Section: New Results
Generic methodological results
In the context of our research work on biological questions, we develop concepts and tools in mathematics, statistics and computer science. This paragraph is intended to put emphasis on the most important results obtained by the team during the current year in these disciplins, independently of their biological application.
OpenAlea scientific workflows and grid computing
Participants : Christophe Pradal, Sarah Cohen-Boulakia, Christian Fournier, Didier Parigot [Inria, Zenith] , Patrick Valduriez [Inria, Zenith] .
Plant phenotyping consists in the observation of physical and biochemical traits of plant genotypes in response to environmental conditions. Challenges, in particular in context of climate change and food security, are numerous. High-throughput platforms have been introduced to observe the dynamic growth of a large number of plants in different environmental conditions. Instead of considering a few genotypes at a time (as it is the case when phenomic traits are measured manually), such platforms make it possible to use completely new kinds of approaches. However, the data sets produced by such widely instrumented platforms are huge, constantly augmenting and produced by increasingly complex experiments, reaching a point where distributed computation is mandatory to extract knowledge from data. We design the infrastructure InfraPhenoGrid [26] to efficiently manage data sets produced by the PhenoArch plant phenomics platform in the context of the French Phenome Project. Our solution consists in deploying OpenAlea scientific workflows on a Grid using a middleware, SciFloware, to pilot workflow executions. Our approach is user-friendly in the sense that despite the intrinsic complexity of the infrastructure, running scientific workflows and understanding results obtained (using provenance information) is kept as simple as possible for end-users.
Reproductibility in Scientific workflows
Participants : Christophe Pradal, Sarah Cohen-Boulakia, Jerome Chopard.
With the development of new experimental technologies, biologists are faced with an avalanche of data to be computationally analyzed for scientific advancements and discoveries to emerge. Faced with the complexity of analysis pipelines, the large number of computational tools, and the enormous amount of data to manage, there is compelling evidence that many if not most scientific discoveries will not stand the test of time: increasing the reproducibility of computed results is of paramount importance. In the context of the project 8.2.5.4, we study how scientific workflows can help to improve the reproducibility of computational experiment in the domain of life science. We characterize and define the criteria that need to be catered for by reproducibility-friendly scientific workflow systems, and use such criteria to place several representative and widely used workflow systems and companion tools within such a framework.
Statistical modeling
Participants : Yann Guédon, Jean Peyhardi, Jean-Baptiste Durand Peyhardi, Catherine Trottier [IMAG, Montpellier] .
We develop statistical models and methods for identifying and characterizing developmental patterns in plant phenotyping data. Phenotyping data are very diverse ranging from the tissular to the whole plant scale but are often highly structured in space, time and scale. Problems of interest deal with the definition of new family of statistical models specifically adapted to plant phenotyping data and the design of new methods of inference concerning both model structure, model parameters and latent structure. This is illustrated this year by [18] and [25].
Lossy compression of tree structures
Participants : Christophe Godin, Romain Azaïs, Jean-Baptiste Durand, Alain Jean-Marie.
In in [6], we defined the degree of self-nestedness of a tree as the edit-distance between the considered tree structure and its nearest embedded self-nested version. Indeed, finding the nearest self-nested tree of a structure without more assumptions is conjectured to be an NP-complete or NP-hard problem. We thus introduced a lossy compression method that consists in computing in polynomial time for trees with bounded outdegree the reduction of a self-nested tree that closely approximates the initial tree. This approximation relies on an indel edit distance that allows (recursive) insertion and deletion of leaf vertices only. We showed in a conference paper presented at DCC'2016 [55] with a simulated dataset that the error rate of this lossy compression method is always better than the loss based on the nearest embedded self-nestedness tree [6] while the compression rates are equivalent. This procedure is also a keystone in our new topological clustering algorithm for trees. In addition, we obtained new theoretical results on the combinatorics of self-nested structures and their ability to approximate complex trees in a costless manner [42].
