
Keywords
Computer Science and Digital Science
- A1.1.1. Multicore, Manycore
- A1.1.2. Hardware accelerators (GPGPU, FPGA, etc.)
- A1.1.5. Exascale
- A8.2.1. Operations research
- A8.2.2. Evolutionary algorithms
- A9.6. Decision support
- A9.7. AI algorithmics
Other Research Topics and Application Domains
- B3.1. Sustainable development
- B3.1.1. Resource management
- B7. Transport and logistics
- B8.1.1. Energy for smart buildings
1 Team members, visitors, external collaborators
Faculty Members
- Nouredine Melab [Team leader, UNIV LILLE, Professor, HDR]
- Omar Abdelkafi [UNIV LILLE, Associate Professor, until Aug 2022]
- Bilel Derbel [UNIV LILLE, Professor, since Sep. 2022, HDR]
- Arnaud Liefooghe [UNIV LILLE, Associate Professor, HDR]
- El-Ghazali Talbi [UNIV LILLE, Professor, HDR]
PhD Students
- Nicolas Berveglieri [UNIV LILLE, until Nov 2022]
- Alexandre Borges de Jesus [Univ. Coimbra, until Dec 2022]
- Guillaume Briffoteaux [UNIV MONS, until Oct 2022]
- Lorenzo Canonne [INRIA]
- Thomas Firmin [UNIV LILLE]
- Juliette Gamot [INRIA]
- Maxime Gobert [UNIV MONS]
- Guillaume Helbecque [UNIV LILLE]
- Julie Keisler [UNIV LILLE, CIFRE, from Feb 2022]
- Houssem Ouertatani [IRT SYSTEM X]
- David Redon [UNIV LILLE]
- Jerome Rouze [UNIV MONS, from Sep 2022]
Technical Staff
- Jan Gmys [INRIA, Engineer]
- Julie Keisler [UNIV LILLE, Engineer, until Feb 2022]
Administrative Assistant
- Karine Lewandowski [INRIA]
Visiting Scientists
- Tiago Carneiro [UNIV LUXEMBOURG, from Mar 2022]
- Jose Francisco Chicano Garcia [UNIV MALAGA, from Jul 2022 until Sep 2022]
- Gregoire Danoy [UNIV LUXEMBOURG, from Feb 2022]
- Rachid Ellaia [EMI MAROC, from Jul 2022 until Aug 2022]
- Nikolaus Frohner [Technische Universität Wien, TUW, Austria, until Jan 2022]
- Byung Woo Hong [Chung-Ang University, Seoul, Korea, from Jun 2022]
- Imanol Unanue [University of Basque Country, Spain, from May 2022 until Jul 2022]
2 Overall objectives
2.1 Presentation
Solving an optimization problem consists in optimizing (minimizing or maximizing) one or more objective function(s) subject to some constraints. This can be formulated as follows:
where is the decision variable vector of dimension , is the domain of (decision space), and is the objective function vector of dimension . The objective space is composed of all values of corresponding to the values of in the decision space.
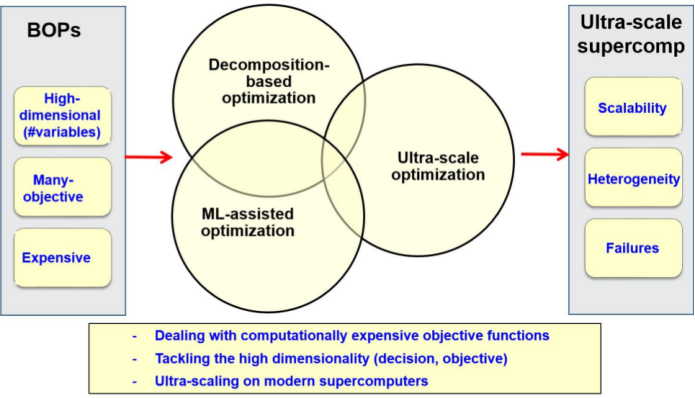
Nowadays, in many research and application areas we are witnessing the emergence of the big era (big data, big graphs, etc). In the optimization setting, the problems are increasingly big in practice. Big optimization problems (BOPs) refer to problems composed of a large number of environmental input parameters and/or decision variables (high dimensionality), and/or many objective functions that may be computationally expensive. For instance, in smart grids, there are many optimization problems for which it has to be considered a large number of consumers (appliances, electrical vehicles, etc.) and multiple suppliers with various energy sources. In the area of engineering design, the optimization process must often take into account a large number of parameters from different disciplines. In addition, the evaluation of the objective function(s) often consist(s) in the execution of an expensive simulation of a black-box complex system. This is for instance typically the case in aerodynamics where a CFD-based simulation may require several hours. On the other hand, to meet the high-growing needs of applications in terms of computational power in a wide range of areas including optimization, high-performance computing (HPC) technologies have known a revolution during the last decade (see Top500 international ranking (Edition of November 2022)). Indeed, HPC is evolving toward ultra-scale supercomputers composed of millions of cores supplied in heterogeneous devices including multi-core processors with various architectures, GPU accelerators and MIC coprocessors.
