Scientific Foundations
Introduction
We survey the different fields, which underline the scientific basis of CARTE, enhancing the aspects around adverse computations.
Continuous Computation Theory
Today's classical computability and complexity theory deals with discrete time and space models of computation. However, discrete time models of machines working on a continuous space have
been considered: see e.g.
Blum, Shub and Smalemachines
Continuous models of computation lead to particular continuous dynamical systems. More generally, continuous time dynamical systems arise as soon as one attempts to model systems that evolve
over a continuous space with a continuous time. They can even emerge as natural descriptions of discrete time or space systems. Utilizing continuous time systems is a common approach in fields
such as biology, physics or chemistry, when a huge population of agents (molecules, individuals, ...) is abstracted into real quantities such as proportions or thermodynamic data
Computation theory of continuous dynamical systems allows us to understand both the hardness of questions related to continuous dynamical systems and the computational power of continuous
analog models of computations.
A survey on continuous-time computation theory, with discussions of relations between both approaches, co-authored by Olivier Bournez and Manuel Campagnolo, can be found in
Rewriting
Rewriting has reached some maturity and the rewriting paradigm is now widely used for specifying, modelizing, programming and proving. It allows for easily expressing deduction systems in a
declarative way, for expressing complex relations on infinite sets of states in a finite way, provided they are countable. Programming languages and environments have been developed, which have
a rewriting based semantics. Let us cite
ASF+SDF
For basic rewriting, many techniques have been developed to prove properties of rewrite systems like confluence, completeness, consistency or various notions of termination. In a weaker
proportion, proof methods have also been proposed for extensions of rewriting like equational extensions, consisting of rewriting modulo a set of axioms, conditional extensions where rules are
applied under certain conditions only, typed extensions, where rules are applied only if there is a type correspondence between the rule and the term to be rewritten, and constrained
extensions, where rules are enriched by formulas to be satisfied
An interesting aspect of the rewriting paradigm is that it allows automatable or semi-automatable correctness proofs for systems or programs. Indeed, properties of rewriting systems as those
cited above are translatable to the deduction systems or programs they formalize and the proof techniques may directly apply to them.
Another interesting aspect is that it allows characteristics or properties of the modelized systems to be expressed as equational theorems, often automatically provable using the rewriting
mechanism itself or induction techniques based on completion
Algorithmic Game Theory
Game theory aims at discussing situations of competition between rational players
For general games, the key concept of Nash equilibrium was proposed in the early 50s by John Nash in
Algorithmic game theory differs from game theory by taking into account algorithmic and complexity aspects. Indeed, historically main developments of classical game theory have been realized
in a mathematical context, without true considerations on effectiveness of constructions.
Game theory and algorithmic game theory have large domains of applications in theoretical computer science: it has been used to understand complexity of computing equilibria
Computer Virology
From an historical point of view, the first official virus appeared in 1983 on Vax-PDP 11. In the very same time, a series of papers was published which always remain a reference in computer
virology: Thompson
The literature which explains and discusses practical issues is quite extensive, see for example Ludwig's book
A virus is essentially a self-replicating program inside an adversary environment. Self-replication has a solid background based on works on fixed point in
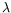 -calculus and on studies of Von Neumann
-calculus and on studies of Von Neumann
A virus infect programs by modifying them
A virus copies itself and can mutate
Virus spreads throughout a system
The above scientific foundation justifies our position to use the word virus as a generic word for self-replicating malwares. (There is yet a difference. A malware has a payload, and virus
may not have one.) For example, worms are an autonous self-replicating malware and so fall into our definition. In fact, the current malware taxonomy (virus, worms, trojans, ...) is unclear and
subject to debate.
Application Domains
Computations by Dynamical Systems
Continuous computation theories
Understanding computation theories for continuous systems leads to studying hardness of verification and control of these systems. This has been used to discuss problems in fields as
diverse as verification (see e.g.
