
Keywords
Computer Science and Digital Science
- A5.1.1. Engineering of interactive systems
- A5.1.2. Evaluation of interactive systems
- A5.1.9. User and perceptual studies
- A5.3. Image processing and analysis
- A5.4. Computer vision
- A5.5.4. Animation
- A5.6. Virtual reality, augmented reality
- A5.6.1. Virtual reality
- A5.8. Natural language processing
- A6.1.1. Continuous Modeling (PDE, ODE)
- A6.1.4. Multiscale modeling
- A6.1.5. Multiphysics modeling
- A6.2.4. Statistical methods
- A6.3.3. Data processing
- A7.1.3. Graph algorithms
- A9.4. Natural language processing
- A9.7. AI algorithmics
Other Research Topics and Application Domains
- B1.1.8. Mathematical biology
- B1.2. Neuroscience and cognitive science
- B1.2.1. Understanding and simulation of the brain and the nervous system
- B1.2.2. Cognitive science
- B1.2.3. Computational neurosciences
- B2.1. Well being
- B2.5.1. Sensorimotor disabilities
- B2.5.3. Assistance for elderly
- B2.7.2. Health monitoring systems
- B9.1.2. Serious games
- B9.3. Medias
- B9.5.2. Mathematics
- B9.5.3. Physics
- B9.6.8. Linguistics
- B9.9. Ethics
1 Team members, visitors, external collaborators
Research Scientists
- Bruno Cessac [Team leader, INRIA, Senior Researcher, HDR]
- Pierre Kornprobst [INRIA, Senior Researcher, HDR]
- Hui-Yin Wu [INRIA, ISFP]
PhD Students
- Alexandre Bonlarron [INRIA]
- Johanna Delachambre [INRIA]
- Simone Ebert [UNIV COTE D'AZUR]
- Jerome Emonet [INRIA]
- Franz Franco Gallo [INRIA, from Nov 2022]
- Florent Robert [UNIV COTE D'AZUR]
Technical Staff
- Clement Bergman [INRIA, Engineer, from Nov 2022]
- Jeremy Termoz-Masson [INRIA, Engineer]
Interns and Apprentices
- Sebastian Gallardo Diaz [INRIA]
Administrative Assistant
- Marie-Cecile Lafont [INRIA]
2 Overall objectives
Vision is a key function to sense our world and perform complex tasks. It has high sensitivity and strong reliability, even though most of its input is noisy, changing, and ambiguous. A better understanding of how biological vision works opens up scientific challenges as well as promising technological, medical and societal breakthroughs. Fundamental aspects such as understanding how a visual scene is encoded by the retina into spike trains, transmitted to the visual cortex via the optic nerve through the thalamus, decoded in a fast and efficient way, and then creating a sense of perception, offers perspectives in research and technological developments for current and future generations.
Vision is not always functional though. Sometimes, "something" goes wrong. Although many visual impairments such as myopia, hypermetropia, cataract, can be cured by glasses, contact lenses, or other means like medicine or surgery, pathologies impairing the retina such as Age-Related Macular Degeneration (AMD) and Retinis Pigmentosa (RP) can't be fixed with these standard treatments 33. They result in a progressive degradation of vision (Figure 1), up to a stage of low vision (visual acuity of less than 6/18 to light perception, or a visual field of less than 10 degrees from the point of fixation) up to blindness. Thus, a person with low vision must learn to adjust to their pathology. Progress in research and technology can help them. Considering the aging of the population in developed countries and its strong correlation with the prevalence of eye diseases, low vision has already become a major societal problem.

Figure depicts a picture of a person through the eyes of a person with CFL (a scotoma blurs the image).
Central blind spot (i.e., scotoma), as perceived by an individual suffering from Central Field Loss (CFL) when looking at someone's face.
In this context, the Biovision team's research revolves around the central theme biological vision and perception, and the impact of low vision conditions. Our strategy is based upon four cornerstones: To model, to assist diagnosis, to aid visual activities like reading, and to enable personalize content creation. We aim to develop fundamental research as well as technology transfer along three entangled axes of research:
- Axis 1: Modelling the retina and the primary visual system.
- Axis 2: Diagnosis, rehabilitation, and low-vision aids.
- Axis 3: Visual media analysis and creation.
These axes form a stable, three-pillared basis for our research activities, giving our team an original combination in expertise: neuroscience modelling, computer vision, Virtual and Augmented Reality (XR), and media analysis and creation. Our research themes require strong interactions with experimental neuroscientists, modellers, ophtalmologists and patients, constituting a large network of national and international collaborators. Biovision is therefore a strongly multi-disciplinary team. We publish in international reviews and conferences in several fields including neuroscience, low vision, mathematics, physics, computer vision, multimedia, computer graphics, and human-computer interactions.
3 Research program
3.1 Axis 1 - Modelling the retina and the primary visual system.
In collaboration with neuroscience labs, we derive phenomenological equations and analyse them mathematically by adopting methods from theoretical physics or mathematics (Figure 2). We also develop simulation platforms like Pranas or Macular, helping us confront theoretical predictions to numerical simulations, or allowing researchers to perform in silico experimentation under conditions rarely accessible to experimentalists (such as simultaneously recording the retina layers and the primary visual cortex1 (V1)). Specifically, our research focuses on the modelling and mathematical study of:
- Multi-scale dynamics of the retina in the presence of spatio-temporal stimuli;
- Response to motion, anticipation and surprise in the early visual system;
- Spatio-temporal coding and decoding of visual scenes by spike trains;
- Retinal pathologies.
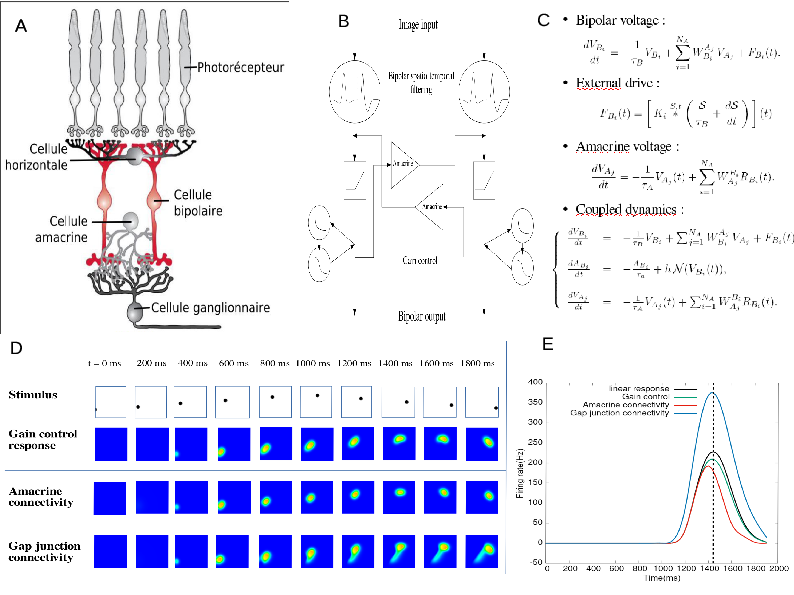
The process of retina modelling. A) Inspired from the retina structure in biology, we, B) designe a simplified architecture keeping retina components that we want to better understand. C) From this we derive equations that we can study mathematically and/or with numerical simulations (D). In E we see an example. Here, our retina model's shows how the response to a parabolic motion where the peak of response resulting from amacrine cells connectivity or gain control is in advance with respect to the peak in response without these mechanisms. This illustrates retinal anticipation.
The process of retina modelling. A) The retina structure from biology. B) Designing a simplified architecture keeping retina components that we want to better understand (here, the role of Amacrine cells in motion anticipation); C) Deriving mathematical equations from A and B. D, E). Results from numerical modelling and mathematical modelling. Here, our retina model's response to a parabolic motion where the peak of response resulting from amacrine cells connectivity or gain control is in advance with respect to the peak in response without these mechanisms. This illustrates retinal anticipation.
3.2 Axis 2 - Diagnosis, rehabilitation, and low-vision aids.
In collaboration with low vision clinical centers and cognitive science labs, we develop computer science methods, open software and toolboxes to assist low vision patients, with a particular focus on Age-Related Macular Degeneration2. As AMD patients still have a plastic and functional vision in their peripheral visual field 38 they must develop efficient “Eccentric Viewing" (EV) to adapt to the central blind zone (scotoma) and to direct gaze away from the object they want to identify 43. Commonly proposed assistance tools involve visual rehabilitation methods 40 and visual aids that usually consist of magnifiers 34.
Our main research goals are:
- Understanding the relations between anatomo-functional and behavioral observations;
- Diagnosis from reading performance screening and oculomotor behavior analysis;
- Personalized and gamified rehabilitation for training eccentric viewing in VR;
- Personalized visual aid systems for daily living activities.

Figure depicts three images as described in the caption.
Multiple methodologies in graphics and image processing have applications towards low-vision technologies including (a) 3D virtual environments for studies of user perception and behavior, and creating 3D stimuli for model testing, (b) image enhancement techniques to magnify and increase visibility of contours of objects and people, and (c) personalization of media content such as text in 360 degrees visual space using VR headsets.
3.3 Axis 3 - Visual media analysis and creation.
We investigate the impact of visual media design on user experience and perception, and propose assisted creativity tools for creating personalized and adapted media content. We employ computer vision and deep learning techniques for media understanding in film and in complex documents like newspapers. We deploy this understanding in new media platforms such as virtual and augmented reality for applications in low-vision training, accessible media design, and generation of 3D visual stimuli:
- Accessible / personalized media design for low vision training and reading platforms;
- Assisted creativity tools for virtual and augmented reality;
- Visual stimuli design and generation for psycophysics studies and visual system modelling;
- Visual media understanding and gender representation in film.
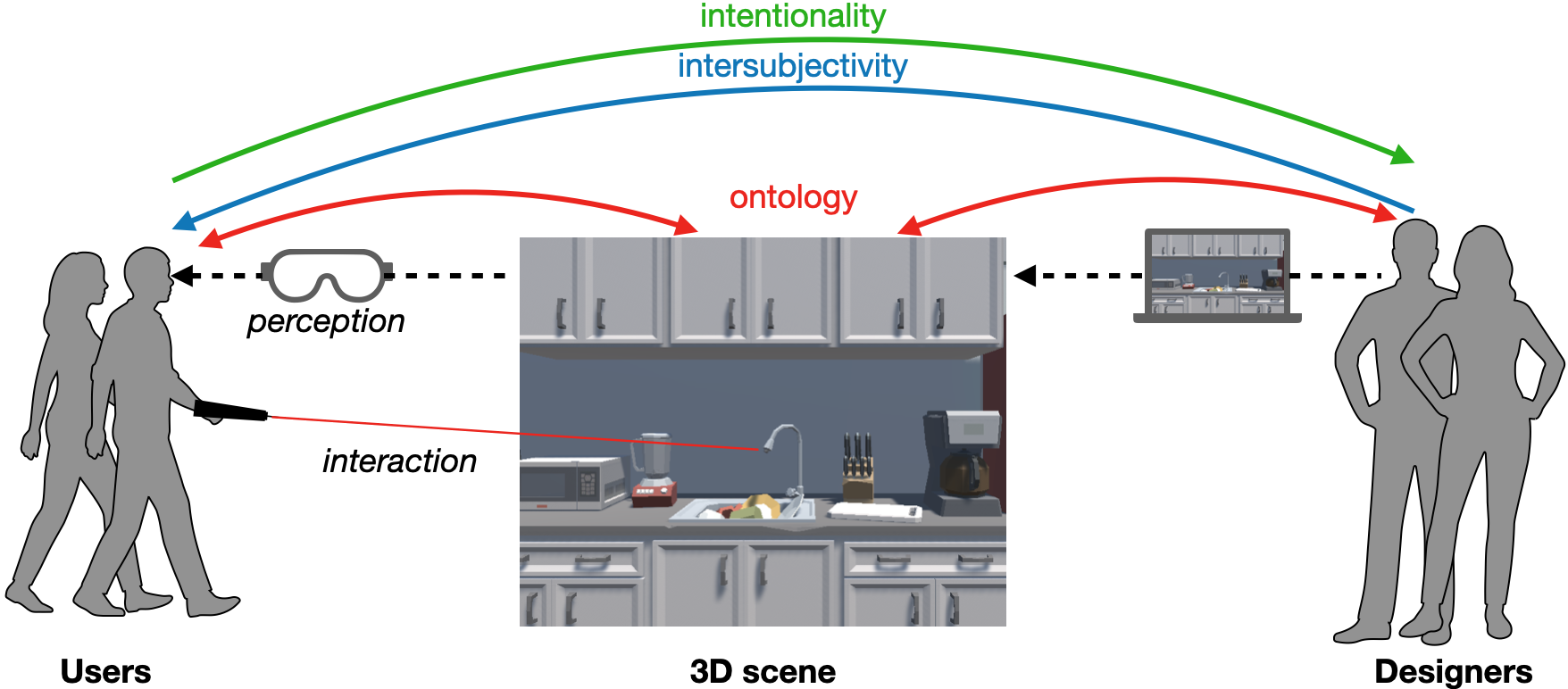
On the left we have users, in the middle, the 3D scene, and on the right designers. Designers create the 3D scene through a computer interface and users interact with it through headsets and controllers. We see three main gaps of perception: ontology between the scene and its various users, intersubjectivity when communicating interactive possibilities from the designer and user, and intentionality when designers analyze user intentions
4 Application domains
4.1 Applications of low-vision studies
- Cognitive research: Virtual reality technology represents a new opportunity to conduct cognitive and behavioural research in virtual environments where all parameters can be psychophysically controlled. In the scope of ANR DEVISE, we are currently developing and using the PTVR software (Perception Toolbox for Virtual Reality) 21 to develop our own experimental protocols to study low vision. However, we believe that the potential of PTVR is much larger as it could be useful to any researcher familiar with Python programming willing to create and analyze a sophisticated experiment in VR with parsimonious code.