Beyond the “big buzzword” as some say, solving BOPs raises at least four major challenges: (1) tackling their high dimensionality in the decision space; (2) handling many objectives; (3) dealing with computationally expensive objective functions; and (4) scaling up on (ultra-scale) modern supercomputers. The overall scientific objectives of the Bonus project consist in addressing efficiently these challenges. On the one hand, the focus will be put on the design, analysis and implementation of optimization algorithms that are scalable for high-dimensional (in decision variables and/or objectives) and/or expensive problems. On the other hand, the focus will also be put on the design of optimization algorithms able to scale on heterogeneous supercomputers including several millions of processing cores. To achieve these objectives raising the associated challenges a program including three lines of research will be adopted (Fig. 1): decomposition-based optimization, Machine Learning (ML)-assisted optimization and ultra-scale optimization. These research lines are developed in the following section.
From the software standpoint, our objective is to integrate the approaches we will develop in our ParadisEO 3, 44 framework in order to allow their reuse inside and outside the Bonus team. The major challenge will be to extend ParadisEO in order to make it more collaborative with other software including machine learning tools, other (exact) solvers and simulators. From the application point of view, the focus will be put on two classes of applications: complex scheduling and engineering design.
3 Research program
3.1 Decomposition-based Optimization
Given the large scale of the targeted optimization problems in terms of the number of variables and objectives, their decomposition into simplified and loosely coupled or independent subproblems is essential to raise the challenge of scalability. The first line of research is to investigate the decomposition approach in the two spaces (decision and objective) and their combination, as well as their implementation on ultra-scale architectures. The motivation of the decomposition is twofold: first, the decomposition allows the parallel resolution of the resulting subproblems on ultra-scale architectures. Here also several issues will be addressed: the definition of the subproblems, their coding to allow their efficient communication and storage (checkpointing), their assignment to processing cores, etc. Second, decomposition is necessary for solving large problems that cannot be solved (efficiently) using traditional algorithms. Indeed, for instance with the popular NSGA-II algorithm the number of non-dominated solutions 1 increases drastically with the number of objectives leading to a very slow convergence to the Pareto Front 2. Therefore, decomposition-based techniques are gaining a growing interest. The objective of Bonus is to investigate various decomposition schemes and cooperation protocols between the subproblems resulting from the decomposition to generate efficiently global solutions of good quality. Several challenges have to be addressed: (1) how to define the subproblems (decomposition strategy), (2) how to solve them to generate local solutions (local rules), and (3) how to combine these latter with those generated by other subproblems and how to generate global solutions (cooperation mechanism), and (4) how to combine decomposition strategies in more than one space (hybridization strategy)?
The decomposition in the decision space can be performed following different ways according to the problem at hand. Two major categories of decomposition techniques can be distinguished: the first one consists in breaking down the high-dimensional decision vector into lower-dimensional and easier-to-optimize blocks of variables. The major issue is how to define the subproblems (blocks of variables) and their cooperation protocol: randomly vs. using some learning (e.g. separability analysis), statically vs. adaptively, etc. The decomposition in the decision space can also be guided by the type of variables i.e. discrete vs. continuous. The discrete and continuous parts are optimized separately using cooperative hybrid algorithms 52. The major issue of this kind of decomposition is the presence of categorial variables in the discrete part 48. The Bonus team is addressing this issue, rarely investigated in the literature, within the context of vehicle aerospace engineering design. The second category consists in the decomposition according to the ranges of the decision variables (search space decomposition). For continuous problems, the idea consists in iteratively subdividing the search (e.g. design) space into subspaces (hyper-rectangles, intervals, etc.) and select those that are most likely to produce the lowest objective function value. Existing approaches meet increasing difficulty with an increasing number of variables and are often applied to low-dimensional problems. We are investigating this scalability challenge (e.g. 10). For discrete problems, the major challenge is to find a coding (mapping) of the search space to a decomposable entity. We have proposed an interval-based coding of the permutation space for solving big permutation problems. The approach opens perspectives we are investigating 7, in terms of ultra-scale parallelization, application to multi-permutation problems and hybridization with metaheuristics.
