precise algebraic meaning to the identity of proofs: two proofs are the same if and only if they give rise to the same morphism
in the category. Finding the right axioms for the identity of proofs for classical propositional logic has for long been thought to be impossible, due to “Joyal's Paradox”. For the same
reasons, it was believed for a long time that it it not possible to have proof nets for classical logic. Nonetheless, Lutz Straßburger and François Lamarche provided proof nets for classical
logic in
The following research problems are investigated by members of the Parsifal team:
Find deep inference system for richer logics. This is necessary for making the proof theoretic results of deep inference accessible to applications as they are described
in the previous sections of this report.
Investigate the possibility of focusing proofs in deep inference. As described before, focusing is a way to reduce the non-determinism in proof search. However, it is
well investigated only for the sequent calculus. In order to apply deep inference in proof search, we need to develop a theory of focusing for deep inference.
Use the results on deep inference to find new axiomatic description of categories of proofs for various logics. So far, this is well understood only for linear and
intuitionistic logics. Already for classical logic there is no common accepted notion of proof category. How logics like LINC can be given a categorical axiomatisation is completely
open.
Proof Nets and Combinatorial Characterization of Proofs
proof nets
cographs
relation webs
correctness criteria
Proof nets are abstract (graph-like) presentations of proofs such that all "trivial rule permutations" are quotiented away. More generally, we investigate combinatoric objects and
correctness criteria for studying proofs independently from syntax. Ideally the notion of proof net should be independent from any syntactic formalism. But due to the almost absolute monopoly
of the sequent calculus, most notions of proof nets proposed in the past were formulated in terms of their relation to the sequent calculus. Consequently we could observe features like “boxes”
and explicit “contraction links”. The latter appeared not only in Girard's proof nets
The concept of deep inference allows to design entirely new kinds of proof nets. Recent work by Lamarche and Straßburger
Extend the work of Lamarche and Straßburger to larger fragments of linear logic, containing the additives, the exponentials, and the quantifiers.
Finding (for classical logic) a notion of proof nets that is deductive, i.e., can effectively be used for doing proof search. An important property of deductive proof
nets must be that the correctness can be checked in linear time. For the classical logic proof nets by Lamarche and Straßburger
A logic for systems biology
hybrid logic
linear logic
temporal logic
systems biology
biology
stochastic transition systems
stochastic pi-calculus
Systems in molecular biology, such as those for regulatory gene networks or protein-protein interactions, can be seen as state transition systems that have an additional notion of
rateof change. Methods for specifying such systems is an active research area. However, to our knowledge, no logic (more powerful than the boolean logic) have been proposed so far to
both specify and reason about these systems.
One current and prominent method uses process calculi, such as the stochastic
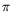 -calculus, that has a built in notion of rate
-calculus, that has a built in notion of rate
Kaustuv Chaudhuri and Joëlle Despeyroux are considering the problem of giving a
logicalinstead of a
process-basedtreatment both to specify and to reason about biological systems in a uniform linguistic framework. The logic they have proposed, called HyLL, is an extension of
(intuitionistic) linear logic with a modal situated truth that may be reified by means of the
 operator from
hybrid logic. A variety of semantic interpretation can be given to this logic, including the rates and the delay of formation.
operator from
hybrid logic. A variety of semantic interpretation can be given to this logic, including the rates and the delay of formation.
The expressiveness of the logic has been demonstrated on small examples and first meta-theoretical properties of the logic have been proven. Considerable work needs to be done before this
proposal succeeds as a natural logical framework for systems biology. Remaining work mainly includes the description of larger examples (requiring more specifications of usual biological
notions), and automating reasoning about the specifications. It also includes further studies of the meta-theoretical properties of the logic, and of course eventual extensions of the logic
(for example to get branching semantics).