- Serious games: Serious games use game mechanics in order to achieve goals such as in training, education, or awareness. In our context, we want to explore serious games as a way to help low-vision patients in performing rehabilitation exercises. Virtual and augmented reality technology is a promising platform to develop such rehabilitation exercises targeted to specific pathologies due to their potential to create fully immersive environments, or inject additional information in the real world. For example, with Age-Related Macular Degeneration (AMD), our objective is to propose solutions allowing rehabilitation of visuo-perceptual-motor functions to optimally use residual portions of the peripheral retina defined from anatomo-functional exams 28.
- Vision aid-systems: A variety of aids for low-vision people are already on the market. They use various kinds of desktop (e.g., CCTVs), handheld (mobile applications), or wearable (e.g. OxSight, Helios) technologies, and offer different functionalities including magnification, image enhancement, text to speech, face and object recognition. Our goal is to design new solutions allowing autonomous interaction primarily using mixed reality – virtual and augmented reality. This technology could offer new affordable solutions developed in synergy with rehabilitation protocols to provide personalized adaptations and guidance.
4.2 Applications of vision modeling studies
-
Neuroscience research. Making in-silico experiments is a way to reduce the experimental costs, to test hypotheses and design models, and to test algorithms. Our goal is to develop a large-scale simulations platform of the normal and impaired retinas. This platefom, called Macular, allows to test hypotheses on the retina functions in normal vision (such as the role of amacrine cells in motion anticipation 50, or the expected effects of pharmacology on retina dynamics 11). It is also to mimic specific degeneracies or pharmacologically induced impairments 25, as well as to emulate electric stimulation by prostheses.
In addition, the platform provides a realistic entry to models or simulators of the thalamus or the visual cortex, in contrast to the entries usually considered in modeling studies.
- Education. Macular is also targeted as a useful tool for educational purposes, illustrating for students how the retina works and responds to visual stimuli.
4.3 Applications of visual media analysis and creation
- Engineering immersive interactive storytelling platforms. With the sharp rise in popularity of immersive virtual and augmented reality technologies, it is thus important to acknowledge their strong potential to create engaging, embodied experiences. To arrive at this goal involves investigating the impact of virtual and augmented reality platforms from an interactivity and immersivity perspective: how do people parse visual information, react, and respond in the face of content, in face of media. 10, 18, 17, 24
- Personalized content creation and assisted creativity. Models of user perception can be integrated in tools for content creators, such as to simulate low-vision conditions to aid in the design of accessible spaces and media, and to diversify immersive scenarios used for studying user perception, for entertainment, and for rehabilitation 9, 15.
- Media studies and social awareness. Investigating interpretable models of media analysis will allow us to provide tools to conduct qualitative media studies on large amounts of data in relation to existing societal challenges and issues. This includes understanding the impact of media design on accessibility for patients of low-vision, as well as raising awareness towards biases in media 52 and existing media analysis tools from deep learning paradigms 19.
5 Social and environmental responsibility
The research themes in the Biovision team has direct social impacts on two fronts:
- Low vision: we work in partnership with neuroscientists and ophthalmologists to design technologies for the diagnosis and rehabilitation of low-vision pathologies, addressing a strong societal challenge.
- Accessibility: in concert with researchers in media studies, we tackle the social challenge of designing accessible media, including for the population with visual impairments, as well as to address media bias both in content design as well as in machine learning approaches to content analysis.
6 New software and platforms
6.1 New software
6.1.1 Macular
-
Name:
Numerical platform for simulations of the primary visual system in normal and pathological conditions
-
Keywords:
Retina, Vision, Neurosciences
-
Scientific Description:
At the heart of Macular is an object called "Cell". Basically these "cells" are inspired by biological cells, but it's more general than that. It can also be a group of cells of the same type, a field generated by a large number of cells (for example a cortical column), or an electrode in a retinal prosthesis. A cell is defined by internal variables (evolving over time), internal parameters (adjusted by cursors), a dynamic evolution (described by a set of differential equations) and inputs. Inputs can come from an external visual scene or from other synaptically connected cells. Synapses are also Macular objects defined by specific variables, parameters, and equations. Cells of the same type are connected in layers according to a graph with a specific type of synapses (intra-layer connectivity). Cells of a different type can also be connected via synapses (inter-layer connectivity).
All the information concerning the types of cells, their inputs, their synapses and the organization of the layers are stored in a file of type .mac (for "macular") defining what we call a "scenario". Different types of scenarios are offered to the user, which they can load and play, while modifying the parameters and viewing the variables (see technical section).
Macular is built around a central idea: its use and its graphical interface can evolve according to the user's objectives. It can therefore be used in user-designed scenarios, such as simulation of retinal waves, simulation of retinal and cortical responses to prosthetic stimulation, study of pharmacological impact on retinal response, etc. The user can design their own scenarios using the Macular Template Engine (see technical section).
-
Functional Description:
Macular is a simulation platform for the retina and the primary visual cortex, designed to reproduce the response to visual stimuli or to electrical stimuli produced by retinal prostheses, in normal vision conditions, or altered (pharmacology, pathology, development).
-
Release Contributions:
First release.
-
News of the Year:
First release, APP
- URL:
-
Contact:
Bruno Cessac
-
Participants:
Bruno Cessac, Evgenia Kartsaki, Selma Souihel, Teva Andreoletti, Alex Ye, Sebastian Gallardo Diaz, Ghada Bahloul, Tristan Cabel, Erwan Demairy, Pierre Fernique, Thibaud Kloczko, Come Le Breton, Jonathan Levy, Nicolas Niclausse, Jean-Luc Szpyrka, Julien Wintz, Carlos Zubiaga Pena
6.1.2 GUsT-3D
-
Name:
Guided User Tasks Unity plugin for 3D virtual reality environments
-
Keywords:
3D, Virtual reality, Interactive Scenarios, Ontologies, User study
-
Functional Description:
We present the GUsT-3D framework for designing Guided User Tasks in embodied VR experiences, i.e., tasks that require the user to carry out a series of interactions guided by the constraints of the 3D scene. GUsT-3D is implemented as a set of tools that support a 4-step workflow to :
(1) annotate entities in the scene with names, navigation, and interaction possibilities, (2) define user tasks with interactive and timing constraints, (3) manage scene changes, task progress, and user behavior logging in real-time, and (4) conduct post-scenario analysis through spatio-temporal queries on user logs, and visualizing scene entity relations through a scene graph.
-
Contact:
Hui-Yin Wu
-
Participants:
Hui-Yin Wu, Marco Alba Winckler, Lucile Sassatelli, Florent Robert
-
Partner:
I3S
6.1.3 PTVR
-
Name:
Perception Toolbox for Virtual Reality
-
Keywords:
Visual perception, Behavioral science, Virtual reality
-
Functional Description:
Some of the main assets of PTVR are: (i) The “Perimetric” coordinate system allows users to place their stimuli in 3D easily, (ii) Intuitive ways of dealing with visual angles in 3D, (iii) Possibility to define “flat screens” to replicate and extend standard experiments made on 2D screens of monitors, (iv) Save experimental results and behavioral data such as head and gaze tracking. (v) User-friendly documentation with many animated figures in 3D to easily visualize 3D subtleties, (vi) Many “demo” scripts whose observation in the VR headset is very didactic to learn using PTVR, (vii) Focus on implementing standard and innovative clinical tools for visuomotor testing and visuomotor readaptation (notably for low vision).
-
News of the Year:
The first release of PTVR was presented in August 2022 at the conference ECVP 21
- URL:
-
Authors:
Eric Castet, Christophe Hugon, Jeremy Termoz-Masson, Johanna Delachambre, Hui-Yin Wu, Pierre Kornprobst
-
Contact:
Pierre Kornprobst
-
Partner:
Aix-Marseille Université - CNRS Laboratoire de Psychologie Cognitive - UMR 7290 - Team ‘Perception and attention’
6.2 New platforms
Members of Biovision are marked with a .
6.2.1 CREATTIVE3D platform for navigation studies in VR
Participants: Hui-Yin Wu (coordinator), Lucile Sassatelli, Marco Winckler, Florent Robert (PhD student and lead developer).
As part of ANR CREATTIVE3D, the Biovision team has established a techonological platform in the Kahn immersive space including:
- a 40 tracked space for the Vive Pro Eye virtual reality headset with 4-8 infra-red base stations.
- GUsT-3D software 6.1.2 under Unity for the creation, management, logging, analysis, and scene graph visualization of interactive immersive experiences
- Vive Pro Eye headset integrated sensors including gyroscope and accelerometers, spatial tracking through base stations, and 120 Hz eye tracker
- External sensors including XSens Awinda Starter inertia-based motion capture costumes and Shimmer GSR physiological sensors
7 New results
We present here the new scientific results of the team over the course of the year. For each entry, members of Biovision are marked with a .
7.1 Modelling the retina and the primary visual system
7.1.1 Temporal pattern recognition in retinal ganglion cells is mediated by dynamical inhibitory synapses
Participants: Simone Ebert, Thomas Buffet, Semihcan Sermet, Olivier Marre, Bruno Cessac.
1 Institut de la Vision, Sorbonne Université, Paris, France.
Description: A long standing hypothesis is that retinal ganglion cells, the retinal output, do not signal the visual scene per se, but rather surprising events, eg. mismatches between observation and expectation formed by previous inputs. A striking example of this is the Omitted Stimulus Response (OSR): when a regular sequence of flashes suddenly ends, the retina emits a large response signaling the missing stimulus, and the latency of this response shifts with the period of the flash sequence to respond to the omitted stimulus. However, the mechanism behind this predictive latency shift remains unclear. Here we show that inhibition is necessary for this latency shift. Using a combination of modeling and experiments, we show that latency shift of the OSR in ganglion cells is obtained by amacrine cells with inhibitory synapses. Inhibition delays the response at the end of the sequence, and the depressing synapse shifts this delay as a function of the frequency of the flash sequence. High frequency sequence induce a strong depression of the inhibitory synapse, a weak inhibitory input and thus a small increase in the latency, while low frequency inputs induce a small depression of the inhibitory synapse, a strong inhibitory input and therefore a large increase in latency. We build a circuit model that reproduces our experimental findings and generates new predictions, that we confirm by further experiments. Since depressing inhibitory synapses are ubiquitous in sensory circuits, our results suggest they could be a key component to generate the predictive responses that have been observed in several brain areas.
