Scientific Foundations
Computational Linguistics and Computational
Logic
We said above that the central research theme of TALARIS
was computational semantics (where “semantics” is broadly
construed to cover various pragmatic and discourse level
phenomena) and that TALARIS is particularly focused on
investigating the interplay between representation and
inference. Another way of putting this would be to say that
the scientific foundations of TALARIS's work boil down to the
motto:
computational linguisticsmeets
computational logicand
knowledge representation.
From computational linguistics we take the large
linguistic and lexical semantics resources, the parsing and
generation algorithms, and the insight that (whenever
possible) statistical information should be employed to cope
with ambiguity. From computational logic and knowledge
representation we take the various languages and
methodologies that have been developed for handling different
forms of information (such as temporal information), the
computational tools (such as theorem provers, model builders,
model checkers, sat-solvers and planners) that have been
devised for working with them, together with the insight
that, whenever possible, it is better to work with inference
tools that have been tuned for particular problems, and
moreover that, whenever possible, it is best to devote as
little computational energy to inference as possible.
This picture is somewhat idealized. For example, for many
languages (and French is one of them) the large scale
linguistic resources (lexicons, grammars, WordNet, FrameNet,
PropBank, etc.) that exist for English are not yet available.
In addition, the syntax/semantics interface often cannot be
taken for granted, and existing inference tools often need to
be adapted to cope with the logics that arise in natural
language applications (for example, existing provers for
Description Logic, though excellent, do not cope with
temporal reasoning). Thus we are not simply talking about
bringing together known tools, and investigating how they
work once they are combined — often a great deal of research,
background work and development is needed. Nonetheless, the
ideal of bringing together the best tools and ideas from
computational linguistics, knowledge representation and
computational logic and putting them to work in coordination
is the guiding line.
Semantics and Inference
Over the next decade, progress in natural language
semantics is likely to depend on obtaining a deeper
understanding of the role played by inference. One of the
simplest levels at which inference enters natural language is
as a disambiguation mechanism. Utterances in natural language
are typically highly ambiguous: inference allows human beings
to (seemingly effortlessly) eliminate the irrelevant
possibilities and isolate the intended meaning. But inference
can be used in many other processes, for example, in the
integration of new information into a known context. This is
important when generating natural language utterances. For
this task we need to be sure that the utterance we generate
is suitable for the person being addressed. That is, we need
to be sure that the generated representations fit in well
with the recipient's knowledge and expectations of the world,
and it is inference which guides us in achieving this.
Much recent semantic research actively addresses such
problems by systematically integrating inference as a key
element. This is an interesting development, as such work
redefines the boundary between semantics and pragmatics. For
example, van der Sandt's algorithm for presupposition
resolution (a classic problem of pragmatics) uses inference
to guarantee that new information is integrated in a coherent
way with the old information.
The TALARIS team investigates such semantic/pragmatic
problems from various angles (for example, from generation
and discourse analysis perspectives) and tries to combine the
insights offered by different approaches. For example, for
some applications (e.g., the textual entailment recognition
task) shallow syntactic parsing combined with fast inference
in description logic may be the most suitable approach. In
other cases, deep analysis of utterances or sentences and the
use of a first-order inference engine may be better. Our aim
is to explore these approaches and their limitations.
Linguistic Resources
In an ideal world, computational semanticists would not
have to worry overly much about linguistic resources. Large
scale lexica, treebanks, and wide coverage grammars
(supported by fast parsers and offering a flexible syntax
semantics interface) would be freely available and easy to
combine and use. The semanticist could then focus on modeling
semantic phenomena and their interactions.
Needless to say, in reality matters are not nearly so
straightforward. For a start, for many languages (including
French) there are no large-scale resources of the sort that
exist for English. Furthermore even in the case of English,
the idealized situation just sketched does not obtain. For
example, the syntax/semantics interface cannot be regarded as
a solved problem: phenomena such as gapping and VP-ellipsis
(where a verb, or verb phrase, in a coordinated sentence is
missing and has to be somehow “reconstructed” from the
previous context) still offer challenging problems for
semantic construction.
Thus a team like TALARIS simply cannot focus exclusively
on semantic issues: it must also have competence in
developing and maintaining a number of different lexical
resources (and in particular, resources for French).
TALARIS is involved in such aspects in a number of ways.
For example, it participates in the development of an open
source syntactic and synonymic lexicon for French, in an
attempt to lay the ground for a French version of FrameNet;
and it also works on developing a large scale, reversible
(i.e., usable both for parsing and for generation) Tree
Adjoining Grammar for French.
Logic Engineering
Once again, in the ideal world, not only would
computational semanticists not have to worry about the
linguistic resources at their disposal, but they would not
have to worry about the inference tools available either.