New Results
Formalizing operational semantic specifications in logic
Dale
Miller
An important application area for some of the proof theory results of the team is in reasoning about the operational semantics of programs and specifications. Miller provided a survey of
various approaches to encoding such semantic specifications in the survey article
New insights into
-quantification
David
Baelde
Dale
Miller
The team has been actively extending the scope of effectiveness
-quantifications. As Tiu and Miller have shown in
The team has explored two different approaches to this problem. David Baelde
Another angle has been developed as a result of our close international collaborations. Alwen Tiu, now at the Australian National University, has developed a logic, called
 which extends the earlier, “minimal” approach by introducing the structural rules of strengthening and exchange into the context of generic variables. As a result, the behavior of
bindings becomes much more like the behavior of names more generally, while still maintaining much of the status as being binders. In combination with our close colleagues at the University of
Minnesota, we have extended this work to include a new definitional principle, called
nabla-in-the-head, that strengthens our ability to declaratively describe the structure of contexts and proof invariants. This new definitional principle was first presented in
which extends the earlier, “minimal” approach by introducing the structural rules of strengthening and exchange into the context of generic variables. As a result, the behavior of
bindings becomes much more like the behavior of names more generally, while still maintaining much of the status as being binders. In combination with our close colleagues at the University of
Minnesota, we have extended this work to include a new definitional principle, called
nabla-in-the-head, that strengthens our ability to declaratively describe the structure of contexts and proof invariants. This new definitional principle was first presented in
Foundational aspects of focusing proof systems
David
Baelde
Dale
Miller
Alexis
Saurin
Since focusing proof systems seem to be behind much of our computational logic framework, the team has spent some energies developing further some foundational aspects of this approach to
proof systems.
Chuck Liang and Miller have recently finished the paper
Given the team's ambitious to automate logics that require induction and co-induction, we have also looked in detail at the proof theory of fixed points. In particular, David Baelde's recent
PhD thesis
Alexis Saurin's recent PhD
A particular outcome of our work on focused proof search is the use of
maximally multifocused proofsto help provide sequent calculus proofs a canonicity. In particular, Chaudhuri (a former Parsifal post doc), Miller, and Saurin have shown in
A neutral approach to proof and refutation in MALL
Olivier
Delande
Dale
Miller
Alexis
Saurin
Given the team's previous efforts at building automated deduction systems that viewed finite success and finite failure as duals within a proof theory setting, we were intrigued to see if
that duality could be extended beyond the simple, Horn clause setting. This past year, Olivier Delande and Miller described in the paper
Meta-level focusing and object-level proof system
Vivek
Nigam
Dale
Miller
It is well known how to use an intuitionistic meta-logic to specify natural deduction systems. It is also possible to use linear logic as a meta-logic for the specification of a variety of
sequent calculus proof systems
Proof complexity
Lutz
Straßburger
In proof complexity one usually distinguishes between proofs “with extension” and proofs “without extension”, whereas in other areas of proof theory one distinguishes between proofs “with
cut” and proofs “without cut”. We have shown that with the use of deep inference it is possible to provide a uniform treatment for both classifications. This allows, in particular, to study
cut-free proofs with extension, which is not possible with other formalisms. By using deep inference we could also give a new and simpler proof for the well-known theorem saying that extended
Frege-systems p-simulate Frege-systems with substitution, and vice versa.
Proof normalization in sequent calculus
Stéphane
Lengrand
One way of obtaining cut-free proofs is to normalize a proof that contains cuts. Stéphane Lengrand has studied the termination of normalization procedures in sequent calculi.
The methodology uses proof-terms and rewrite systems on these objects, which have to be proved terminating.
Lengrand and Kikuchi in
Lengrand in
The proof term approach could provide a systematic method to obtain cut-elimination results in focused sequent calculi such as LJF and LKF
Computation with meta-variables
Stéphane
Lengrand
Meta-variables are central in proof search mechanisms to represent incomplete proofs and incomplete objects. They are used in almost all implementations of proof software, yet their
meta-theory remains less explored than that of complete proofs and objects such as the
-calculus.
Stéphane Lengrand and Jamie Murdoch Gabbay have studied an extension of
-calculus with a particular kind of meta-variables originating from nominal logic. A paper on this study is in revision phase for a publication in Information and Computation.
The highlight of 2008 is the design of a typing system with polymorphism
à laHindley-Milner, as used in programming languages like CaML. The extension of
-calculus with meta-variables creates particular difficulties for the typing algorithm to be implemented in the compiler. A deciding algorithm for typing is being developed using
constraints and graph theory.
A Stochastic Linear Logic for Biological Computation
Kaustuv
Chaudhuri
Joëlle
Despeyroux
Kaustuv Chaudhuri and Joëlle Despeyroux have proposed a logic, called HyLL (for Hybrid Linear Logic), for defining stochastic transition systems using linear implications for the state
transitions and a modal logic with the worlds representing the rates of transitions. The worlds (rates) are reified in the propositional syntax using the connectives of hybrid logic, which
allows directly encoding and reasoning about biological reaction systems, the intended use of this logic. This year, they have demonstrated the expressivity of the logic by giving an adequate
encoding of the stochastic pi-calculus using a focused sequent calculus. A paper has been submitted and a technical report is in preparation.