We are interested in the formal decidability of properties of dynamical systems, such as reachability
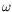 -limit set
-limit set
In contrast with the discrete setting, it is of utmost importance to compare the various models of computation over the reals, as well as their associated complexity theories. In
particular, we focus on the General Purpose Analog Computer of Claude Shannon
A crucial point for future investigations is to fill the gap between continuous and discrete computational models. This is one deep motivation of our work on computation theories for
continuous systems.
Analysis and verification of adversary systems
The other research direction on dynamical systems we are interested in is the study of properties of adversary systems or programs, i.e. of systems whose behavior is unknown or indistinct,
or which do not have classical expected properties. We would like to offer proof and verification tools, to guarantee the correctness of such systems.
On one hand, we are interested in continuous and hybrid systems. In a mathematical sense, a hybrid system can be seen as a dynamical system, whose transition function does not satisfy the
classical regularity hypotheses, like continuity, or continuity of its derivative. The properties to be verified are often expressed as reachability properties. For example, a safety property
is often equivalent to (non-)reachability of a subset of unsure states from an initial configuration, or to stability (with its numerous variants like asymptotic stability, local stability,
mortality, etc ...). Thus we will essentially focus on verification of these properties in various classes of dynamical systems.
We are also interested by rewriting techniques, used to describe dynamic systems, in particular in the adversary context. As they were initially developed in the context of automated
deduction, the rewriting proof techniques, although now numerous, are not yet adapted to the complex framework of modelization and programming. An important stake in the domain is then to
enrich them to provide realistic validation tools, both in providing finer rewriting formalisms and their associated proof techniques, and in developing new validation concepts in the
adversary case, i.e. when usual properties of the systems like, for example, termination are not verified.
For several years, we have been developing specific procedures for property proofs of rewriting, for the sake of programming, in particular with an inductive technique, already applied
with success to termination under strategies
The last three results take place in the context of adversary computations, since they allow for proving that even a divergent program, in the sense where it does not terminate, can give
the expected results.
A common mechanism has been extracted from the above works, providing a generic inductive proof framework for properties of reduction relations, which can be parametrized by the property
to be proved
A crucial element of safety and security of software systems is the problem of resources. We are working in the field of Implicit Computational Complexity. Interpretation based methods
like Quasi-interpretations (QI) or sup-interpretations, are the approach we have been developing these last five years, see
Robust and Distributed Algorithms, Algorithmic Game Theory
One of the problems related to distributed algorithmics corresponds to the minimization of resources (time of transit, quality of services) in problems of transiting information (routing
problems, group telecommunications) in telecommunication networks.
Each type of network gives rise to natural constraints on models. For example, a network is generally modeled by a graph. The material and physical constraints on each component of the
network (routers, communication media, topology, etc ...) result in different models. One natural objective is then to build algorithms to solve those types of problems on various models.
One can also constrain solutions to offer certain guarantees: for example the property of self-stabilization, which expresses that the system must end in a correct state whatever its initial
state is; or certain guarantees of robustness: even in the presence of a small proportion of Byzantine actors, the final result will remain correct; even in the presence of rational actors with
divergent interests, the final result will remain acceptable.
Algorithms of traditional distributed algorithmics were designed with the strong assumption that the interest of each actor does not differ from the interest of the group. For example, in a
routing problem, classical distributed algorithms do not take into account the economic interests of the various autonomous systems, and only try to minimize criteria such as shortest
distances, completely ignoring the economical consequences of decisions for involved agents.
If one wants to have more realistic models, and take into account the way the different agents behave, one gets more complex models.
However, today, one gets models which are hard to analyse. For example,
Models of dynamism are missing: e.g., how to model a negotiation in a distributed auction mechanism for the access to a telecommunications service,
only few methods are known to guarantee that the equilibrium reached by such systems remains in some domains that could be qualified as safe or reasonable,
there is almost no method discussing the speed of convergence, when there is convergence,
only a little is known about the time and space resources necessary to establish some techniques to guarantee correct behavior.