These could be taken for granted, applied as needed, and the
semanticist could concentrate on developing linguistically
inspired inference architectures. But in spite of the
spectacular progress made in automated theorem proving (both
for very expressive logics like predicate logics, and for
weak logics like description logics) over the last decade, we
are not yet in the ideal world. The tools currently offered
by the automated reasoning community still have a number of
drawbacks when it comes to natural language applications.
For a start, most of the efforts of the first-order
automated reasoning community have been devoted to theorem
proving; model building, which is also a useful technology
for natural language processing, is nowhere nearly as well
developed, and far fewer systems are available. Secondly, the
first-order reasoning community has adopted a resolutely
`classical' approach to inference problems: their provers
focus exclusively on the satisfiability problem. The
description logic community has been much more flexible,
offering architectures and optimisations which allow a
greater range of problems to be handled more directly. One
reason for this has been that, historically, not all
description logics offered full Boolean expressivity. So
there is a long tradition in description logic of treating a
variety of inference problems directly, rather than via
reduction to satisfiability. Thirdly, many of the logics for
which optimised provers exists do not directly offer the
kinds of expressivity required for natural language
applications. For example, it is hard to encode temporal
inference problems in implemented versions of description
logics. Fourth, for very strong logics (notably higher-order
logics) few implementations exists and their performance is
currently inadequate.
These problems are not insurmountable, and TALARIS members
are actively investigating ways of overcoming them. For a
start, logics such as higher-order logic, description logic
and hybrid logic are nowadays thought of as various fragments
of (or theories expressed in) first-order logic. That is,
first-order logic provides a unifying framework that often
allows transfer of tools or testing methodologies to a wide
range of logics. For example, the hybrid logics used in
TALARIS (which can be thought of as more expressive versions
of description logics) make heavy use of optimization
techniques from first-order theorem proving.
Empirical Studies
The role of empirical methods (model learning, data
extraction from corpora, evaluation) has greatly increased in
importance in both linguistics and computer science over the
last fifteen years. TALARIS members have been working for
many years on the creation, management and dissemination of
linguistic resources reusable by the scientific community,
both in the context of implementation of data servers, and in
the definition of standardized representation formats like
TAG-ML. In addition, they have also worked on the
applications of linguistic ideas in multimodal settings and
multimedia.
Such work is important to our scientific goals. As we said
above, one of the most important points that needs to be
understood about logical inference is how its use can be
minimized and intelligently guided. Ultimately, such
minimization and guidance must be based on empirical
observations concerning the kinds of problems that arise
repeatedly in natural language applications.
Finally, is should be remarked that the emphasis on
empirical studies lends another dimension to what is meant by
inference. While much of TALARIS's focus is on symbolic
approaches to inference, statistical and probabilistic
methods, either on their own or blended with symbolic
approaches, are likely to play an increasingly important role
in the future. TALARIS researchers are well aware of the
importance of such approaches and are interested in exploring
their strengths and weaknesses, and where relevant, intend to
integrate them into their work.
Application Domains
Modular Grammar Building
The development of large scale grammars is a complex task
which usually involves factorising information as much as
possible. While good grammar writing and factorisation
environments exist for “non tree grammars” (e.g., HPSG, LFG),
this is not the case for “tree based grammars” such as TAG,
Interaction Grammars or Tree Description Grammars. The
Extended Metagrammar Compiler (XMG) developed at TALARIS
remedies this shortcoming while additionally providing a
clean and modular way to describe several linguistic
dimensions thereby supporting the production of tree grammars
with semantic information
Referential Expressions
TALARIS has a longstanding interest in the semantics and
the processing of referential expressions. In recent years,
an extensive corpus annotation has been carried out on 5.000
definite descriptions
Surface Realization
The tree adjoining grammar for French developed by TALARIS
associates with each NL expression not only a syntactic tree
but also a semantic representation. Interestingly, the
semantic calculus used is reversible in that the association
between strings and semantic representations is
non-directional (declarative). We put this feature to work
and have been working over the years towards developing
surface realisers for French called GenI
Textual Entailment Recognition
In essence, the textual entailment recognition task is an
inference task, namely deciding whether the information
contained in a given text
T1can be inferred from the information provided by
another text
T2.
It is crucial to be able to answer this question. One
important characteristic of natural language is the large
number of ways in which it can express the same information.
Many natural language processing applications like question
answering, information retrieval, generation, and anaphora
resolution need to deal with this diversity efficiently and
accurately, and recognising textual entailments is a key step
towards this.