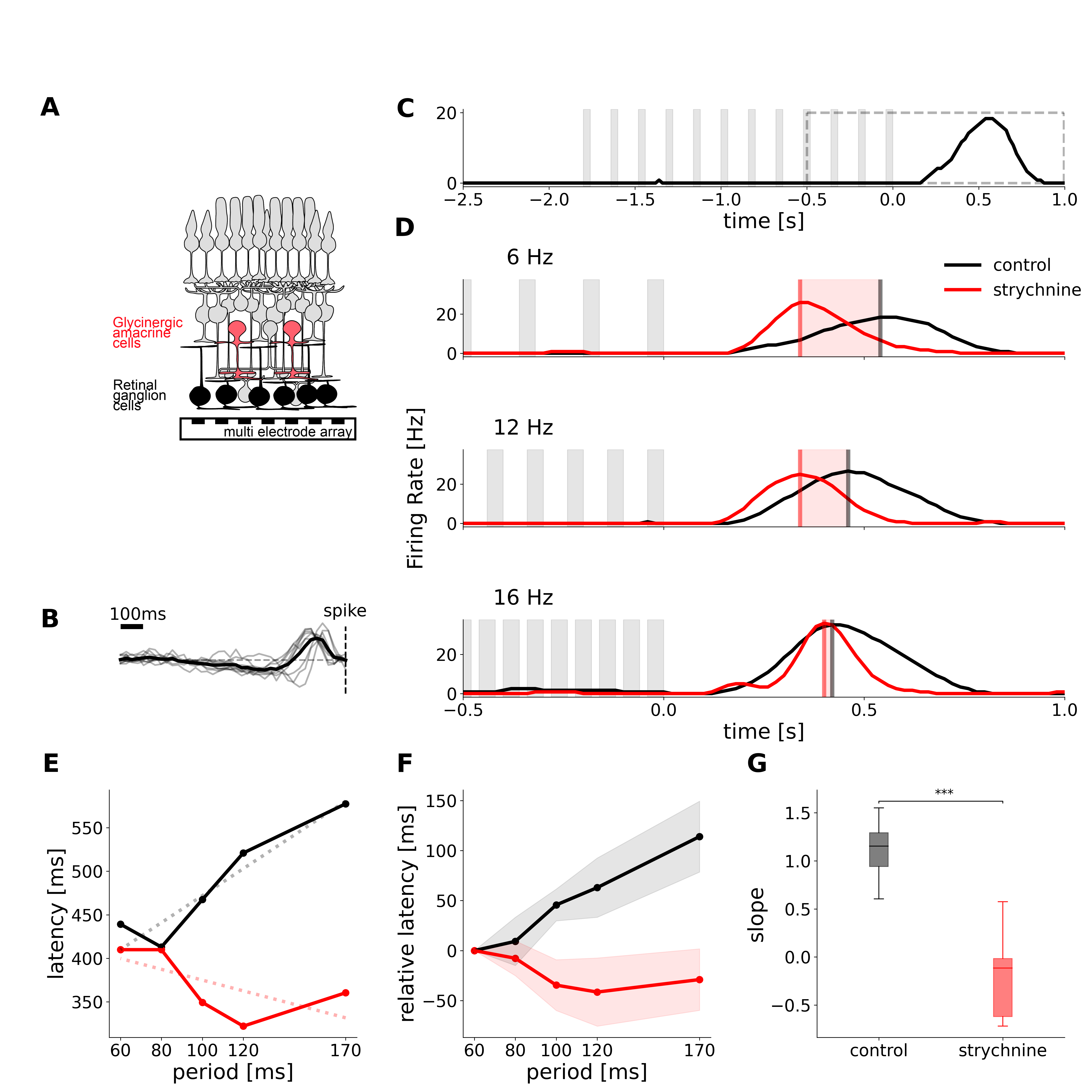
This figure shows a schematic of the retina, experimental recordings of the Omitted Stimulus Response.in normal conditions and under application of strychnine which blocks glycine.
This work has been presented in the conferences ICMNS 2022 – 2022 International Conference on Mathematical Neuroscience (on line) 27, NEUROMOD Meeting 2022 (Antibes) 32 AREADNE 2022 (Santorini, Greece) 31, Dendrites 2022 – Dentritic, anatomy, molecules and functions – Embo workshop, (Heraklion, Greece) 30 and will be soon submitted to the journal eLife.
7.1.2 Receptive field estimation in large visual neuron assemblies using a super resolution approach
Participants: Daniela Pamplona, Gerrit Hilgen, Matthias H. Hennig, Bruno Cessac, Evelyne Sernagor, Pierre Kornprobst.
1 Ecole Nationale Supérieure de Techniques Avancées, Institut Polytechnique de Paris, France
2 Institute of Neuroscience (ION), United Kingdom
3 Institute for Adaptive and Neural Computation, University of Edinburgh, United Kingdom
Description: Computing the Spike-Triggered Average (STA) is a simple method to estimate linear receptive field (RF) in sensory neurons. For random, uncorrelated stimuli the STA provides an unbiased RF estimate, but in practice, white noise at high resolution is not an optimal stimulus choice as it usually evokes only weak responses. Therefore, for a visual stimulus, images of randomly modulated blocks of pixels are often used. This solution naturally limits the resolution at which an RF can be measured. Here we present a simple super-resolution technique that can be overcome these limitations. We define a novel stimulus type, the shifted white noise (SWN), by introducing random spatial shifts in the usual stimulus in order to increase the resolution of the measurements. In simulated data we show that the average error using the SWN was 1.7 times smaller than when using the classical stimulus, with successful mapping of 2.3 times more neurons, covering a broader range of RF sizes. Moreover, successful RF mapping was achieved with brief recordings of light responses, lasting only about one minute of activity, which is more than 10 times more efficient than the classical white noise stimulus. In recordings from mouse retinal ganglion cells with large scale multi-electrode arrays, we successfully mapped 21 times more RF than when using the traditional white noise stimuli. In summary, randomly shifting the usual white noise stimulus significantly improves RF estimation, and requires only short recordings.
Figure 6 illustrates our method. This paper has been published in Journal of Neurophysiology14
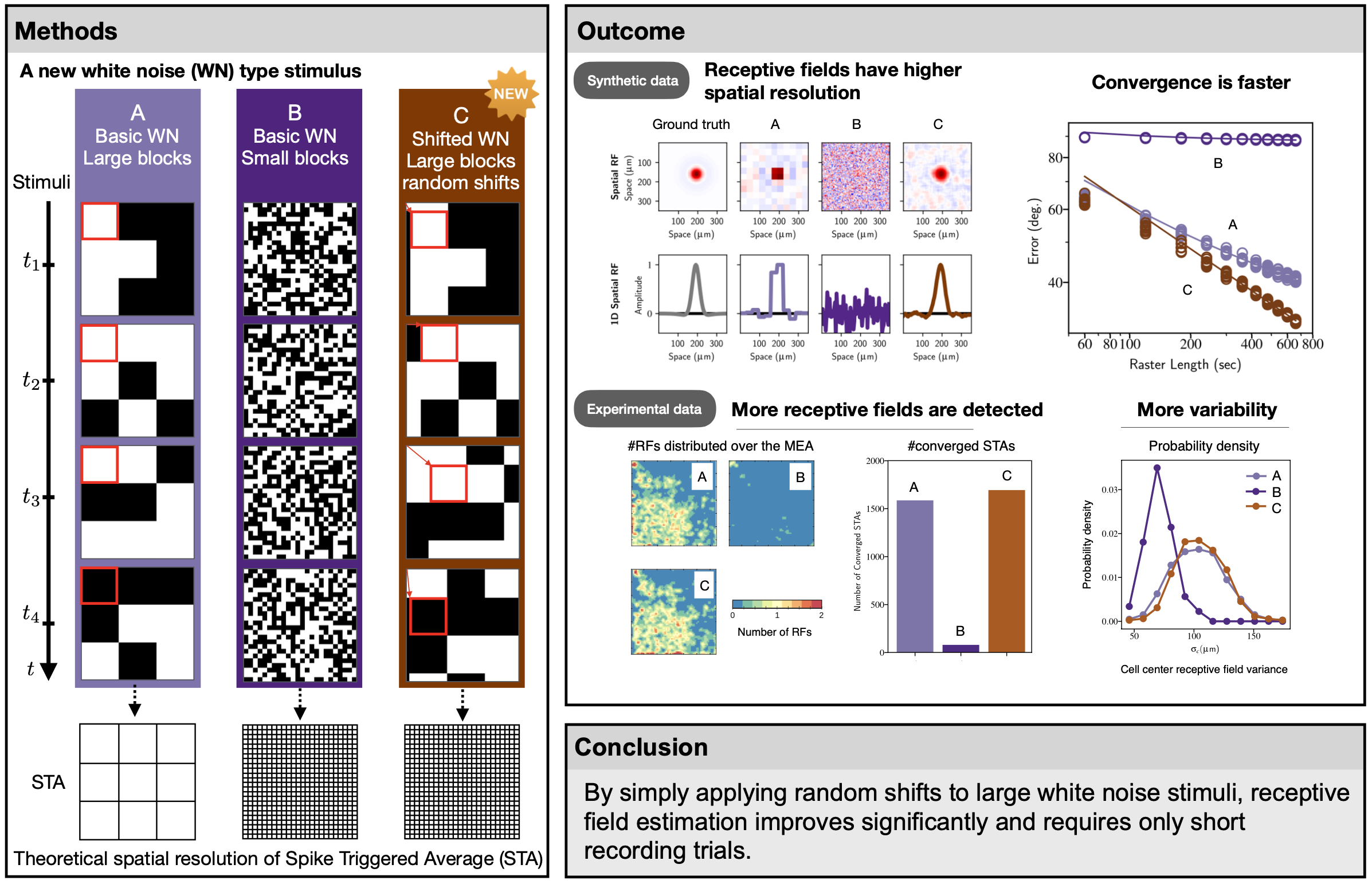
This figure illustrates how one estimates the receptive field of retinal ganglion cells with our approach. One presents a sequences of images composed of black and white squares of fixed size (checker board) which, in addition and in contrast to classical methods, are randomly shifted vertically and horizontally. As we show, this largely improves the resolution of the computed receptive field.
Graphical abstract of receptive field estimation in large visual neuron assemblies using a super resolution approach.
7.1.3 Retinal processing: insights from mathematical modelling
Participants: Bruno Cessac.
Description: The retina is the entrance of the visual system. Although based on common biophysical principles the dynamics of retinal neurons is quite different from their cortical counterparts, raising interesting problems for modellers. In this work we have addressed mathematically stated questions in this spirit.
-
How does the structure of the retina, in particular, amacrine lateral connectivity condition the retinal response to dynamic stimuli ? With the help of a dynamical model based on the layered structure of the retina (Fig. 7) this question is addressed at two levels.
- Level 1. Single cell response to stimuli. Using methods from dynamical systems theory, we are able to compute the receptive field of Ganglion cells resulting from the layered structure of Fig. 7. This is expressed in terms of an evolution operator whose eigenmodes characterise the response of Ganglion cells to spatio-temporal stimuli with potential mechanisms such as resonances, waves of activity induced by a propagating stimulus. We also discuss the effect of non linear rectification on the receptive field.
- Level 2. Collective response to stimuli and spike statistics. What is the structure of the spatio-temporal correlations induced by the conjunction of the spatio-temporal stimulus and the retinal network, in particular, the amacrine lateral connectivity ? While the overlap of BCells receptive field has a tendency to correlate Ganglion cells activity, it is usually believed that the amacrine network has the effect to decorrelate these activities. We investigate this aspect mathematically and show that this decorrelation happens only under very specific hypotheses on the amacrine network. In contrast, we show how non linearities in dynamics can play a significant role in decorrelation.
- How could spatio-temporal stimuli correlations and retinal network dynamics shape the spike train correlations at the output of the retina ? Here, we review some recent results in our group showing how the concept of spatio-temporal Gibbs distributions and linear response theory can be used to construct canonical probability distributions for spike train statistics. In this setting, one establishes a linear response for a network of interacting spiking cells, that can mimic a set of RG cells coupled via effective interactions corresponding to the A cells network influence. This linear response theory not only gives the effect of a non stationary stimulus to first order spike statistics (firing rates) but also its effect on higher order correlations.
- We also briefly discuss some potential consequences of these results. Retinal prostheses; Convolutional networks, Implications for cortical models, Neuro-geometry.
Figure 7 illustrates the retina model used to develop our results. For more details see our paper published in J. Imaging, special issue "Mathematical Modeling of Human Vision and its Application to Image Processing", 202112.

Structure of the retina model used in the paper. A moving object moves along a trajectory. Its image is projected by the eye optics to the upper retina layers (Photoreceptors and H cells) and stimulates them. Then the layers of Bipolar (B cells), Amacrines (A Cells) and Ganglion (G cells), process this signal which is eventually converted into a spike train sent to the visual cortex.
7.1.4 The non linear dynamics of retinal waves
Participants: Bruno Cessac, Dora Matzakou-Karvouniari.
1 EURECOM, Sophia Antipolis, France.
Description: We investigate the dynamics of stage II retinal waves via a dynamical system model, grounded on biophysics, and analyzed with bifurcation theory. We model in detail the mutual cholinergic coupling between Starburst Amacrine Cells (SACs).
We show how the nonlinear cells coupling and bifurcation structure explain how waves start, propagate, interact and stop. We argue that the dynamics of SACs waves is essentially controlled by two parameters slowly evolving in time: one, , controlling the excitatory cholinergic cells coupling, and the other, , controlling cell's hyperpolarisation and refractoriness. Thanks to a thorough bifurcation diagram in the space , we actually arrive at a quite surprising and somewhat counter intuitive result: mostly, the variety observed in waves dynamics comes from the fact that they start in a tiny region in the space delimited by bifurcation lines, where waves initiation is quite sensitive to perturbations such as noise. Although this region is tight, the slow dynamics returns to it in a recurrent way, regenerating the potentiality to trigger new waves sensitive to perturbations.
In addition, this scenario holds on an interval of acetylcholine coupling compatible with the variations observed in experimental studies. We derive transport equations for , now considered as propagating fields shaping waves dynamics. From this, we are able to compute the wave speed as a function of acetylcholine coupling, as well as to show the existence of a critical value of this coupling, below which no wave can propagate. As we argue, these transport equations bare interesting analogies with the Kardar-Parisi-Zhang (KPZ) equations of interface growth on one hand, and Self-Organized Criticality on the other hand, opening up perspectives for future research. Figure 8 illustrates our results.