Thus, it is important to reconsider the algorithms of the theory of distributed algorithmics, under the angle of the competitive interests that involved agents can have (Adversary
computation). This requires to include/understand well how to reason on these types of models.
Computer Virology
Nowadays, our thoughts lead us to define four different research tracks, that we are describing below.
The theoretical track.
It is rightful to wonder why there is only a few fundamental studies on computer viruses while it is one of the important flaws in software engineering. The lack of theoretical studies
explains maybe the weakness in the anticipation of computer diseases and the difficulty to improve defenses. For these reasons, we do think that it is worth exploring fundamental aspects, and
in particular self-reproducing behaviors.
The virus detection track.
The crucial question is how to detect viruses or self-replicating malwares. Cohen demonstrated that this question is undecidable. The anti-virus heuristics are based on two methods. The
first one consists in searching for virus signatures. A signature is a regular expression, which identifies a family of viruses. There are obvious defects. For example, an unknown virus will
not be detected, like ones related to a 0-day exploit. We strongly suggest to have a look at the independent audit
The virus protection track.
The aim is to define security policies in order to prevent malware propagation. For this, we need (i) to define what is a computer in different programming languages and setting, (ii) to
take into consideration resources like time and space. We think that formal methods like rewriting, type theory, logic, or formal languages, should help to define the notion of a
formal immune system, which defines a certified protection.
The experimentation track.
This study on computer virology leads us to propose and construct a “high security lab” in which experiments can be done in respect with the French law. This project of “high security lab”
in one of the main project of the CPER 2007-2013.
Software
CARIBOO
Isabelle
Gnaedig
correspondant
In the context of our study of rule-based program proof and validation, we develop and distribute CARIBOO (
[http://
cariboo.
loria.
fr/
]), an environment dedicated to specific termination proofs under strategies like the innermost, the outermost or local strategies.
Written in
ELAN and Java, it has a reflexive aspect, since
ELAN is itself a rule-based language. CARIBOO was partially developed in the Toundra QSL project, and reinforced in the framework of the
Modulogic ACI
CROCUS
Guillaume
Bonfante
correspondant
Jean-Yves
Marion
Romain
Péchoux
The CROCUS software aims at synthesizing quasi-interpretations. It takes programs as input and returns the corresponding quasi-interpretation. Doing this, it can guarantee some bounds on the
memory used along computations by the input program. The currently analyzed programs are written in a subset of the CAML language, more precisely a first-order functional language subset of
CAML. The synthesis procedure has been reconsidered, it is more robust and efficient.
Detection engine by morphological analysis
Guillaume
Bonfante
Matthieu
Kaczmarek
correspondant
Jean-Yves
Marion
We develop a new approach to detect malware that we name morphological analysis. Refer to Section
TraceSurfer
Wadie
Guizani
Jean-Yves
Marion
Daniel
Reynaud
correspondant
TraceSurfer is our prototype implementation using dynamic binary instrumentation for malware analysis. This tool, based on Pin
Mr. Waffles
Daniel
Reynaud
correspondant
Mr. Waffles is a small implementation of the CTL model checking algorithm described in the classical textbook by Clarke et al. Its purpose is to allow easy experimentation with model
checking for academic projects, with a focus on program analysis. For this reason, we actually implemented checking over CTL-FV formulas, a more expressive extension of CTL with backward
branches and free variables originally described in
[http://
mrwaffles.
gforge.
inria.
fr/
].
Tartetatintools
Daniel
Reynaud
correspondant
Tartetatintools is made of four program instrumentation tools which are useful for program analysis :
antiantidebug: detects a few anti-debugging tricks on Windows
puppetmaster: detects a few CPU-based VMM detection tricks
stracewin_ia32: logs system calls and their parameters for the traced program
tracesurfer: a self-modifying code analyzer (along with an IDA add-on)
The project has been released as an open source project at
[http://
code.
google.
com/
p/
tartetatintools/
].