The decomposition in the objective space consists in breaking down an original many-objective problem (MaOP) into a set of cooperative single-objective subproblems (SOPs). The decomposition strategy requires the careful definition of a scalarizing (aggregation) function and its weighting vectors (each of them corresponds to a separate SOP) to guide the search process towards the best regions. Several scalarizing functions have been proposed in the literature including weighted sum, weighted Tchebycheff, vector angle distance scaling, etc. These functions are widely used but they have their limitations. For instance, using weighted Tchebycheff might do harm diversity maintenance and weighted sum is inefficient when it comes to deal with nonconvex Pareto Fronts 42. Defining a scalarizing function well-suited to the MaOP at hand is therefore a difficult and still an open question being investigated in Bonus 6, 5. Studying/defining various functions and in-depth analyzing them to better understand the differences between them is required. Regarding the weighting vectors that determine the search direction, their efficient setting is also a key and open issue. They dramatically affect in particular the diversity performance. Their setting rises two main issues: how to determine their number according to the available computational resources? when (statically or adaptively) and how to determine their values? Weight adaptation is one of our main concerns that we are addressing especially from a distributed perspective. They correspond to the main scientific objectives targeted by our bilateral ANR-RGC BigMO project with City University (Hong Kong). The other challenges pointed out in the beginning of this section concern the way to solve locally the SOPs resulting from the decomposition of a MaOP and the mechanism used for their cooperation to generate global solutions. To deal with these challenges, our approach is to design the decomposition strategy and cooperation mechanism keeping in mind the parallel and/or distributed solving of the SOPs. Indeed, we favor the local neighborhood-based mating selection and replacement to minimize the network communication cost while allowing an effective resolution 5. The major issues here are how to define the neighborhood of a subproblem and how to cooperatively update the best-known solution of each subproblem and its neighbors.
To sum up, the objective of the Bonus team is to come up with scalable decomposition-based approaches in the decision and objective spaces. In the decision space, a particular focus will be put on high dimensionality and mixed-continuous variables which have received little interest in the literature. We will particularly continue to investigate at larger scales using ultra-scale computing the interval-based (discrete) and fractal-based (continuous) approaches. We will also deal with the rarely addressed challenge of mixed-continuous variables including categorial ones (collaboration with ONERA). In the objective space, we will investigate parallel ultra-scale decomposition-based many-objective optimization with ML-based adaptive building of scalarizing functions. A particular focus will be put on the state-of-the-art MOEA/D algorithm. This challenge is rarely addressed in the literature which motivated the collaboration with the designer of MOEA/D (bilateral ANR-RGC BigMO project with City University, Hong Kong). Finally, the joint decision-objective decomposition, which is still in its infancy 54, is another challenge of major interest.
3.2 Machine Learning-assisted Optimization
The Machine Learning (ML) approach based on metamodels (or surrogates) is commonly used, and also adopted in Bonus, to assist optimization in tackling BOPs characterized by time-demanding objective functions. The second line of research of Bonus is focused on ML-aided optimization to raise the challenge of expensive functions of BOPs using surrogates but also to assist the two other research lines (decomposition-based and ultra-scale optimization) in dealing with the other challenges (high dimensionality and scalability).