This paper has been published in Physica D, 11.
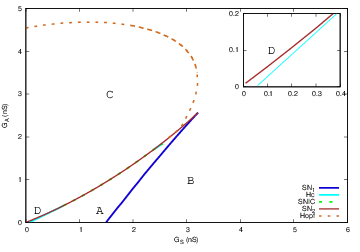
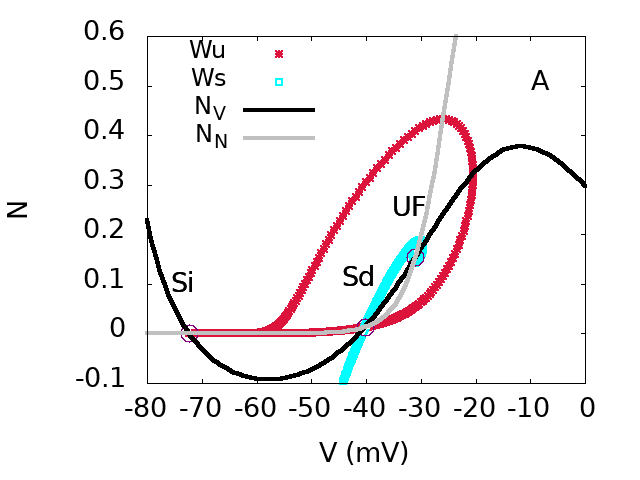
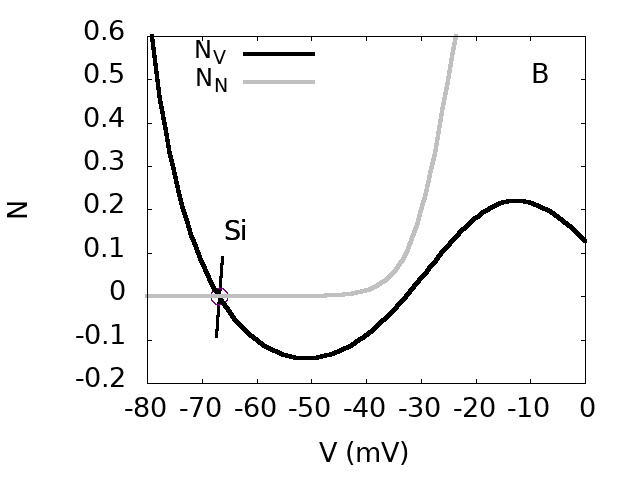
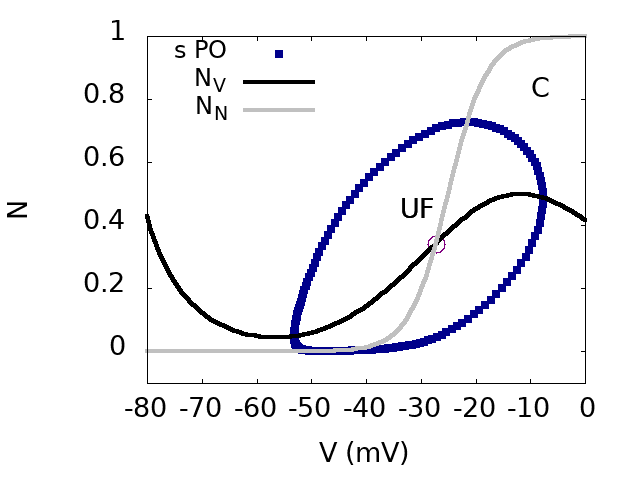
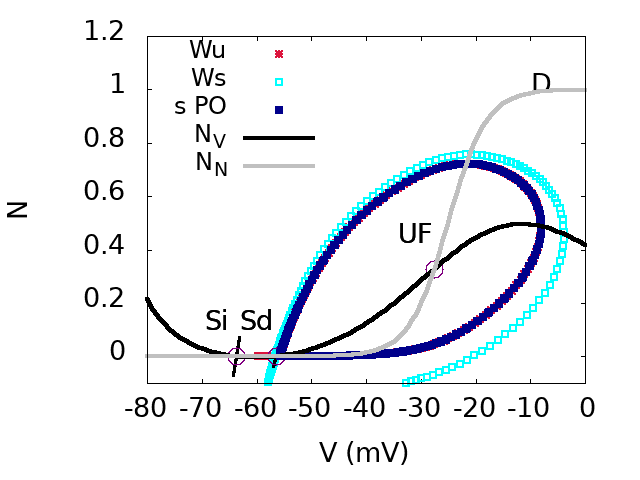
Top. bifurcation diagram of the SACs model in the plane GSG_S (effective sAHP conductance) and GAG_A (effective Ach conductance). Inset: Zoom on region D. Bottom: From top to bottom, from left to right. Phase portraits of regions A,B,D,C.: This figures show the bifurcation diagram of the SACs model in the plane GSG_S (effective sAHP conductance) and GAG_A (effective Ach conductance). There are four regions A,B,C,D corresponding to different phase portraits. In region AA, there is a stable fixed point, corresponding to a rest state, and an unstable focus, separated by a Saddle point whose stable and unstable manifolds are shown. In region BB, there is a unique stable fixed point, a rest state. In region CC, there is a stable periodic orbit corresponding to fast oscillations in the voltage and activation variable . Finally, in region DD, there is a stable fixed point Si, corresponding to a rest state, and a stable periodic orbit. These two attractors are separated by a Saddle point (Sd). Region DD is very narrow in the parameters space (and hardly visible on the diagram at this scale). This is nevertheless an essential zone as discussed in the paper.
Top. bifurcation diagram of the SACs model in the plane GSG_S (effective sAHP conductance) and GAG_A (effective Ach conductance). Inset: Zoom on region D. Bottom: From top to bottom, from left to right. Phase portraits of regions A,B,D,C.: This figures show the bifurcation diagram of the SACs model in the plane GSG_S (effective sAHP conductance) and GAG_A (effective Ach conductance). There are four regions A,B,C,D corresponding to different phase portraits. In region AA, there is a stable fixed point, corresponding to a rest state, and an unstable focus, separated by a Saddle point whose stable and unstable manifolds are shown. In region BB, there is a unique stable fixed point, a rest state. In region CC, there is a stable periodic orbit corresponding to fast oscillations in the voltage and activation variable . Finally, in region DD, there is a stable fixed point Si, corresponding to a rest state, and a stable periodic orbit. These two attractors are separated by a Saddle point (Sd). Region DD is very narrow in the parameters space (and hardly visible on the diagram at this scale). This is nevertheless an essential zone as discussed in the paper.
7.1.5 A novel approach to the functional classification of retinal ganglion cells
Participants: Gerrit Hilgen, Evgenia Kartsaki, Viktoriia Kartysh, Bruno Cessac, Evelyne Sernagor.
1 Biosciences Institute, Newcastle University, Newcastle upon Tyne, UK
2 Health & Life Sciences, Applied Sciences, Northumbria University, Newcastle upon Tyne UK
3 Ludwig Boltzmann Institute for Rare and Undiagnosed Diseases (LBI-RUD), 1090 Vienna, Austria
4 Research Centre for Molecular Medicine (CeMM) of the Austrian Academy of Sciences, 1090 Vienna, Austria
5 SED INRIA Sophia-Antipolis
Description: Retinal neurons come in remarkable diversity based on structure, function and genetic identity. Classifying these cells is a challenging task, requiring multimodal methodology. Here, we introduce a novel approach for retinal ganglion cell (RGC) classification, based on pharmacogenetics combined with immunohistochemistry and large-scale retinal electrophysiology. Our novel strategy allows grouping of cells sharing gene expression and understanding how these cell classes respond to basic and complex visual scenes. Our approach consists of increasing the firing level of RGCs co-expressing a certain gene (Scnn1a or Grik4) using excitatory DREADDs (Designer Receptors Exclusively Activated by Designer Drugs) and then correlate the location of these cells with post hoc immunostaining, to unequivocally characterize anatomical and functional features of these two groups. We grouped these isolated RGC responses into multiple clusters based on the similarity of their spike trains. With our approach, combined with immunohistochemistry, we were able to extend the pre-existing list of Grik4 expressing RGC types to a total of 8 and, for the first time, we provide a phenotypical description of 14 Scnn1a-expressing RGCs. The insights and methods gained here can guide not only RGC classification but neuronal classification challenges in other brain regions as well.
Figure 9 illustrates our results. This paper has been published in Royal Society Open Biology13.
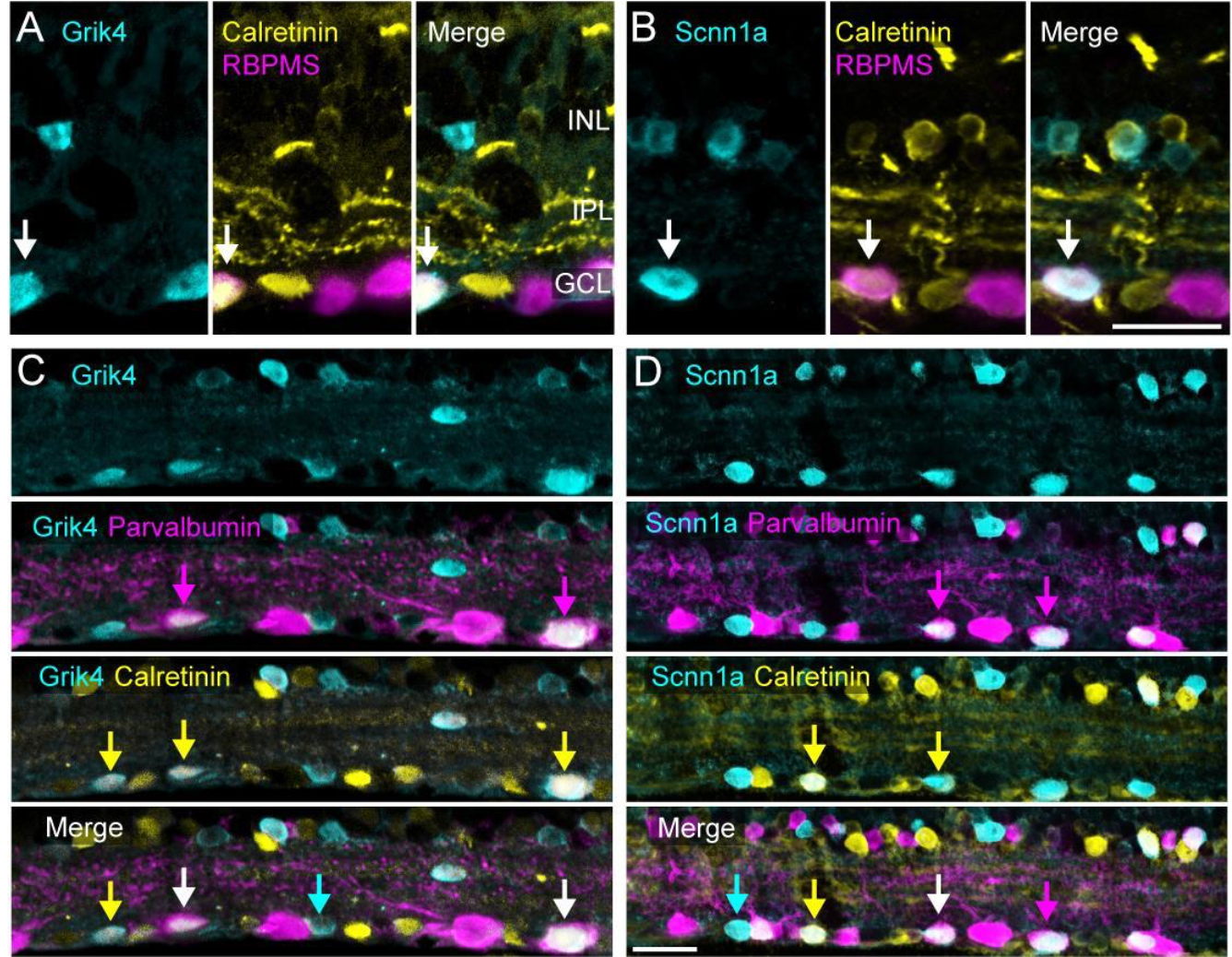
This figure shows experimental results from E. Sernagor lab (performed by G. Hilgen et E. Sernagor) showing how specific genes (Grik4 and Scnn1a) are expressed in mice retina, at the level of Retinal Ganglion Cells types.
Experimental results from E. Sernagor lab (performed by G. Hilgen et E. Sernagor) showing how specific genes (Grik4 and Scnn1a) are expressed in mice retina, at the level of Retinal Ganglion Cells types. INL = inner nuclear layer, IPL = inner plexiform layer, GCL = ganglion cell layer. Scale bar is D = 20 .