Textual entailment recognition is a difficult task. We
work on developing linguistically principled approaches to
tackle specific entailment sources such as syntactic
variations or the compositional semantics of factive verbs
Computational Logics and Computational
Semantics.
Members of TALARIS have long actively proposed and
developed the idea of using inference (and in particular,
using computational tools like model builders and theorem
provers) as an integral part of different tasks in
computational semantics, mainly during semantic construction
Hybrid Automated Deduction
TALARIS's main contribution in this topic has been the
design of resolution and tableaux calculi for hybrid logics,
calculi that were then implemented in the
HyLoResand
HTabtheorem
provers. For example, TALARIS members have proved that the
resolution calculus for hybrid logics can be enhanced with
optimisations of order and selection functions without losing
completeness. Moreover, a number of `effective' (i.e.,
directly implementable) termination proofs for the hybrid
logic
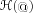 has been established, for both resolution and tableaux
based approaches, and the techniques are being extended to
more expressive languages. Current work includes adding a
temporal reasoning component to the provers, extending the
architecture to allow querying against a background theory
without having to explore again the theory with each new
query, and testing the hybrid provers performance against
dedicated state-of-the-art provers from other domains
(firs-order logic, description logics) using suitable
translations.
has been established, for both resolution and tableaux
based approaches, and the techniques are being extended to
more expressive languages. Current work includes adding a
temporal reasoning component to the provers, extending the
architecture to allow querying against a background theory
without having to explore again the theory with each new
query, and testing the hybrid provers performance against
dedicated state-of-the-art provers from other domains
(firs-order logic, description logics) using suitable
translations.
Moreover, we are interested in providing a range of
inference services beyond satisfiability checking. For
example, the current version of
HyLoResand
HTabincludes model
generation (i.e., the provers can generate a model when the
input formula is satisfiable).
We have also started to explore other decision methods
(e.g., game based decision methods) which are useful for
non-standard semantics like topological semantics. The prover
HyLoBanis an
example of this work.
Multimedia
MLIF (Multi Lingual Information Framework) is intended to
be a generic ISO-based mechanism for representing and dealing
with multilingual textual information. A preliminary version
of MLIF has been associated with digital media within the
ISO/IEC MPEG context and dealing with subtitling of video
content, dialogue prompts, menus in interactive TV, and
descriptive information for multimedia scenes. MLIF comprises
a flexible specification platform for elementary multilingual
units that may be either embedded in other types of
multimedia content or used autonomously to localise existing
content.
Interfacing Virtual Worlds and Natural Language
Processing
In 2010, Talaris addressed a new application domain
namely, the integration of deep natural language processing
(NLP) techniques with 3D worlds and games. A first foray into
that theme has been the submission of two systems to the
international GIVE (Giving instructions in a virtual
environment). Two recently accepted EU funded projects
(Interreg project Allegro and Eurostar project Emo-Speech) on
that theme will permit a fully blown exploration of the
research issues and of the technological problems arising in
this area. This new theme builds on the tools and techniques
developped by Talaris over the last 5 years for deep NLP and
in particular, on the availability of an expressive grammar
writing environnement (XMG), of wide coverage deep grammars
for French and English (SemTAG and SemXTAG), of a grammar
based surface realiser (GenI) and of parsers (LLP2, SemConst)
using these grammars.
Software
AGREE
AGREE (Asynchronous Grounding of REferential Expressions)
is a set of modules that manage the grounding process at the
reference level. It contains an interpretation evaluation
module that construes understanding judgments made by the
system and those manifested in the dialogue by the user, a
dialogue module that maintains a coherent state of the
dialogue (adjacency pairs), and a generation module (GenI) in
order to produce paraphrases of the understood referents. The
whole system has been implemented in Java and uses the same
semantic/referential representation that was used in the
MEDIA project.
Version: 0.1
License: GPL
Last update: 2008-11-12
Web site:
[http://
www.
loria.
fr/
~denis/
grounding.
html]
Authors: Alexandre Denis
Contact: Alexandre Denis
The eXtended Meta-Grammar (
XMG) Compiler and
Tools
A metagrammar compiler generates automatically a grammar
from a reduced description called a MetaGrammar. This
description captures the linguistic properties underlying the
syntactical rules of a grammar. Various past and present
TALARIS members have been working on metagrammar compilation
since 2001 and several tools have been developed within this
framework starting with the MGC system of Bertrand Gaiffe
(now of ATILF,
Analyse et Traitment Informatique de la Langue
Francaise, a Nancy-based CNRS unit) to the newly
developed
XMGsystem of
Crabbé et al.