Several issues have been identified to make efficient and effective surrogate-assisted optimization. First, infill criteria have to be carefully defined to adaptively select the adequate sample points (in terms of surrogate precision and solution quality). The challenge is to find the best trade-off between exploration and exploitation to efficiently refine the surrogate and guide the optimization process toward the best solutions. The most popular infill criterion is probably the Expected Improvement (EI) 47 which is based on the expected values of sample points but also and importantly on their variance. This latter is inherently determined in the kriging model, this is why it is used in the state-of-the-art efficient global optimization (EGO) algorithm 47. However, such crucial information is not provided in all surrogate models (e.g. Artificial Neural Networks) and needs to be derived. In Bonus, we are currently investigating this issue. Second, it is known that surrogates allow one to reduce the computational burden for solving BOPs with time-consuming function(s). However, using parallel computing as a complementary way is often recommended and cited as a perspective in the conclusions of related publications. Nevertheless, despite being of critical importance parallel surrogate-assisted optimization is weakly addressed in the literature. For instance, in the introduction of the survey proposed in 45 it is warned that because the area is not mature yet the paper is more focused on the potential of the surveyed approaches than on their relative efficiency. Parallel computing is required at different levels that we are investigating.
Another issue with surrogate-assisted optimization is related to high dimensionality in decision as well as in objective space: it is often applied to low-dimensional problems. The joint use of decomposition, surrogates and massive parallelism is an efficient approach to deal with high dimensionality. This approach adopted in Bonus has received little effort in the literature. In Bonus, we are considering a generic framework in order to enable a flexible coupling of existing surrogate models within the state-of-the-art decomposition-based algorithm MOEA/D. This is a first step in leveraging the applicability of efficient global optimization into the multi-objective setting through parallel decomposition. Another issue which is a consequence of high dimensionality is the mixed (discrete-continuous) nature of decision variables which is frequent in real-world applications (e.g. engineering design). While surrogate-assisted optimization is widely applied in the continuous setting it is rarely addressed in the literature in the discrete-continuous framework. In 48, we have identified different ways to deal with this issue that we are investigating. Non-stationary functions frequent in real-world applications (see Section 4.1) is another major issue we are addressing using the concept of deep Gaussian Processes.
Finally, as quoted in the beginning of this section, ML-assisted optimization is mainly used to deal with BOPs with expensive functions but it will also be investigated for other optimization tasks. Indeed, ML will be useful to assist the decomposition process. In the decision space, it will help to perform the separability analysis (understanding of the interactions between variables) to decompose the vector of variables. In the objective space, ML will be useful to assist a decomposition-based many-objective algorithm in dynamically selecting a scalarizing function or updating the weighting vectors according to their performances in the previous steps of the optimization process 5. Such a data-driven ML methodology would allow us to understand what makes a problem difficult or an optimization approach efficient, to predict the algorithm performance 4, to select the most appropriate algorithm configuration 8, and to adapt and improve the algorithm design for unknown optimization domains and instances. Such an autonomous optimization approach would adaptively adjust its internal mechanisms in order to tackle cross-domain BOPs.
In a nutshell, to deal with expensive optimization the Bonus team will investigate the surrogate-based ML approach with the objective to efficiently integrate surrogates in the optimization process. The focus will especially be put on high dimensionality (e.g. using decomposition) with mixed discrete-continuous variables which is rarely investigated. The kriging metamodel (Gaussian Process or GP) will be considered in particular for engineering design (for more reliability) addressing the above issues and other major ones including mainly non stationarity (using emerging deep GP) and ultra-scale parallelization (highly needed by the community). Indeed, a lot of work has been reported on deep neural networks (deep learning) surrogates but not on the others including (deep) GP. On the other hand, ML will be used to assist decomposition: importance/interaction between variables in the decision space, dynamic building (selection of scalarizing functions, weight update, etc.) of scalarizing functions in the objective space, etc.
3.3 Ultra-scale Optimization
The third line of our research program that accentuates our difference from other (project-)teams of the related Inria scientific theme is the ultra-scale optimization. This research line is complementary to the two others, which are sources of massive parallelism and with which it should be combined to solve BOPs. Indeed, ultra-scale computing is necessary for the effective resolution of the large amount of subproblems generated by decomposition of BOPs, parallel evaluation of simulation-based fitness and metamodels, etc. These sources of parallelism are attractive for solving BOPs and are natural candidates for ultra-scale supercomputers 3. However, their efficient use raises a big challenge consisting in managing efficiently a massive amount of irregular tasks on supercomputers with multiple levels of parallelism and heterogeneous computing resources (GPU, multi-core CPU with various architectures) and networks. Raising such challenge requires to tackle three major issues: scalability, heterogeneity and fault-tolerance, discussed in the following.