Cremebrulee
Daniel
Reynaud
correspondant
Cremebrulee is an experimental Javascript dynamic instrumentation engine. It takes a script, rewrites it (i.e. instruments it) and runs the instrumented version. During the rewrite, a few
modifications occur that log interesting events in obfuscated scripts.
This tool is useful to analyze programs written in java script.
The project has been released as an open source project at
[http://
code.
google.
com/
p/
cremebrulee/
].
Pym's
Matthieu
Kaczmarek
correspondant
In the context of program analysis, we develop and distribute Pym's library
[http://
code.
google.
com/
p/
pymsasid/
]and Pym's online disassembler
[http://
disasm86.
appspot.
com/
].
The former is is python disassembling library that provides interfaces for reverse engineering and static analysis such as control flow extraction. The latter is a Software As A Service
application which allows to visualize the instructions and the control flow of a program.
New Results
Computation over the Continuum
Walid
Gomaa
Emmanuel
Hainry
Mathieu
Hoyrup
While the notion of computable function over the natural numbers is universally accepted, its counterpart over continuous spaces, as the real line, is subject to discussion. The wide range
of possible formalizations partly has its origin in the diversity of structures continuous spaces can be endowed with: e.g. the real line can be seen as a topological space, a measure space, a
field, a vector space, a manifold, etc., depending on the particular problem one is concerned with. It happens that the topological structure of the set of real numbers is usually implicitly
taken as a reference for the theory of computable functions.
On the other hand, we are interested in the analysis of dynamical systems from the computability point of view. It happens that the probabilistic framework is of much interest to understand
the behavior of dynamical systems, as it enables one to distinguish physically relevant features of such systems, providing at the same time a way to understand robustness to noise. In
As a result, restricting to a topological approach is somewhat limitative and we are interested in a theory of computable functions that would fit well with probabilities. We carry out such
a development in
Olivier Bournez, Walid Gomaa, and Emmanuel Hainry presented in
Walid Gomaa in
Analysis and verification of adversary systems
Isabelle
Gnaedig
In the last few years, a significative amount of work has been done to propose correctness proof methods for rewriting-based programming. For termination and sufficient completeness, for
instance, various proof techniques are now available, when the reduction relation is enriched by equations, conditions, or when it is applied with particular strategies. Nevertheless, there is
still a lack of techniques, for example for certain strategies, of for weak properties i.e., properties that are not verified on every computation branch of the reduction relation. The latter
properties are interesting since in practice, programs do not always verify the properties in their strong acceptance.
For several years, we have been trying to answer the above problem in developing an induction based proof approach. For the problem of strategies, specific procedures were given for proving
termination under innermost, outermost and local strategies
For the problem of weak properties, our technique was applied to weak termination under the innermost strategy
uis crucial. For weak termination, it is sufficient to consider a set of branches representing at least one rewriting step for every reducible ground instance of
u. For C-reducibility, the set of narrowing branches has to be covering i.e., has to represent at least one reduction step for every ground instance of
u. A new definition of narrowing has been proposed to integrate these conditions. The correctness proof of the approach has also been factorized, enlightening the common and the specific
characteristics of both properties
Whatever the property to be proved, the above inductive technique lies on the notion of reductibility on ground terms. We have characterized how to model reducibility and irreducibility of
rewriting on ground terms using equational and disequational constraints. We have shown in particular that innermost (ir)reducibility can be modeled with a particular narrowing relation and
that equational and disequational constraints are issued from the most general unifiers of this narrowing relation. We then have proposed a proof of an innermost lifting lemma using this
(dis)equation-based characterization
Implicit Computational Complexity
Jean-Yves
Marion
Guillaume
Bonfante
Romain
Péchoux
Walid
Gomaa
Emmanuel
Hainry
The goal of implicit computational complexity is to give ontogenetic models of computational complexity. We follow two lines of research. The first line is more theoretical and is related to
the initial ramified recursion theory due to Leivant and Marion and to light linear logic due to Girard. The second is more practical and is related to interpretation methods,
quasi-interpretation and sup-interpretation, in order to provide an upper bound on some computational resources, which are necessary for a program execution. This approach seems to have some
practical interests, and we develop a software Crocus that automatically infer complexity upper bounds of functional programs.