The
XMGsystem is a 2nd
generation compiler that proposes (a) a representation
language allowing the user to describe in a factorised and
flexible way the linguistic information contained in the
grammar, and (b) a compiler for this language (using a Warren
Abstract Machine-like architecture). An innovative feature of
this compiler is the fact that it makes it possible to
describe several linguistic dimensions, and in particular it
is possible to define a natural Syntax/Semantics interface
within the Metagrammar.
The compiler actually supports two syntactic formalisms
(Tree Adjoining Grammars and Interaction Grammars) and the
description both of the syntactic and of the semantic
dimension of natural language. The generated grammars are in
XML format, which makes them easy to reuse. Plug-ins have
been realised with the LLP2 parser, with Eric de la
Clergerie's DyALog parser and with the
GenIgenerator.
Future work will deal with the modularisation and the
extension of
XMGto define a
library of languages describing linguistic data allowing the
user to describe his own target formalism.
Developed under the supervision of Denys Duchier, the
XMGcompiler is the
result of an intensive collaboration with CALLIGRAMME. It has
been implemented in Oz/Mozart and runs under the Linux, Mac,
and Windows platforms. It is available with tools easing its
use with parsers and generators (tree viewer, duplicate
remover, anchoring module, metagrammar browser).
The system is currently being used and tested by Owen
Rambow (University of Columbia, USA) and Laura Kallmeyer
(University of Tuebingen, Germany).
Version: 1.1.4
License: CeCILL
Last update: 27/09/2005
Web site:
[http://
sourcesup.
cru.
fr/
xmg/
]
Documentation:
[http://
sourcesup.
cru.
fr/
xmg/
#Documentation]
Authors: Benoit Crabbé, Denys Duchier,
Joseph Le Roux, Yannick Parmentier
Contact: Benoit Crabbé, Yannick
Parmentier
Frolog
Frolog is a dialogue system based on current technology
from computational linguistics, artificial intelligence
planning, and theorem proving. It implements a text adventure
game engine that uses natural language processing techniques
to analyse the player's input and generate the system's
output.
The Frolog core is implemented in Prolog and Java, but it
uses external tools for the most heavy-loaded tasks. It
performs syntactic analysis of the input based on an English
grammar developed using
XMGand computes a
flat semantic representation using the Tulepa parser. It then
uses the constructed semantic representation and an
off-the-shelf planner to interpret the player's intention and
change the world model accordingly. The world is modelled as
a knowledge base in description logics, and accessed using
the Description Logic theorem prover
Racer. Finally,
the results of the action, or descriptions of objects, are
generated automatically, using the
GenIgenerator.
Frolog is intended to serve as a laboratory in order to
test pragmatic theories about the phenomenon of
accommodation. It is also result in the first integrated
system to use
SemTag(the LORIA
toolbox for TAG-based Parsing and Generation).
Version: 1.0
License: GPL
Last update: 2008-11-07
Authors: Luciana Benotti, Alejandra
Lorenzo, Laura Perez
Contact: Luciana Benotti
GenIsurface
realiser
The
GenIsurface
realiser is a successor of the InDiGen realiser. Also based
on a chart algorithm, it is implemented in Haskell and aims
for modularity, re-usability and extensibility. The system is
“stand-alone” as we use the Glasgow Haskell compiler to
obtain executable code for Windows, Solaris, Linux and Mac OS
X.
The
GenIgenerator uses
efficient datatypes and intelligent rule application to
minimise the generation of redundant structures. It also uses
a notion of polarities as a means, first, of coping with
lexical ambiguity and second, of selecting variants obeying
given syntactic constraints.
GenIis compatible
with both a grammar for French (
SemTag) and for
English (
SemXTag), both
grammars beeing produced using the MetaGrammar Compiler.
SemTagcovers the
basic syntactic structures of French as described in Anne
Abeillé's book “An Electronic Grammar for French”.
SemXTaghas a
coverage similar to that of XTAG, the TAG grammar for English
developped by the University of Pennsylvannia . Both grammars
are additionnally equiped with a compositional semantics
supporting semantic construction (during parsing) and/or
surface realisation.
The system can process the output of the
XMGMetagrammar
compiler mentioned above.
Version: 0.20.2
License: GPL
Last update: 2009-11-16
Web site:
[http://
talc.
loria.
fr/
GenI-un-realisateur-de-surface.
html]
Project(s):
GenI
Authors: Carlos Areces, Claire Gardent,
Eric Kow
Contact: Claire Gardent
HyLoRes, a
Resolution Based Theorem Prover for Hybrid Logics
HyLoResis a
resolution based theorem prover for hybrid logics (it is
complete for the hybrid language H(@,
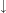 ), a very expressive but undecidable language, and it
implements a decision method for the sublanguage H(@)). It
implements a version of the “given clause” algorithm which is
the underlying framework of many current state of the art
resolution-based theorem provers for first-order logic; and
uses heuristics of order and selection function to prune the
search space on the space of possible generated clauses.