7.2 Diagnosis, rehabilitation, and low-vision aids
7.2.1 Constrained text generation to measure reading performance
Participants: Alexandre Bonlarron, Aurélie Calabrèse, Pierre Kornprobst, Jean-Charles Régin.
1 Aix-Marseille Université (CNRS, Laboratoire de Psychologie Cognitive, Marseille, France)
2 Université Côte d'Azur (France), I3S, Constraints and Application Lab
Description: Measuring reading performance is one of the most widely used methods in ophthalmology clinics to judge the effectiveness of treatments, surgical procedures, or rehabilitation techniques 48. However, reading tests are limited by the small number of standardized texts available. For the MNREAD test 45, which is one of the reference tests used as an example in this paper, there are only two sets of 19 sentences in French. These sentences are challenging to write because they have to respect rules of different kinds (e.g.,related to grammar, length, lexicon, and display). They are also tricky to find : out of a sample of more than three million sentences from children’s literature, only four satisfy the criteria of the MNREAD reading test. To obtain more sentences, we propose an original approach to text generation that considers all the rules at the generation stage. Our approach is based on Multi-valued Decision Diagrams (MDD). First, we represent the corpus by n-grams and the different rules by MDDs, and then we combine them using operators, notably intersections. The results obtained show that this approach is promising, even if some problems remain, such as memory consumption or a posteriori validation of the meaning of sentences. In 5-gram, we generate more than 4000 sentences that meet the MNREAD criteria and thus easily provide an extension of a 19-sentence set to the MNREAD test.
This work has been presented in the conference JFPC 2022 20 and to the Workshop MOMI 2022 26.
7.2.2 A new vessel-based method to estimate automatically the position of the non-functional fovea on altered retinography from maculopathies
Participants: Vincent Fournet, Aurélie Calabrèse, Séverine Dours, Frédéric Matonti, Eric Castet, Pierre Kornprobst.
1 Aix-Marseille Université (CNRS, Laboratoire de Psychologie Cognitive, Marseille, France)
2 Institut d’Education Sensoriel (IES) Arc-en-Ciel
3 Centre Monticelli Paradis d'Ophtalmologie
Context: This contribution is part of a larger initiative in the scope of ANR DEVISE. We aim at measuring and analyzing the 2D geometry of each patient's "visual field," notably the characteristics of his/her scotoma (e.g., shape, location w.r.t fovea, absolute vs. relative) and gaze fixation data. This work is based on data acquired from a Nidek MP3 micro-perimeter installed at Centre Monticelli Paradis d'Ophtalmologie. In 2021, the focus was on the estimation of the fovea position from perimetric images (see below) and on the development of a first graphical user interface to manipulate MP3 data.
Description: In the presence of maculopathies, due to structural changes in the macula region, the fovea is usually located in pathological fundus images using normative anatomical measures (NAM). This simple method relies on two conditions: that images are acquired under standard testing conditions (primary head position and central fixation) and that the optic disk is visible entirely on the image. However, these two conditions are not always met in the case of maculopathies, en particulier lors de taches de fixations. Here, we propose a Vessel-Based Fovea Localization (VBFL) approach that relies on the retina's vessel structure to make predictions. The spatial relationship between fovea location and vessel characteristics is learnt from healthy fundus images and then used to predict fovea location in new images. We evaluate the VBFL method on three categories of fundus images: healthy images acquired with different head orientations and fixation locations, healthy images with simulated macular lesions and pathological images from AMD. For healthy images taken with the head tilted to the side, NAM estimation error is significantly multiplied by 4, while VBFL yields no significant increase, representing a 73% reduction in prediction error. With simulated lesions, VBFL performance decreases significantly as lesion size increases and remains better than NAM until lesion size reaches 200 deg2. For pathological images, average prediction error was 2.8 degrees, with 64% of the images yielding an error of 2.5 degrees or less. VBFL was not robust for images showing darker regions and/or incomplete representation of the optic disk. In conclusion, the vascular structure provides enough information to precisely locate the fovea in fundus images in a way that is robust to head tilt, eccentric fixation location, missing vessels and actual macular lesions.
More information is available in 41. This work was presented at ARVO 2022 28 and an extended journal version has been submitted to Translational Vision Science & Technology.
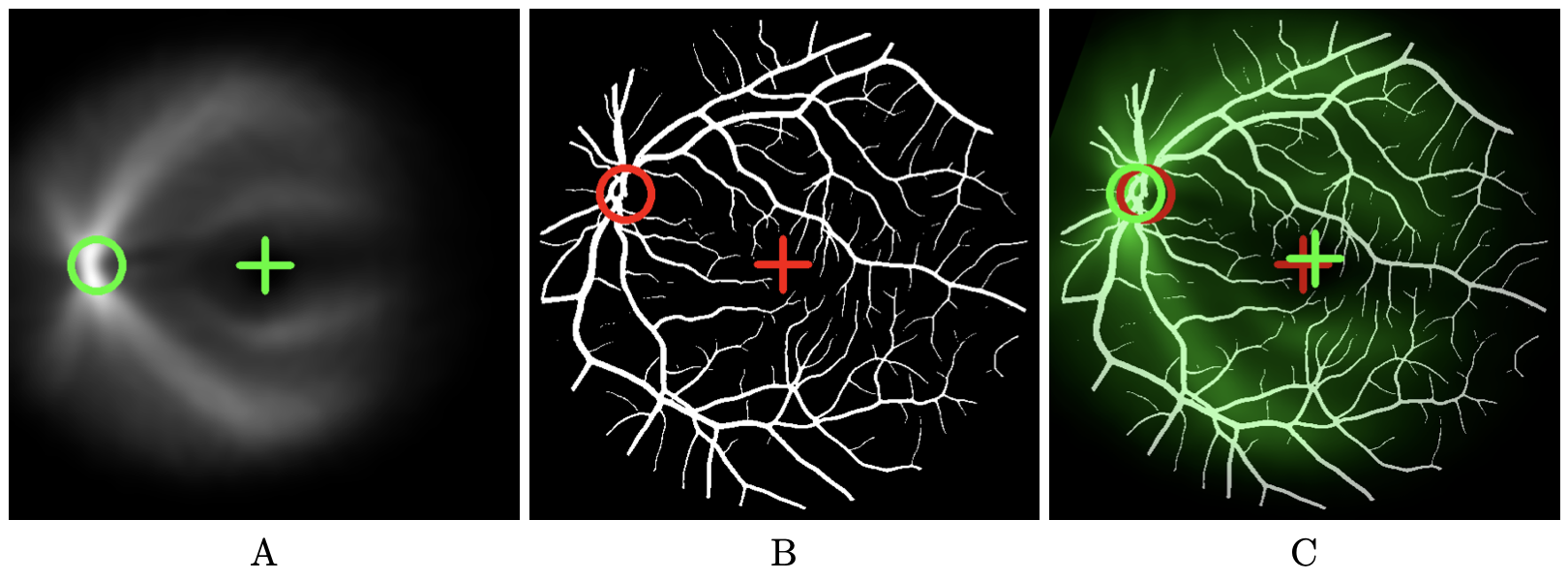
This figures illustrates how our method to detect the fovea works. It contains three images. The left image shows the vessel density map. This map is obtained by realigning and then averaging a set of vessel maps for which fovea and optic disk position are known. The are realigned based upon fixed positions of fovea and optic disk which are marked by a green cross and a green circle respectively. The middle image shows the vessel map where the fovea position is unknown. In our example, the ground truth is available allowing error estimates. Red cross indicates the true position of the fovea we are looking for. The right image shows the vessel density map in green-scale color superimposed on the vessels map after registration. The fovea position of the vessel density map after registration serves as an estimate for the fovea position. It is represented by a green cross. When ground truth is available (red cross), error can be estimated (distance between green and red crosses).
Illustration of the registration-based fovea localization method considering only vessel spatial distribution. (A) Vessel density map obtained by realigning and averaging a set of vessel maps, with the reference fovea and optic disk position marked by a cross and a circle respectively, (B) Vessel map in which the fovea has to be located. Here we assume that the ground truth is available allowing error estimates. Red cross indicates the true position of the fovea. (C) Vessel density map in green color superimposed on the vessels map after registration. The fovea position of the vessel density map (green cross) serves as an estimate for the fovea position. When ground truth is available (red cross), error can be estimated (distance between green and red crosses).
7.2.3 From Print to Online Newspapers on Small Displays: A Layouting Generation Approach Aimed at Preserving Entry Points
Participants: Sebastian Gallardo, Dorian Mazauric, Pierre Kornprobst.
1 Universidad Técnica Federico Santa María, Valparaíso, Chile
2 Université Côte d'Azur (France), Inria, ABS Team
Context: The digital era transforms the newspaper industry, offering new digital user experiences for all readers. However, to be successful, newspaper designers stand before a tricky design challenge: translating the design and aesthetics from the printed edition (which remains a reference for many readers) and the functionalities from the online edition (continuous updates, responsiveness) to create the e-newspaper of the future, making a synthesis based on usability, reading comfort, engagement. In this spirit, our project aims to develop a novel inclusive digital news reading experience that will benefit all readers: you, me, and low vision people for whom newspapers are a way to be part of a well-evolved society.
Description: In this work we have focused on how to comfortably read newspapers on a small display . Simply transposing the print newspapers into digital media can not be satisfactory because they were not designed for small displays. One key feature lost is the notion of entry points that are essential for navigation. By focusing on headlines as entry points, we show how to produce alternative layouts for small displays that preserve entry points quality (readability and usability) while optimizing aesthetics and style. Our approach consists in a relayouting approach implemented via a genetic-inspired approach. We tested it on realistic newspaper pages. For the case discussed here, we obtained more than 2000 different layouts where the font was increased by a factor of two. We show that the quality of headlines is globally much better with the new layouts than with the original layout. Future work will tend to generalize this promising approach, accounting for the complexity of real newspapers, with user experience quality as the primary goal.
This work was published in the ACM Symposium on Document Engineering (DocEng ’22) 16.

|

|

|

|
| (a) | (b) | (c) UW=6 | (d) UW=1 |
From print to online newspapers on small displays: (a) Print newspaper page where each article has been colored to highlight the structure. On small displays, headlines become too small to be readable and usable for navigation. Magnification is needed. (b) Pinch-zoom result with a magnification factor of two: Illustrates the common local/global navigation difficulty encountered when reading newspapers via digital kiosk applications. (c) Increasing the font with a factor two, keeping the original layout: Articles with unwanted shapes (denoted by UW, here when headlines flow on more than three lines) are boxed in red; (d) Best result of our approach showing how the page in (a) has been transformed to preserve headlines quality.
7.3 Visual media analysis and creation
7.3.1 Engineering an immersive virtual reality platform for studying embodied experiences
Participants: Florent Robert, Hui-Yin Wu, Lucile Sassatelli, Marco Winckler .
1 Université Côte d'Azur, France
2 CNRS I3S Laboratory, France
3 Institut Universitaire de France, France
4 Centre Inria d'Université Côte d'Azur, CNRS I3S, SPARKS team, France
Context: In the context of ANR CREATTIVE3D, we are tackling the major challenge of designing 3D experiences and user tasks. This lies in bridging the inter-relational gaps of perception between the designer, the user, and the 3D scene. Paul Dourish identified three gaps of perception: ontology between the scene representation and the user and designer interpretation, intersubjectivity of task communication between designer and user, and intentionality between the user's intentions and designer's interpretations.
To address this, we developed the GUsT-3D framework for designing Guided User Tasks in embodied VR experiences, i.e., tasks that require the user to carry out a series of interactions guided by the constraints of the 3D scene. GUsT-3D is implemented as a set of tools that support a 4-step workflow to (1) annotate entities in the scene with navigation and interaction possibilities, (2) define user tasks with interactive and timing constraints, (3) manage interactions, task validation, and user logging in real-time, and (4) conduct post-scenario analysis through spatio-temporal queries using ontology definitions.
Description: We propose the GUsT-3D framework for creating 3D embodied experiences, which is comprised of three components (Figure 12):
- GUsT-3D: representing the ontology of the scene, implemented in JSON. It is used to export the annotated 3D scene, including all of the geometric properties, interactive and navigation possibilities, and their inter-relations as a spatio-temporal scene graph. It also provides the vocabulary set to define GUTasks and for user logging.
- GUTasks: representing the intersubjectivity between the designer and the user, also implemented in JSON using the same vocabulary defined in the GUsT-3D ontology. Allows the definition of user tasks to be carried out in the VR scenario, their interactive and completion constraints, and management and validation in real-time.
- Logs and query language: representing the user intentionality, implemented in LINQ 46. Allows the designer to construct spatio-temporal queries on any annotated object or user in the 3D scene.