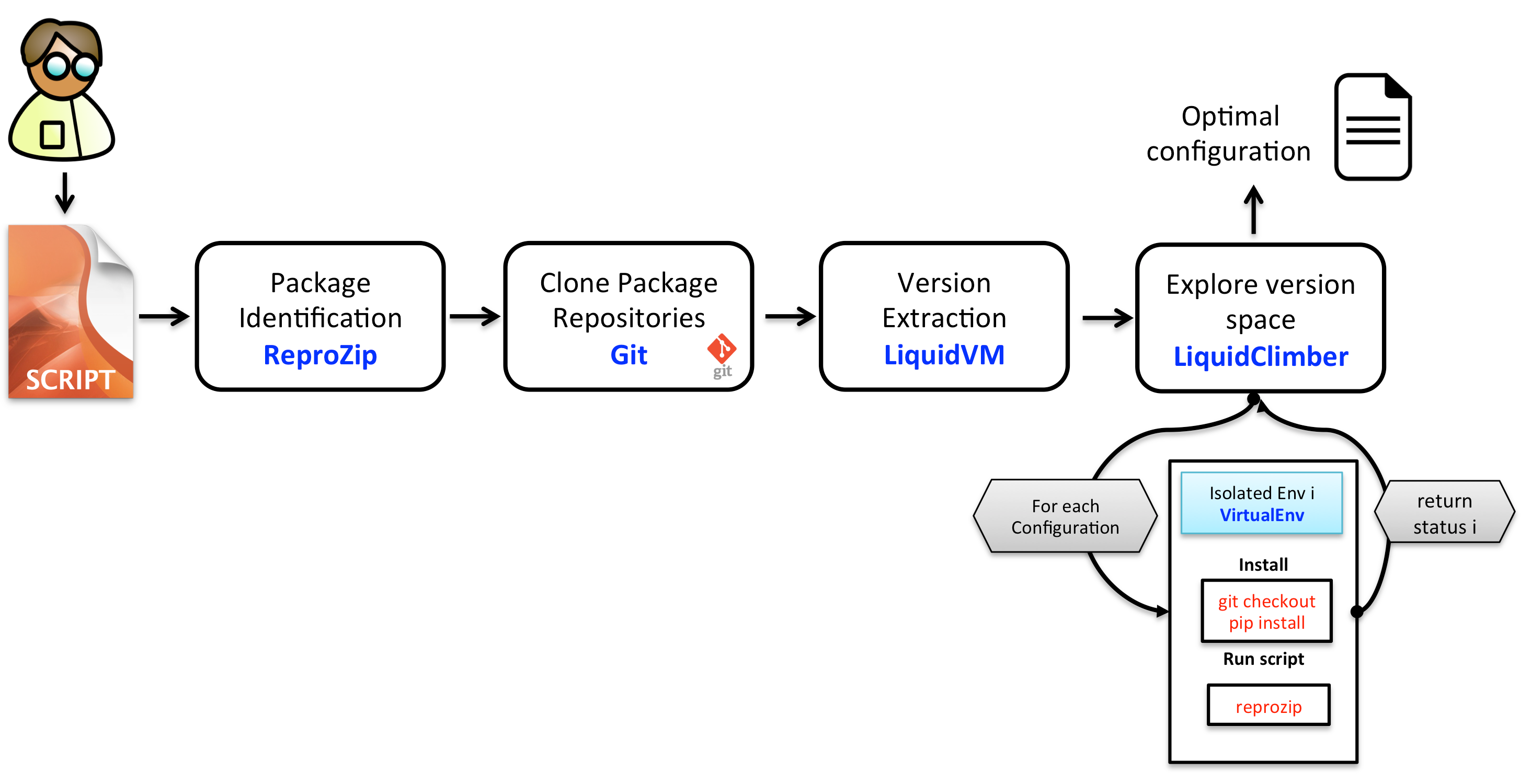
Version climber
Participants : Christophe Padal, Dennis Shasha, Sarah Cohen-Boulakia, Patrick Valduriez.
Imagine you are a data scientist (as many of us are/have become). Systems you build typically require many data sources and many packages (machine learning/data mining, data management, and visualization) to run. Your working configuration will consist of a set of packages each at a particular version. You want to update some packages (software or data) to their most recent possible version, but you want your system to run after the upgrades, thus perhaps entailing changes to the versions of other packages.
One approach is to hope the latest versions of all packages work. If that fails, the fallback is manual trial and error, but that quickly ends in frustration.
We advocate a provenance-style approach in which tools like ptrace and reprozip, combine to enable us to identify version combinations of different packages. Then other tools like pip and VirtualEnv enable us to fetch particular versions of packages and try them in a sandbox-like environment.
Because the space of versions to explore grows exponentially with the number of packages, we have developed a memorizing algorithm that avoids exponential search while still finding an optimum version combination.
Experimental results have been tested (with full reproducibility) on well known packages used in data science to illustrate the effectiveness of our approach as well as life science computational experiment.