), a very expressive but undecidable language, and it
implements a decision method for the sublanguage H(@)). It
implements a version of the “given clause” algorithm which is
the underlying framework of many current state of the art
resolution-based theorem provers for first-order logic; and
uses heuristics of order and selection function to prune the
search space on the space of possible generated clauses.
HyLoResis
implemented in Haskell, and compiled with the Glasgow Haskell
compiler (thus, users need no additional software to use the
prover). We have also developed a graphical interface.
The interest of
HyLoResis twofold:
on one hand it is the first mature theorem prover for hybrid
languages, and on the other, it is the first modern
resolution based prover for modal-like languages implementing
optimisations and heuristics like order resolution with
selection functions.
Version: 2.5
License: GPL
Last update: 2009-04-09
Web site:
[http://
www.
glyc.
dc.
uba.
ar/
content/
tools.
php]
Authors: Carlos Areces, Daniel Gorín and
Juan Heguiabehere
Contact: Carlos Areces
HTab, a Tableau
Based Theorem prover for Hybrid Logics
The main goal behind
HTabis to make
available an optimised tableaux prover for hybrid logics,
using algorithms that ensure termination. We ultimately aim
to cover a number of frame conditions (i.e., reflexivity,
symmetry, antisymmetry, etc.), as far as we can ensure
termination. Moreover, we are interested in providing a range
of inference services beyond satisfiability checking. For
example, the current version of
HTabincludes model
generation (i.e.,
HTabcan generate a
model from a saturated open branch in the tableau).
HTaband
HyLoResare
actually being developed in coordination, and a generic
inference system involving both provers is being designed.
The aim is to take advantage of the dual behaviour existing
between the resolution and tableaux algorithms: while
resolution is usually most efficient for unsatisfiable
formulas (because a contradiction can be reported as soon as
the empty clause is derived), tableaux methods are better
suited to handle satisfiable formulas (because a saturated
open branch in the tableaux represents a model for the input
formula).
Version: 1.5.4
License: GPL
Last update: 2010-11-10
Web site:
[http://
www.
glyc.
dc.
uba.
ar/
content/
tools.
php]
Authors: Carlos Areces, Guillaume
Hoffmann
Contact: Guillaume Hoffmann
HyLoBan, a Game
Based Theorem Prover for Topological Hybrid
Logics
HyLoBanis a
game-based prover, resulting from a direct implementation of
Sustretov's game-based proofs of the PSPACE-completeness of
the hybrid logics of T0 and T1 topological spaces. The
interest of this approach is that termination is guaranteed
and in addition the underlying game-based architecture is of
independent interest; its disadvantage is that (at present)
it is still extremely inefficient.
Version: 0.2
License: GPL
Last update: 2009-10-29
Web site:
[http://
www.
glyc.
dc.
uba.
ar/
content/
tools.
php]
Authors: Carlos Areces, Guillaume
Hoffmann, Dmitry Sustretov
Contact: Guillaume Hoffmann
hGEN, a Random Formula Generator
hGen is a random CNF (conjunctive normal form) generator
of formulas for sublanguages of H(@,
, A, P). It is an extension of the latest proposal of
Patel-Schneider and Sebastiane, nowadays considered the
standard testing environment for classical modal logics. The
random generator is used for assessing the performance of
different provers.
Version: 1.2
License: GPL
Last update: 2009-06-17
Web site:
[http://
www.
glyc.
dc.
uba.
ar/
content/
tools.
php]
Authors: Carlos Areces, Daniel Gorín, Juan
Heguiabehere and Guillaume Hoffmann
Contact: Carlos Areces
MEDIA
In the framework of the MEDIA project, software has been
developed to process transcriptions of a spoken dialogue
corpus and to provide a semantic representation of their
task-related content. This software contains a tokeniser, a
LTAG parser (LLP2), a LTAG grammar, an OWL ontology and a set
of rules in description logic, and works together with a
reasoner such as RACER. The current version contains a
reference resolution module (anaphora and deixis) which is
based on the referential domains theory. The package also
contains ways to project the semantic form (referentially
solved) into the MEDIA formalism and to evaluate the accuracy
of the representation using a test corpus. The whole system
has been implemented in Java and communicates with other
modules using TCP/IP.
Version: 0.5
License: GPL
Website:
[http://
www.
loria.
fr/
~denis/
media.
html]
Last update: 12/11/2008
Project(s): MEDIA
Authors and Contact: Alexandre Denis
Nessie
Nessie is a semantic construction tool written in OCaml.