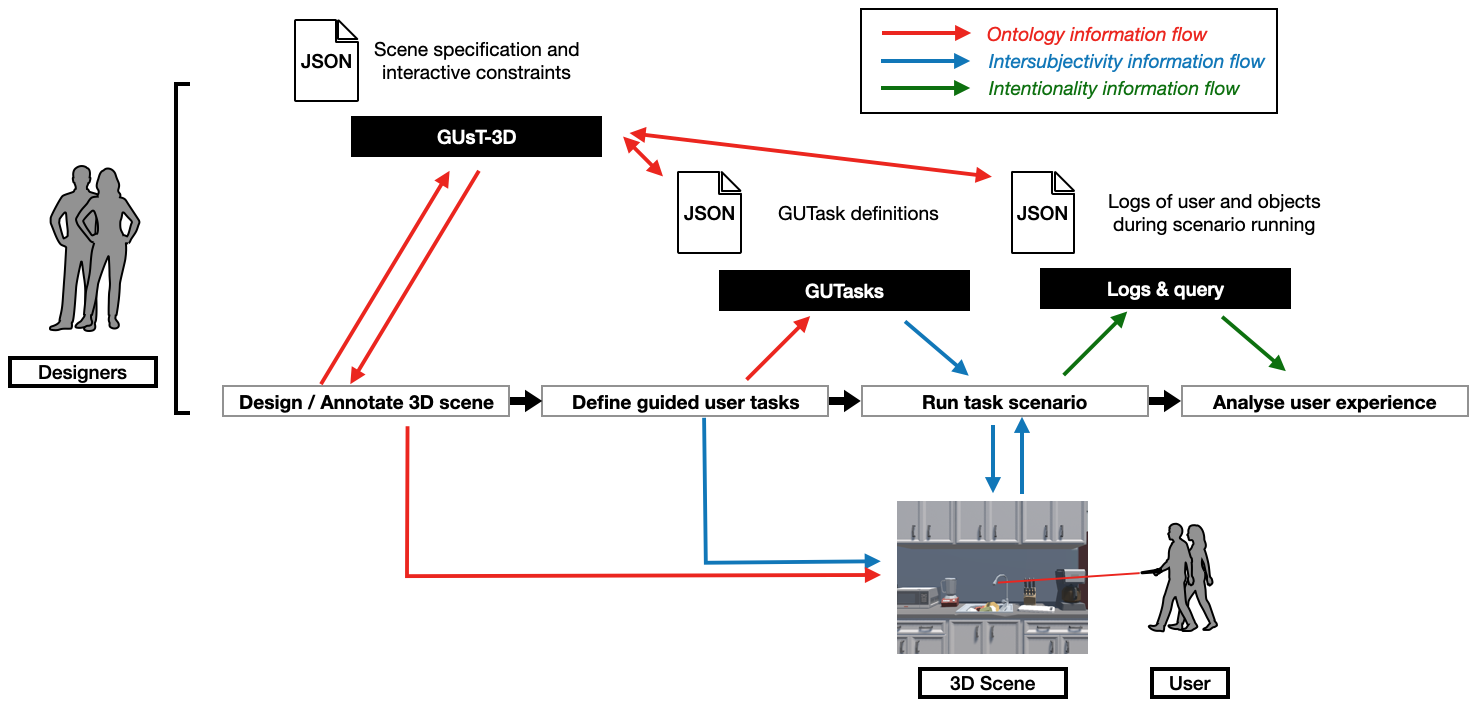
The interactions between the user, designer, and input/output JSON files for each of the three steps of the workflow, and how they relate to the three gaps of perception.
We conducted a formative evaluation involving six expert interviews to assess the framework and the implemented workflow. Analysis of the responses show that the GUsT-3D framework fits well into a designer's creative process, providing a necessary workflow to create, manage, and understand VR embodied experiences.
The results of this work were published in the Proceedings of ACM on Human Computer Interactions (PACMHCI) and presented at the ACM Symposium on Engineering Interactive Systems (EICS)9. F. Robert presented his thesis work on the project at the doctoral consortium of the ACM Conference on Multimedia Systems (ACM MMSys)18. The technical platform has been issued a CeCILL licence (IDDN.FR.001.160035.000.S.P.2022.000.31235).
Other news and development on the project can be followed from official website.
7.3.2 On the link between emotion, attention and content in virtual immersive environments
Participants: Quentin Guimard, Florent Robert, Lucile Sassatelli, Hui-Yin Wu, Marco Winckler , Auriane Gros.
1 Université Côte d'Azur, France
2 CNRS I3S Laboratory, France
3 Institut Universitaire de France, France
4 Centre Inria d'Université Côte d'Azur, CNRS I3S, SPARKS team, France
5 Université Côte d'Azur, CHU, CoBTEK, France
Context: While immersive media have been shown to generate more intense emotions, saliency information has been shown to be a key component for the assessment of their quality, owing to the various portions of the sphere (viewports) a user can attend. In this work we investigated the tri-partite connection between user attention, user emotion and visual content in immersive environments. To do so, we present a new dataset enabling the analysis of different types of saliency, both low-level and high-level, in connection with the user's state in 360 videos. Head and gaze movements are recorded along with self-reports and continuous physiological measurements of emotions. We then study how the accuracy of saliency estimators in predicting user attention depends on user-reported and physiologically-sensed emotional perceptions. Our results show that high-level saliency better predicts user attention for higher levels of arousal. We discuss how this work serves as a first step to understand and predict user attention and intents in immersive interactive environments.
Description: This work comprises of two principal parts: the release of an open dataset on synchronized gaze and emotion for 360 videos, and first analyses on this dataset on how emotion affects the predictability of gaze.
The PEM360 dataset contains user head movements and gaze recordings in 360 videos, along with self-reported emotional ratings of valence and arousal, and continuous physiological measurement of electrodermal activity and heart rate. The stimuli are selected to enable the spatiotemporal analysis of the connection between content, user motion and emotion. We describe and provide a set of software tools to process the various data modalities, and introduce a joint instantaneous visualization of user attention and emotion we name “Emotional maps”. The dataset and analysis scripts are entirely made available on the PEM360 Dataset Gitlab.
Tri-partite connection between user attention, user emotion and visual content in immersive environments. Using the PEM360 dataset, we then study how the accuracy of saliency estimators in predicting user attention depends on user-reported and physiologically-sensed emotional perceptions. Our results show that high-level saliency better predicts user attention for higher levels of arousal. In Figure 13 we can visualize the level of emotional arousal as a saliency heatmap on the video.

On the still image of a roller coaster video, we see at the center a red scan path indicating a high arousal as the ride decends into a dive.
The results of this work were published to the ACM Conference on Multimedia Systems Open Dataset and Software Track (ACM MMSys) and the IEEE International Conference on Image Processing (ICIP)17, 24.
7.3.3 Evaluation of deep pose detectors for automatic analysis of film style
Participants: Hui-Yin Wu, Luan Nguyen, Yoldoz Tabei, Lucile Sassatelli.
1 Université Côte d'Azur, France
2 CNRS I3S Laboratory, France
3 Institut Universitaire de France, France
Context: Identifying human characters and how they are portrayed on-screen is inherently linked to how we perceive and interpret the story and artistic value of visual media. Building computational models sensible towards story will thus require a formal representation of the character. Yet this kind of data is complex and tedious to annotate on a large scale. Human pose estimation (HPE) can facilitate this task, to identify features such as position, size, and movement that can be transformed into input to machine learning models, and enable higher artistic and storytelling interpretation. However, current HPE methods operate mainly on non-professional image content, with no comprehensive evaluation of their performance on artistic film.
We thus took a first step to evaluate the performance of HPE methods on artistic film content. We begin by proposing a formal representation of the character based on cinematography theory, then sample and annotate 2700 images from three datasets with this representation, one of which we introduce to the community. An in-depth analysis is then conducted to measure the general performance of two recent HPE methods on metrics of precision and recall for character detection, and to examine the impact of cinematographic style. From these findings, we highlight the advantages of HPE for automated film analysis, and propose future directions to improve their performance on artistic film content.
Description: We propose an analysis of human pose estimators based on performance metrics associated with specific frame criteria: (1) precision, recall, and pose keypoint accuracy measures that have been used for pre-existing benchmarks, and (2) a set of cinematographic labels extending Film Editing Patterns 53 focused on character representation, and spanning six large categories: character size, character angle (both pitch and yaw), on-screen position, number of characters, body part visibility, and artistic shots.
Two HPE methods were selected: OpenPose 37 because it is a reference bottom-up approach shown to have reliable and real-time performance, and DEKR 42 because (i) it is a most recent approach shown to outperform existing competitors and because (ii) it builds on the features learned by a top-down approach, HRNet, to take the best of both bottom-up and top-down approaches. We benchmarked the performance of these two HPE methods on three datasets:
- COCO201744 composed of 106K images that are annotated with 17 joints.
- FLIC plus49 made of 17K images from film annotated with only 10 upper-body joints and ground-truth poses for up to two characters.
- TRACTIVE our new dataset of clips extracted from the corpus proposed by Brey 35. This dataset is composed of 13 clips, on which HPE methods are evaluated on a subset of frames hand-annotated for both character representation and pose estimation quality.
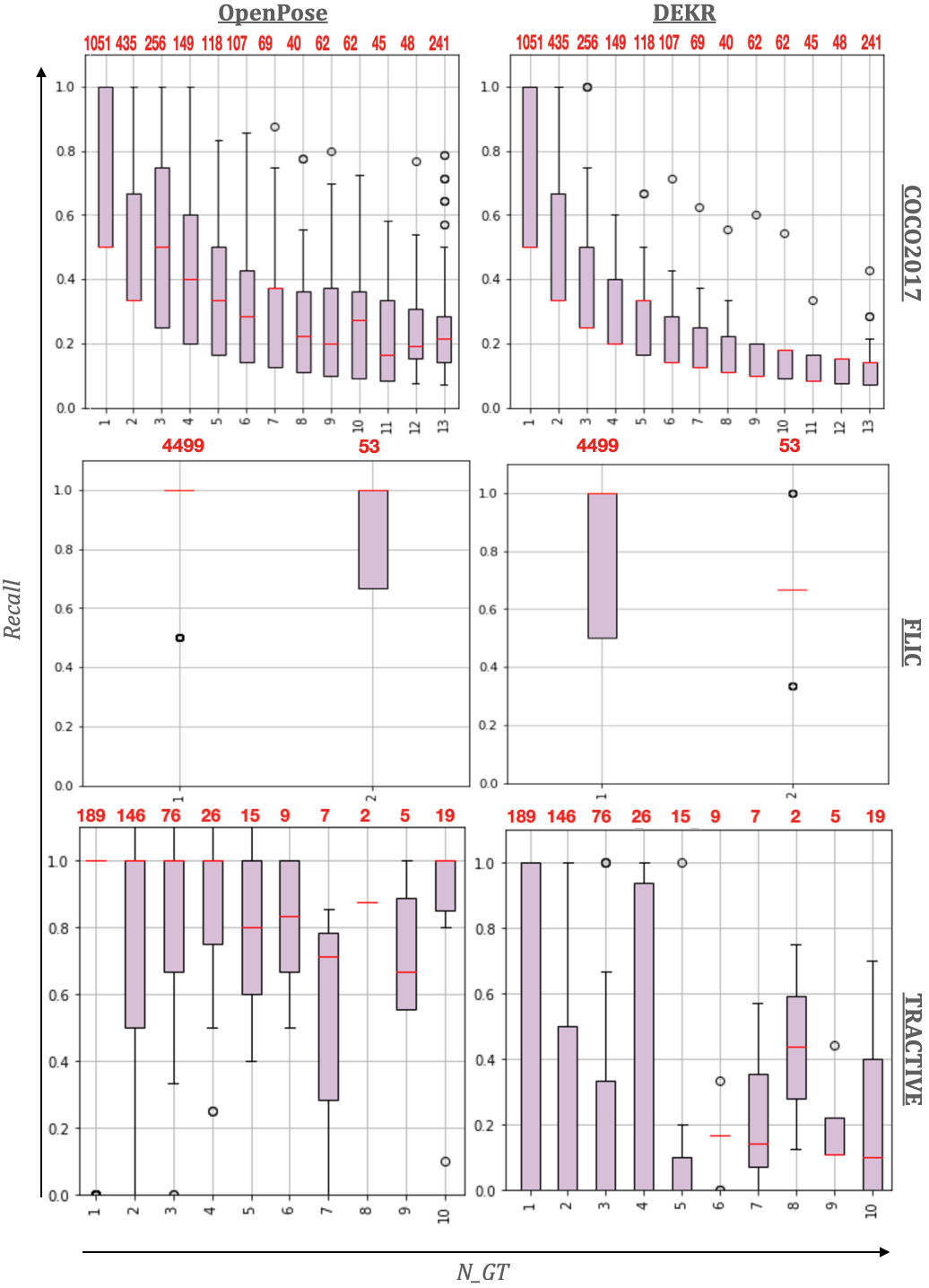
Six box plots showing the recall rate of the two HPE methods on the three different datasets.