ICC Core
In
Jean-Yves Marion
O(
nk)time over register machine model of computation. For this, we introduce a strict ramification principle. Then, we show how to diagonalize in order to obtain an exponential
function and to jump outside
 . Lastly, we suggest a dependent typed lambda-calculus to represent this construction.
. Lastly, we suggest a dependent typed lambda-calculus to represent this construction.
Interpretation methods
Guillaume Bonfante, together with Florian Deloup and Antoine Henrot have reconsidered the use of reals in the context of interpretation of programs in
The sup-interpretation method is proposed as a new tool to control memory resources of first order functional programs with pattern matching by static analysis
Recursive analysis
Olivier Bournez, Walid Gomaa and Emmanuel Hainry investigated the notion of implicit complexity in the framework of recursive analysis. In
Models of dynamics in Networks
Octave
Boussaton
We considered a model of interdomain routing proposed by a partner from SOGEA project that is based on the well known BGP protocol. We proved that the model has no pure Nash equilibria, even
for 4 nodes. Proof of convergence of the fictious player dynamics for the corresponding network has been established for some specific cases.
We reviewed the different models of dynamism in literature in game theory, in particular models from evolutionary game theory. We presented some ways to use them to realize distributed
computations in
We analyzed the behavior of providers on a specific scenario, mainly by considering the simple but not simplistic case of one source and one destination. The analysis of the centralized
transit price negotiation problem shows that the only one non cooperative equilibrium is when the lowest cost provider takes all the market. The perspective of the game being repeated makes
cooperation possible while maintaining higher prices. Then, we considered the system under a distributed framework. We simulated the behavior of the distributed system under a simple price
adjustment strategy and analyzed whether it matches the theoretical results or not. This work is published in
Moreover, we presented both a game theoretic and an algorithmic approach for solving the routing problem of choosing the best path in a path based protocol such as BGP. We proposed a
distributed learning algorithm which is able to learn Nash equilibria in a Wardrop network. This work was published in Parallel Processing Letters
Computer virology
Philippe
Beaucamps
Guillaume
Bonfante
Joan
Calvet
Wadie
Guizani
Matthieu
Kaczmarek
Jean-Yves
Marion
Daniel
Reynaud
The morphological analysis is a new methods of malware detection that we propose . It is based on signature recognition of abstraction of the control flow graphs of binaries. We provide
fast rooted and directed acyclic graph pattern matching algorithm based on tree automata. Compare to other (industrial) approaches, the morphological analysis based detection engines have at
least two advantage. First, there are quite robust wrt malware code mutation. Second, signatures may be automatically extracted. There is a running implementation that we currently test on
thousand of samples coming from honeypots and the telescope which is operated by Madynes EPI in the context of LHS. This detector may run in two modes: (i) it analyses statically binaries and
(ii) it analyses dynamically binaries using an instrumentation method based on PIN and related to our second main software developement TraceSurfer.
Most of the malware are nowadays packed in order to protect themselves against analysis performed by computers or by humans. In order to cope with packing techniques, we begin studies on
self-modifying programs from both a theoretical and a practical perspective. In particular, packers are a particular case of self-modifying programs. We build a tool, TraceSurfer
On a more theoretical aspect and related to
We work on behavioral analysis in order to detect malware. The idea is to detect a behavior like a keylogger. Again our approach is to have a sound theory in order to try to give
solutions
In 2009, we pursue the construction of the high security lab (LHS) in order to make experiments about computer security on a safe platform The EPI Madynes is working with us on this project.
There are currently two operational modules : A telescope and a "baby" cluster. There will be two equipped and secure rooms inside Loria building devoted to LHS.