It takes a lexicon and a syntax tree as input and produces a
semantic representation taking the form of a simply typed
lambda term. Simply typed lambda calculus is used not only as
the target language, but also as the glue language for
assembling the representations provided by the lexicon.
This tool has been successfully used in several
applications, the most notable of which being the computation
of discourse semantics according to two different theories,
namely the compositional DRT (Muskens 95) and the
compositional treatment of dynamicity (de Groote 2006).
Future developments of Nessie may include using richer
typing systems, and interfacing it with inference and
rewriting tools to simplify the representations it
produces.
Last update:
2008-11-14
Authors: Sébastien Hinderer
Contact: Sébastien Hinderer
DeDe Corpus
DeDe is a corpus of roughly 50.000 words where around
5.000 definite descriptions have been annotated as
coreferential, contextually dependent, non referential or
autonomous. The corpus consists of articles from the
newspaper
Le Mondeand is annotated with Multext-based
morphosyntactic information
Authors: Claire
Gardent, Hélène Manuelian
Web site: Distributed by the CNRTL
[http://
www.
cnrtl.
fr/
]
Contact: Claire Gardent
SemTAG
A TAG grammar developed with the
XMGmetagrammar
compiler and which describes both the syntax and the
semantics of a core fragment coverage of French.
Syntactically, the grammars covers the constructions
described in A. Abeillé 's book. Additionnally, it is
equipped with a unification based compositional semantics
which supports both semantic construction (using LLP2, Tulipa
or SemCONST) and surface realisation (using GenI).
Authors: Claire
Gardent, Benoit Crabbé
Contact: Claire Gardent
SemXTAG
A TAG grammar for English developed with the
XMGmetagrammar
compiler and which describes both the syntax and the
semantics of English. Syntactically, the grammar has a
coverage comparable to that of the XTAG grammar developed by
the University of Pennsylvannia. Additionnally, the grammar
integrates a unification based compositional semantics. Used
both for parsing (by LLP2 and SemCONST) and for generation
(by GenI).
Authors: Claire
Gardent, Katya Alahverdzhieva
Contact: Claire Gardent
WikipediaAnnotator
The WikipediaAnnotator program provides semantic
annotation of Wikipedia discussion pages. It annotates French
Wikipedia participants utterances on the connotation and
subjective levels using deep syntax and shallow
semantics.
Developing context:
CCCP-Prosodie
Programming language: Java
Development effort: 18 man/month
Type of license: GPL
Partners: Telecom Paris Tech
Web site: – (in construction)
ATOOL
ATOOL is a semantic Annotation Tool for the High-Level
Semantic Representation MMIL which takes as input the MEDIA
corpus (TEI format according to the specifications document
of September 2009)
Developing context:
PORT-MEDIA
Programming language: Java
Development effort: 4 months (student) + 1
month of evaluation and improvements.
Expected users: Annotators
Type of license: Open Source.
Web site:
[http://
www.
port-media.
org/
doku.
php?id=start]
SRL-Web Annotation
This tool allows the annotation of the utterances in the
MEDIA corpus and stores all the information about predicates
and arguments in a relational database.
Developing context:
PORT-MEDIA
Programming language: JSP-JAVA
Development effort: 1 month.
Expected users: Annotators
Type of license: Open Source.
Web site:
[http://
talc.
loria.
fr/
]
PORT-MEDIA
PORT-MEDIA is a framework supporting the automatic
annotation of the MEDIA corpus with the high-level semantic
representation MMIL. It is a blackboard architecture
interfaced with the Tree Tagger, the Malt parser, the frames,
the semantic role labeling and the HLSBuilder for the
automatic annotation of the MEDIA Corpus. Additionally it is
interfaced with RACER, two ontologies in owl and a relational
database with all the information at different linguistic
levels. Finally the evaluation software is also provided.
Developing context:
PORT-MEDIA
Programming language: Java, MySql, XML,
XSLT, OWL.
Development effort: 12 months.
Expected users: Annotators
Type of license: Open Source.
Web site:
[http://
www.
port-media.
org/
doku.
php?id=start]
WSMACI
The Web Service for the Multilingual-Assisted Chat
Interface program (WSMACI) is a linguistic assistant for
virtual worlds. Its first version is dedicated to English
assistance in such worlds. It has been developed in the
context of the Metaverse1 project. It provide the end-users
with MLIF-based provision of sentence analysis and word
information (synonyms, definitions, translations) based on
Google Translate, WordNet and the Brown Corpus.