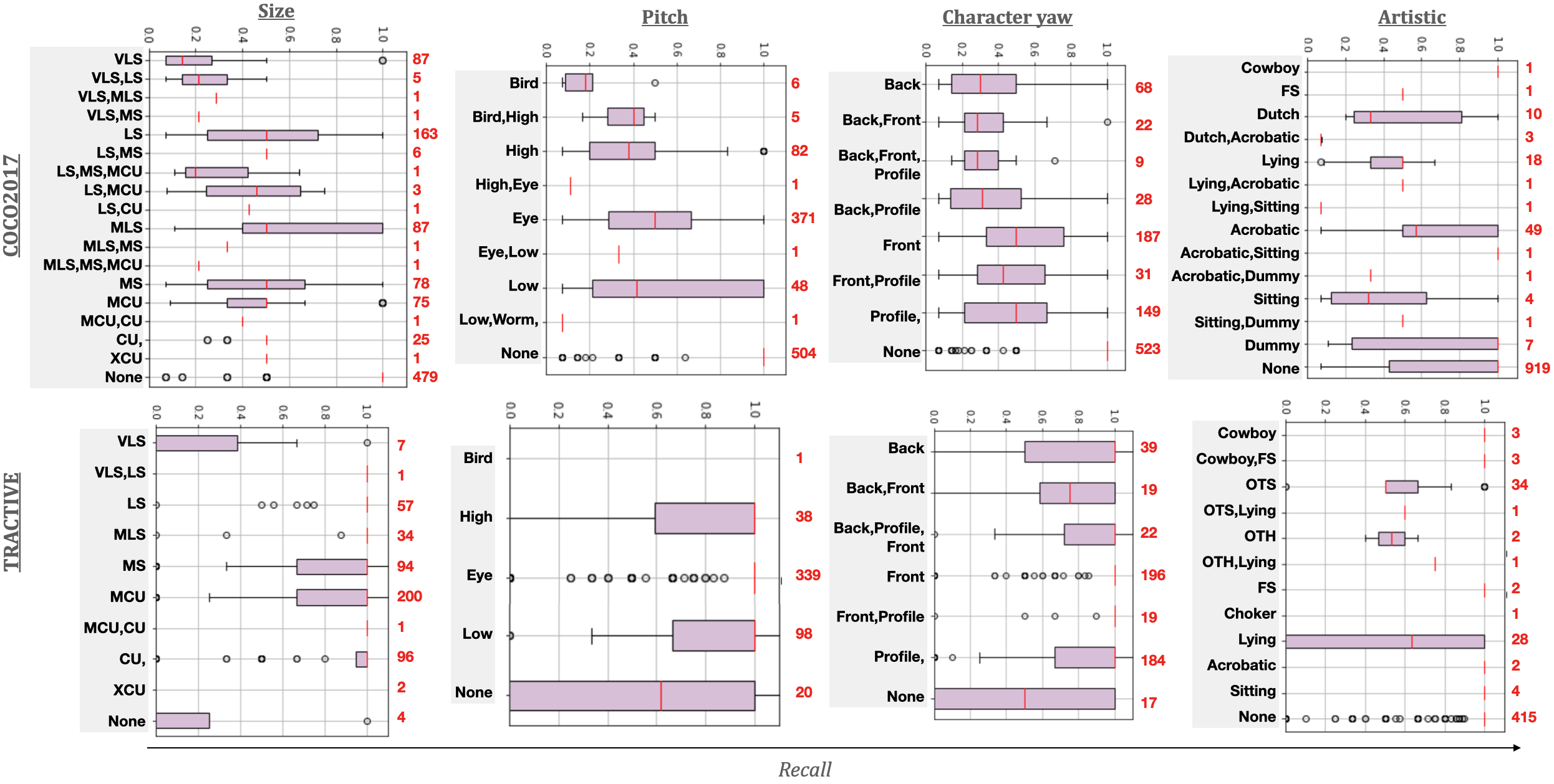
Eight box plots showing the impact of artistic style on recall.
On all three datasets, we generally observe in Figure 14 that recall decreases with , indicating proportionally more misses with the number of on-screen characters. In more than 25% of the cases, at least 20% of characters are missed for . For , at least 50% of characters are missed. From the results of OpenPose on the COCO and TRACTIVE datasets, we were also able to draw a number of observations on the impact of film style (Figure 15).
The results of this work were published to the Eurographics Digital Library and presented at the 10th Eurographics Workshop on Intelligent Cinematography and Editing 19.
8 Bilateral contracts and grants with industry
8.1 Bilateral contracts with industry
Helping visually impaired employees to follow presentations in the company: Towards a mixed reality solution
Participants: Riham Nehmeh, Carlos Zubiaga, Julia-Elizabeth Luna, Arnaud Mas, Alain Schmid, Christophe Hugon, Pierre Kornprobst.
1 InriaTech, UCA Inria, France
2 EDF, R&D PERICLES – Groupe Réalité Virtuelle et Visualisation Scientifique, France
3 EDF, Lab Paris Saclay, Département SINETICS, France
4 R&DoM
Duration: 3 months
Objective: The objective of the work is to develop a proof-of-concept (PoC) targeting a precise use-case scenario defined by EDF (contract with InriaTech, supervised by Pierre Kornprobst). The use-case is one of an employee with visual impairment willing to follow a presentation. The idea of the PoC is a vision-aid system based on a mixed-reality solution. This work aims at (1) estimating the feasibility and interest of such kind of solution and (2) identifying research questions that could be jointly addressed in a future partnership.
APP Deposit: SlidesWatchAssistant IDDN.FR.001.080024.000.S.P.2020.000.31235)
9 Partnerships and cooperations
9.1 International initiatives
9.1.1 Associate Teams in the framework of an Inria International Lab or in the framework of an Inria International Program
MAGMA
-
Title:
Modelling And understandinG Motion Anticipation in the retina
-
Duration:
2019 -> 2022
-
Coordinator:
Maria-José Escobar (mariajose.escobar@usm.cl)
-
Partners:
- Universidad Técnica Federico Santa María, Valparaíso (Chili)
-
Inria contact:
Bruno Cessac
-
Summary:
Motion processing represents a fundamental visual computation ruling many visuomotor features such as motion anticipation which compensates the transmission delays between retina and cortex, and is fundamental for survival. We want to strengthen an existing collaborative network between the Universidad de Valparaíso in Chile and the Biovision team, gathering together skills related with physiological recording in the retina, data analysis numerical platforms and theoretical tools to implement functional and biophysical models aiming at understanding the mechanisms underlying anticipatory response and the predictive coding observed in the mammalian retina, with a special emphasis on the role of lateral connectivity (amacrine cells and gap junctions).
9.2 International research visitors
9.2.1 Visits of international scientists
Other international visits to the team
Rodrigo Cofré
-
Status
researcher
- Institution of origin: CIMFAV – Facultad de Ingeniería Universidad de Valparaíso.
- Country: Chile
- Dates: 21-24/06/2022
- Context of the visit:Associate team MAGMA
-
Mobility program/type of mobility:
research stay
Adrian Palacios
-
Status
researcher
- Institution of origin: Universidad de Valparaíso (Chile) | CINV · Center Interdisciplinary for Neuroscience of Valparaíso (CINV)
- Country: Chile
- Dates: 21-24/06/2022
- Context of the visit: Associate team MAGMA
-
Mobility program/type of mobility:
research stay
9.3 National initiatives
Participants: Bruno Cessac, Pierre Kornprobst, Hui-Yin Wu.
9.3.1 ANR
ShootingStar
- Title: Processing of naturalistic motion in early vision
-
Programme:
ANR
-
Duration:
April 2021 - March 2025
-
Coordinator:
Mark WEXLER (CNRS‐INCC),
-
Partners:
- Institut de Neurosciences de la Timone (CNRS and Aix-Marseille Université, France)
- Institut de la Vision (IdV), Paris, France
- Unité de Neurosciences Information et Complexité, Gif sur Yvette, France
- Laboratoire Psychologie de la Perception - UMR 8242, Paris
-
Inria contact:
Bruno Cessac
-
Summary:
The natural visual environments in which we have evolved have shaped and constrained the neural mechanisms of vision. Rapid progress has been made in recent years in understanding how the retina, thalamus, and visual cortex are specifically adapted to processing natural scenes. Over the past several years it has, in particular, become clear that cortical and retinal responses to dynamic visual stimuli are themselves dynamic. For example, the response in the primary visual cortex to a sudden onset is not a static activation, but rather a propagating wave. Probably the most common motions in the retina are image shifts due to our own eye movements: in free viewing in humans, ocular saccades occur about three times every second, shifting the retinal image at speeds of 100-500 degrees of visual angle per second. How these very fast shifts are suppressed, leading to clear, accurate, and stable representations of the visual scene, is a fundamental unsolved problem in visual neuroscience known as saccadic suppression. The new Agence Nationale de la Recherche (ANR) project “ShootingStar” aims at studying the unexplored neuroscience and psychophysics of the visual perception of fast (over 100 deg/s) motion, and incorporating these results into models of the early visual system.
DEVISE
-
Title:
From novel rehabilitation protocols to visual aid systems for low vision people through Virtual Reality
-
Programme:
ANR
-
Duration:
2021–2025
-
Coordinator:
Eric Castet (Laboratoire de Psychologie Cognitive, Marseille)
-
Partners:
- CNRS/Aix Marseille University – AMU, Cognitive Psychology Laboratory
- AMU, Mediterranean Virtual Reality Center
-
Inria contact:
Pierre Kornprobst
-
Summary:
The ANR DEVISE (Developing Eccentric Viewing in Immersive Simulated Environments) aims to develop in a Virtual Reality headset new functional rehabilitation techniques for visually impaired people. A strong point of these techniques will be the personalization of their parameters according to each patient’s pathology, and they will eventually be based on serious games whose practice will increase the sensory-motor capacities that are deficient in these patients.
CREATTIVE3D
-
Title:
Creating attention driven 3D contexts for low vision
-
Programme:
ANR
-
Duration:
2022–2026
-
Coordinator:
Hui-Yin Wu
-
Partners:
- Université Côte d'Azur I3S, LAMHESS, CoBTEK laboratories
- CNRS/Aix Marseille University – AMU, Cognitive Psychology Laboratory
-
Summary:
CREATTIVE3D deploys virtual reality (VR) headsets to study navigation behaviors in complex environments under both normal and simulated low-vision conditions. We aim to model multi-modal user attention and behavior, and use this understanding for the design of assisted creativity tools and protocols for the creation of personalized 3D-VR content for low vision training and rehabilitation.
TRACTIVE
-
Title:
Towards a computational multimodal analysis of film discursive aesthetics
-
Programme:
ANR
-
Duration:
2022–2026
-
Coordinator:
Lucile Sassatelli
-
Partners:
- Université Côte d'Azur CNRS I3S
- Université Côte d'Azur, CNRS BCL
- Sorbonne Université, GRIPIC
- Université Toulouse 3, CNRS IRIT
- Université Sorbonne Paris Nord, LabSIC
-
Inria contact:
Hui-Yin Wu
-
Summary:
TRACTIVE's objective is to characterize and quantify gender representation and women objectification in films and visual media, by designing an AI-driven multimodal (visual and textual) discourse analysis. The project aims to establish a novel framework for the analysis of gender representation in visual media. We integrate AI, linguistics, and media studies in an iterative approach that both pinpoints the multimodal discourse patterns of gender in film, and quantitatively reveals their prevalence. We devise a new interpretative framework for media and gender studies incorporating modern AI capabilities. Our models, published through an online tool, will engage the general public through participative science to raise awareness towards gender-in-media issues from a multi-disciplinary perspective.
9.4 Regional initiatives
XRC
-
Title:
Extended reality research and creative center
-
Programme:
IDEX
-
Duration:
2020–
-
Coordinator:
Jean-François Trubert
-
Partners:
Involves 13 laboratories in Université Côte d'Azur
-
Inria contact:
Hui-Yin Wu, Pierre Kornprobst
-
Summary:
XRC is the reference center for extended reality in the Université Côte d'Azur. It groups 13 laboratories and over 60 researchers in thematics of artistic creation, media studies, health, communications and computer science. The center is currently based in the Cannes Georges Méliès campus.
10 Dissemination
Participants: Bruno Cessac, Johanna Delachambre, Simone Ebert, Jérome Emonet, Pierre Kornprobst, Florent Robert, Jérémy Termoz-Masson, Hui-Yin Wu.
10.1 Promoting scientific activities
10.1.1 Scientific events: organisation
General chair, scientific chair
- B. Cessac organized the “mini-cours” of the Neuromod institute, (see webpage for dates, topics and presentations).
- B. Cessac co-organized the "Rencontres de l'institut Neuromod", 30-06, 01-07 in Antibes.
10.1.2 Scientific events: selection
Chair of conference program committees
- H.-Y. Wu co-chaired the program committee of the 10th Eurographics Workshop on Intelligent Cinematography and Editing.