Programming language:
MLIF, PHP, SQL
Development effort: 6 man/month
Type of license: INRIA specific
Authors : Tarik Oswald, Samuel
Cruz-Lara
Contact: Tarik Oswald
Web site: – (in construction)
4LED
The 4 Layers Emotion Detection program (4LED) is an
emotion detection tool. The emotions are extracted from texts
in particular, from chat interfaces in virtual worlds. It has
been developed in the context of the Metaverse1 project. The
emotion detection process is based on SMILEY detection using
WordNet-Domains and Tree-Tagger-based rules, WordNet-Affect,
and keywords.
Programming language:
MLIF, PHP, SQL
Development effort: 6 man/month
Type of license: INRIA specific
Partners: ArtefactO (for rendering)
Authors : Tarik Oswald, Samuel
Cruz-Lara
Contact: Tarik Oswald
Web site: – (in construction)
SLMC
The Second Life Magic Carpet program (SLMC) is an
assistant whose role is to guide people through virtual
worlds with textual instructions. It has been developed in
the context of the Metaverse1 project. It has been developed
in the context of the Metaverse1 project. It analyses the
instructions of the visitors in order to find where they want
to go, using web services for the analysis, for synonyms
retrieving and for path finding.
Developing context:
Metaverse1
Programming language: LSL, PHP, SQL
Development effort: 8 man/month
Type of license: INRIA specific
Partners: Innovalia Spain, Utrecht
University
Authors : Tarik Oswald, Samuel
Cruz-Lara
Contact: Tarik Oswald
Web site: – (in construction)
DiacXis
The DiacXis program seeks to analyse the evolution over
time of textual information. It has been developed in the
context of the CPER TALC action McFiiD. DiacXis addresses the
analysis of textual information evolving over time using a
diachronic approach based both on the Multiview Data Analysis
(MVDA) paradigm and on specific cluster labeling techniques
especially developed for the statistical analysis of complex
data, like textual data
Programming language:
C + Java
Development effort: 6 man/month
Type of license: INRIA specific
Partners: INIST, ITT Kampur
Authors : Jean-Charles Lamirel, Navesh
Pryankar
Contact: Jean-Charles Lamirel
Web site: – (in construction)
IGNGF
The IGNG-F program implements a new incremental clustering
algorithm whose main domain of application is the statistical
analysis of continuous flow of evolving textual data. It has
been developed in the context of the CPER TALC (McFiiD
action). It is based on a generic adaptation of the classical
neural-based clustering approaches using gas of neurons with
free topology. This adaptation resulted in a description
space independent and parameter-free, neural clustering
technique using Hebbian learning and labeling expectation
maximization instead of classical Euclidean or correlation
distances
Programming language:
C
Development effort: 6 man/month
Type of license: INRIA specific
Partners: INIST, ITT Hyderhabad
Authors : Jean-Charles Lamirel, Raghvendra
Mall
Contact: Jean-Charles Lamirel
Web site: – (in construction)
TextClus
The TextClus interface is a java interface whose role is
to provide end-users with a whole set of clustering
techniques applied to texts. It has been developed in the
context of the CPER TALC McFiiD operation. The platform uses
a vectorial representation of text data. It includes, in a
federating interface, the management of different kinds of
data preprocessing techniques (IDF, entropy, random mapping,
...), different kinds of clustering techniques (from standard
methods to elaborated neural ones), the management of
multiple experiments and comparison of their results by
method-independent clustering quality measures specifically
adapted to the analysis of textual data
Programming language:
C
Development effort: 6 man/month
Type of license: INRIA specific
Partners: INIST
Authors : Jean-Charles Lamirel, Pascal
Cuxac
Contact: Jean-Charles Lamirel
Web site: – (in construction)
New Results
Dynamic Modal Logics
We are investigating modal logics that
include operators that not only allow for exploration of the
model in which they are evaluated, but that can also
modifyit. These logics could be specially suitable to
describe, for example, the semantic of utterances, to model
the fact that uttering a sentence changes the context it was
uttered in.
We have investigated in detail a family of dynamic modal
logics called
memory logicsand established lower and upper
complexity bounds, mapped their expressive power, devised
tableaux and model checking algorithms, and sound and
complete axiomatizations.
Automated Deduction for Hybrid Logics
This year we have finally released stable versions of the
two theorem provers (HyLoRes and HTab) for hybrid logics
developed by the team. Moreover, the theoretical framework
behind each of them has been described in detail in a PhD
thesis and a journal article.
Integrating inference with dialogue
This work concentrates on integrating techniques from
logic and artificial intelligence ( notably planning) with
work on pragmatics and the structure of dialogue
Giving Instruction in a Virtual World
(GIVE)
We developed two generation systems for the international
GIVE challenge
Using 3D worlds to teach French
(I-FLEG)
Within the Interreg IV A Allegro project, we investigated
how embedding text generation in a 3D game could help
automating the generation of situated language exercises
i.e., exercises whose content varies with the 3D world
context, with the learner level and with the teaching goal.
We developed a system (I-FLEG) illustrating this interaction
and made contact with language teachers to arrange for
learner use and teacher testing. I-FLEG will be deployed in
2011 in language learning classes and its usability for
language teaching tested.
Semantic construction using rewriting
Paul Bédaride and Claire Gardent developed a new method
for constructing semantic representations for textual data
which is based on graph rewriting
Using Regular Tree Grammars to enhance surface
realisation
Making use of the fact that Regular Tree Grammars can
generate the derivation trees of a Tree Adjoining Grammar, we
developed an alternative surface realiser to Geni called
RTGen. Preliminary results suggest that RTGen outperforms
GenI. Current work concentrates on further optimising RTGen
and on integrating top down control to reduce the search
space and constrain the output
Verb classes and Semantic Role Labelling for
French
Although verb classes and Semantic Role Labelling (SRL)
have been shown to be an essential component of semantic
processing, there is to date no such resource and tool for
French. Using Formal Concept Analysis and information from
the LADL tables, we developed a method for classifying verbs
based on their subcategorisation information; and a method
for projecting thematic roles onto the Paris 7 dependency
bank. We are currently extending the verb classification
approach to integrate thematic grids and working on
evaluating and improving the result. In the long run, we aim
to provide a Propbank style corpus for French to and to
develop a semantic role labeller based on this corpus
Deep analysis of interaction patterns in
texts
In the context of the CCCP-Prosodie project, we showed
that connotation and subjective markers are good evidence for
conflicts between participants on Wikipedia discussion pages.
We observed striking patterns of interaction during
conflicts, especially the alternation of 1st person and 2nd
person subjective markers in negatively connotated
utterances. Further work will involve examine the various
conflicts type, aiming to automatically distinguish
argument-based conflicts from personal ones (ad hominem)
MLIF
TALARIS contributes to ISO TC 37 committee “Terminologies
and other Language Resources”, and more specifically to the
activities of its SC3 “Computer Applications in Terminology”,
and SC4 “Linguistic Resources Management”. Within TC37/SC4,
TALARIS is currently contributing, as project leader, to the
definition and specification of the Multi Lingual Information
Framework (MLIF) [ISO DIS 24616]. MLIF is being designed with
the objective of providing a common abstract model being able
to generate several formats used in the framework of
translation and localization. MLIF will soon be released as
FDIS (Final Draft International Standard) and it should
finally be published as an official ISO Standard within the
first semester of 2011
New clustering quality metrics for the analysis of
complex textual data
Cluster quality evaluation is a key issue for many data
analysis tasks. As we showed in previous work, the classical
distance based quality indices are often strongly biased and
highly dependent on the clustering method. To cope with such
problems, we proposed in earlier work specific
Macro-Recall/Precision and F-measures metrics that exploit
the properties of cluster associated data. However, our more
recent experiments showed that these new metrics failed to
highlight degenerated clustering results when analyzing
complex textual data
New diachronic method for the analysis of slowly
time-varying textual data
The literature taking into account the chronological
aspect in textual information flows focuses on "DataStream"
whose main idea is the "on the fly" management of incoming
data. However the proposed algorithms are intended to treat
very large volumes of data and are thus not optimal for
detecting emergent topics such as, for example, the evolution
of a research theme within bibliographical records. To
address this issue, we proposed a new approach based on our
Multiview Data Analysis Paradigm (MVDA)
New incremental clustering algorithms for the
analysis of highly time-varying textual data
Neural clustering algorithms show high performance in the
general context of the analysis of homogeneous textual
datasets. However, we showed that there is a drastic decrease
of performance of these algorithms, as well as of the more
classical algorithms, when applied to heterogeneous or
polythematic textual datasets. Such result degradation
indicates that most of the exiting clustering methods, even
those that are considered incremental, are not really able to
deal with highly time-varying data
Building up evolving networks of wikis
The WICRI Project aims to explore a new concept of "wikis
network" with adaptive capabilities. In particular, one aim
is to propose strategies for enriching the content of the
wiki network by dynamic integration and exploitation of Web
data. Hence, Web mining represents an important challenge for
enhancing the dynamicity, the flexibility and the scope of
such a network. On the one hand, this process is mandatory
for assisting the potential contributors with elaborated and
reliable redaction guidelines during the network construction
phase. On the other hand, it is essential for supplying
end-users with external information whose added value is to
maintain significant relationships with the semantic context
of the wiki network. Although the WICRI project is still in
his launching phase, our preliminary prototype of "network of
wikis" is already acting as an on-line collaborative research
platform