Member of the conference program committees
- H.-Y. Wu was on the program committee for the 2022 International Conference on Interactive Digital Storytelling (ICIDS 2022).
Reviewer
- H.-Y. Wu and F. Robert were reviewers for NordCHI 2022.
10.1.3 Journal
Member of the editorial boards
- P. Kornprobst has been associate editor for the Computer Vision and Image Understanding Journal (CVIU) since Jul 2016.
Reviewer - reviewing activities
- H.-Y. Wu was a reviewer for ACM Transactions on Graphics (IF: 7.71), International Journal on Human-Computer Interaction (IF: 4.78), Multimedia Tools and Applications (IF: 2.57), Elsevier Computers and Graphics (IF: 1.88), and Wiley Computer Animations and Virtual Worlds (IF: 1.01).
10.1.4 Invited talks
- B. Cessac was invited at the conference "Mathematical modeling and statistical analysis in neuroscience" Paris Institut Henry Poincaré, January 31st to February 4th, 2022
- B. Cessac was invited at the conference "Workshop Stochastic Models in Life Science", Eindhoven 12-14 September, 2022.
- B. Cessac was invited at the conference "AI4Waves", Sophia-Antipolis, 10-12 October 2022.
- P. Kornprobst gave a talk entitled "La DMLA : des mécaniques d’adaptation en santé aux mécaniques ludiques" at the Workshop "Jeu vidéo, ludification, mécaniques et apprentissages", Cannes, September 2022
- Jérémy Termoz-Masson gave a talk entitled "Design et VR à destination de personnes souffrant de la Dégénérescence Maculaire Liée à l’Age" at the Workshop "Art et santé", organized by Académie 5 from UCA, Nice
10.1.5 Research administration
- B. Cessac is a member of the Bureau du Comité des Projets of the Sophia-Antipolis Inria research center.
- B. Cessac is an invited member of the Comité de Suivi et de Pilotage of the EUR Spectrum (representative of the Neuromod Institute).
- B. Cessac is a member of the board and a member of the Scientific Council of the Institute of Neurosciences and Neuromod Modeling since 2018.
- P. Kornprobst has been an elected member of the Academic Council of UCA (Conseil d’Administration) since Dec. 2019.
10.2 Teaching - Supervision - Juries
10.2.1 Teaching
- Master 1: B. Cessac (24 hours, cours) Introduction to Modelling in Neuroscience, master Mod4NeuCog, UCA, France.
- Master 1: Simone Ebert (15 hours, TD), Introduction to Modelling in Neuroscience, master Mod4NeuCog, UCA, France.
- License 2: J. Emonet (22 hours), Introduction à l'informatique, License SV, UCA, France.
- License 3: J. Emonet (16 hours), Programmation python et environnement linux, License BIM, UCA, France.
- License 3: J. Emonet (20 hours), Biostatistiques, License SV, UCA, France.
- Master 2: H-Y. Wu and J. Delachambre (with M. Winckler), Techniques d'interaction et multimodalité, 32 hours, Master en Informatique (SI5) mineure IHM, Polytech Nice Sophia, UCA, France
- Master 2: H-Y. Wu supervised M2 student final projects (TER), 14 hours, Master en Informatique (SI4), Polytech Nice Sophia, UCA, France
- Master 1: F. Robert (with M. Winckler), Interfaces Humaine-Machine, 38 hours, Master en Informatique (SI4), Polytech Nice Sophia, UCA, France
10.2.2 Supervision
-
Master's students
- P. Kornprobst and M. Marti (UCA, LIRCES) co-supervised Quentin Garnier, Ludivine Martin, and Léo Riba on "La Forêt de Brocéliande : Conception d’un jeu adapté aux patients souffrant de dégénérescence maculaire liée à l’âge", Master 1 and 2, Mention Humanités et Industries Créatives Parcours Management, Jeux Vidéo, Image et Créativité (March - September 2022).
- P. Kornprobst and H-Y. Wu co-supervised Johanna Delachambre on an apprenticeship for engineering virtual reality systems
- H-Y. Wu supervised Clément Merveille on "Analysis and visualization of eye tracking data in virtual reality under normal and simulated low-vision conditions" (April - September 2022)
- H-Y. and L. Sassatelli co-supervised Geneviève Masioni on "Image and text processing for multimodal film analysis" (March - September 2022)
- H-Y. Wu and L. Sassatelli co-supervised Clément Quéré on "Modeling 6 DoF human motion data in extended reality" (March - August 2022)
-
PhD students
- PhD defended: Evgenia Kartsaki, “How Specific Classes of Retinal Cells Contribute to Vision: a Computational Model”, October 2017–March 2022, co-supervised by B. Cessac and E. Sernagor (Newcastle).
- PhD in progress: Simone Ebert on “Dynamical Synapse in the Retinal Network”, started in October 202, supervised by B. Cessac. Funding UCA Institut Neuromod.
- PhD in progress: Jérome Emonet, "A computational model of the retino-thalamo-cortical pathway", started in October 2021, supervised by B. Cessac in collaboration with A. Destexhe. Funding ANR ShootingStar.
- PhD in progress: Alexandre Bonlarron. "Pushing the limits of reading performance screening with Artificial Intelligence: Towards large-scale evaluation protocols for the Visually Impaired", started in October 2021, co-supervised by P. Kornprobst, A. Calabrèse and J.-C. Régin.
- PhD in progress: Florent Robert, "Analyzing and Understanding Embodied Interactions in Extended Reality Systems", started in October 2021, supervised by H-Y. Wu, M. Winckler and L. Sassatelli.
- PhD in progress: Johanna Delachambre. "Social interactions in low vision: A collaborative approach based on immersive technologies", started in November 2020, co-supervised by P. Kornprobst and H.-Y. Wu.
- PhD in progress: Franz Franco Gallo, "Modeling 6DoF Navigation and the Impact of Low Vision in Immersive VR Contexts", started in November 2022, supervised by H-Y. Wu and L. Sassatelli.
- PhD in progress: Julie Tores, "Deep Learning to detect objectification in films and visual media", started in November 2022, supervised by L. Sassatelli, F. Précioso and H-Y. Wu
10.2.3 Juries
- B. Cessac was a member of the jury CRCN (Chargé de Recherche) INRIA, 8-10/06.
- B. Cessac was a member of the jury for the defense of Nicholas Gale's PhD, "Theoretical Investigations into Principles of Topographic Map Formation and Applications ", Cambridge University, May 6th.
- B. Cessac was a member of the jury for the defense of Jhunlyn Lorenzo's PhD, "Modelisation de linteraction neurone-astrocyte: application au traitement du signal et des images ", Université de Dijon, September 27th.
- P. Kornprobst has been a member of the Comité de Suivi de Individuel (CSI) of Victor Jung, PhD candidate at I3S, working on "Apprentissage de contraintes cachées" and supervised by Jean-Charles Régin.
- P. Kornprobst has been a member of the Comité de Suivi de Individuel (CSI) of Abid Ali, PhD candidate at Inria, Stars project-team, working on "Action detection for improving the diagnosis of autism" and co-supervised by François Brémond and Susanne Thümmler.
- H.-Y. Wu was a member of the jury for the defense of Alexandre Bruckert, Univ. Rennes 1, Inria MimeTIC team, for his thesis on “A Perceptual-driven approach to film editing”, March 2022.
- H.-Y. Wu was a member of the jury for the defense of Ludovic Burg, Univ. Rennes 1, Inria Virtuos team, for his thesis on “Real-time Virtual Cinematography for Target Tracking”, November 2022.
10.3 Popularization
10.3.1 Interventions
- B. Cessac gave a public conference on "Vision, rétine et mathématiques", Rotary Club, Grasse, 02/06
- H.-Y. Wu presented her research to the ABC International School as part of Chiche!
11 Scientific production
11.1 Major publications
- 1 articleLinear response for spiking neuronal networks with unbounded memory.Entropy232L'institution a financé les frais de publication pour que cet article soit en libre accèsFebruary 2021, 155
- 2 articleMicrosaccades enable efficient synchrony-based coding in the retina: a simulation study.Scientific Reports624086April 2016
- 3 articleA biophysical model explains the spontaneous bursting behavior in the developing retina.Scientific Reports91December 2019, 1-23
- 4 articleBio-Inspired Computer Vision: Towards a Synergistic Approach of Artificial and Biological Vision.Computer Vision and Image Understanding (CVIU)April 2016
- 5 articleReading Speed as an Objective Measure of Improvement Following Vitrectomy for Symptomatic Vitreous Opacities.Ophthalmic Surgery, Lasers and Imaging RetinaAugust 2020
- 6 inproceedingsText Simplification to Help Individuals With Low Vision Read More Fluently.LREC 2020 - Language Resources and Evaluation ConferenceMarseille, FranceMay 2020, 11 - 16
- 7 articleThe inhibitory effect of word neighborhood size when reading with central field loss is modulated by word predictability and reading proficiency.Scientific ReportsDecember 2020
- 8 articleOn the potential role of lateral connectivity in retinal anticipation.Journal of Mathematical Neuroscience11January 2021
- 9 articleTowards Accessible News Reading Design in Virtual Reality for Low Vision.Multimedia Tools and ApplicationsMay 2021
- 10 articleDesigning Guided User Tasks in VR Embodied Experiences.Proceedings of the ACM on Human-Computer Interaction 61582022, 1–24
11.2 Publications of the year
International journals
International peer-reviewed conferences
National peer-reviewed Conferences
Conferences without proceedings
Doctoral dissertations and habilitation theses
Other scientific publications
11.3 Other
11.4 Cited publications
- 33 bookThe Retina and its Disorders.Elsevier Science2011
- 34 articleAn insight into assistive technology for the visually impaired and blind people: state-of- the-art and future trends.J Multimodal User Interfaces112017, 149–172
- 35 bookLe regard féminin : Une révolution à l'écran.Points2020
- 36 articleCharacterizing functional complaints in patients seeking outpatient low-vision services in the United States.Ophthalmology12182014, 1655–62
- 37 inproceedingsRealtime Multi-person 2D Pose Estimation Using Part Affinity Fields.2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Honolulu, HIIEEEJuly 2017, 1302--1310
- 38 articleCortical Reorganization after Long-Term Adaptation to Retinal Lesions in Humans.J Neurosci.33462013, 18080–18086
-
39
articleHealth-related quality of life among people aged
65 years with self-reported visual impairment: findings from the 2006-2010 behavioral risk factor surveillance system.Ophthalmic Epidemiol.212014, 287–296 - 40 articleVision Rehabilitation Preferred Practice Pattern.Ophthalmology12512018, 228–278
- 41 techreport How to Estimate Fovea Position When The Fovea Cannot Be Identified Visually Anymore? RR-9419 Inria Sophia Antipolis - Méditerranée, Université Côte d'Azur September 2021
- 42 inproceedingsBottom-Up Human Pose Estimation Via Disentangled Keypoint Regression.2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Nashville, TN, USAIEEEJune 2021, 14671--14681
- 43 articleLow Vision and Plasticity: Implications for Rehabilitation.Annu Rev Vis Sci.22016, 321–343
- 44 inproceedingsMicrosoft COCO: Common objects in context.European Conference on Computer Vision (ECCV)Springer International Publishing2014, 740--755
- 45 articleA new reading-acuity chart for normal and low vision.Ophthalmic and Visual Optics/Noninvasive Assessment of the Visual System Technical Digest, (Optical Society of America, Washington, DC., 1993.)31993, 232--235
- 46 inproceedingsLinq: reconciling object, relations and xml in the. net framework.Proceedings of the 2006 ACM SIGMOD international conference on Management of dataNY, New YorkACM2006, 706--706
- 47 articleSelf-management programs for adults with low vision: needs and challenges.Patient Educ Couns691–3December 2007, 39–46
- 48 articleReading Speed as an Objective Measure of Improvement Following Vitrectomy for Symptomatic Vitreous Opacities.Ophthalmic Surg Lasers Imaging Retina518Aug 2020, 456-466
- 49 inproceedingsMODEC: Multimodal Decomposable Models for Human Pose Estimation.2013 IEEE Conference on Computer Vision and Pattern RecognitionPortland, OR, USAIEEEJune 2013, 3674--3681
- 50 articleOn the potential role of lateral connectivity in retinal anticipation.Journal of Mathematical Neuroscience11January 2021
- 51 articleGlobal prevalence of age-related macular degeneration and disease burden projection for 2020 and 2040: a systematic review and meta-analysis.Lancet Glob Health22February 2014, 106–116
- 52 incollectionThrough the Eyes of Women in Engineering.Texts of DiscomfortCarnegie Mellon University: ETC PressNovember 2021, 387 - 414
- 53 articleThinking Like a Director: Film Editing Patterns for Virtual Cinematographic Storytelling.ACM Transactions on Multimedia Computing, Communications and Applications1442018, 1-23