The scalability issue requires, on the one hand, the definition of scalable data structures for efficient storage and management of the tremendous amount of subproblems generated by decomposition 50. On the other hand, achieving extreme scalability requires also the optimization of communications (in number of messages, their size and scope) especially at the inter-node level. For that, we target the design of asynchronous locality-aware algorithms as we did in 43, 53. In addition, efficient mechanisms are needed for granularity management and coding of the work units stored and communicated during the resolution process.
Heterogeneity means harnessing various resources including multi-core processors within different architectures and GPU devices. The challenge is therefore to design and implement hybrid optimization algorithms taking into account the difference in computational power between the various resources as well as the resource-specific issues. On the one hand, to deal with the heterogeneity in terms of computational power, we adopt in Bonus the dynamic load balancing approach based on the Work Stealing (WS) asynchronous paradigm 4 at the inter-node as well as at the intra-node level. We have already investigated such approach, with various victim selection and work sharing strategies in 53, 7. On the other hand, hardware resource specific-level optimization mechanisms are required to deal with related issues such as thread divergence and memory optimization on GPU, data sharing and synchronization, cache locality, and vectorization on multi-core processors, etc. These issues have been considered separately in the literature including our works 9, 1. Actually, in most of existing works related to GPU-accelerated optimization only a single CPU core is used. This leads to a huge resource wasting especially with the increase of the number of processing cores integrated into modern processors. Using jointly the two components raises additional issues including data and work partitioning, the optimization of CPU-GPU data transfers, etc.
Another issue the scalability induces is the increasing probability of failures in modern supercomputers 51. Indeed, with the increase of their size to millions of processing cores their Mean-Time Between Failures (MTBF) tends to be shorter and shorter 49. Failures may have different sources including hardware and software faults, silent errors, etc. In our context, we consider failures leading to the loss of work unit(s) being processed by some thread(s) during the resolution process. The major issue, which is particularly critical in exact optimization, is how to recover the failed work units to ensure a reliable execution. Such issue is tackled in the literature using different approaches: algorithm-based fault tolerance, checkpoint/restart (CR), message logging and redundancy. The CR approach can be system-level, library/user-level or application-level. Thanks to its efficiency in terms of memory footprint, adopted in Bonus 2, the application-level approach is commonly and widely used in the literature. This approach raises several issues mainly: (1) which critical information defines the state of the work units and allows to resume properly their execution? (2) when, where and how (using which data structures) to store it efficiently? (3) how to deal with the two other issues: scalability and heterogeneity?
The last but not least major issue which is another roadblock to exascale is the programming of massive-scale applications for modern supercomputers. On the path to exascale, we will investigate the programming environments and execution supports able to deal with exascale challenges: large numbers of threads, heterogeneous resources, etc. Various exascale programming approaches are being investigated by the parallel computing community and HPC builders: extending existing programming languages (e.g. DSL-C++) and environments/libraries (MPI+X, etc.), proposing new solutions including mainly Partitioned Global Address Space (PGAS)-based environments (Chapel, UPC, X10, etc.). It is worth noting here that our objective is not to develop a programming environment nor a runtime support for exascale computing. Instead, we aim to collaborate with the research teams (inside or outside Inria) having such objective.
To sum up, we put the focus on the design and implementation of efficient big optimization algorithms dealing jointly (uncommon in parallel optimization) with the major issues of ultra-scale computing mainly the scalability up to millions of cores using scalable data structures and asynchronous locality-aware work stealing, heterogeneity addressing the multi-core and GPU-specific issues and those related to their combination, and scalable GPU-aware fault tolerance. A strong effort will be devoted to this latter challenge, for the first time to the best of our knowledge, using application-level checkpoint/restart approach to deal with failures.
4 Application domains
4.1 Introduction
For the validation of our findings we obviously use standard benchmarks to facilitate the comparison with related works. In addition, we also target real-world applications in the context of our collaborations and industrial contracts. From the application point of view two classes are targeted: complex scheduling and engineering design. The objective is twofold: proposing new models for complex problems and solving efficiently BOPs using jointly the three lines of our research program. In the following, are given some use cases that are the focus of our current industrial collaborations.
4.2 Big optimization for complex scheduling
Three application domains are targeted: energy and transport & logistics. In the energy field, with the smart grid revolution (multi-)house energy management is gaining a growing interest. The key challenge is to make elastic with respect to the energy market the (multi-)house energy consumption and management. This kind of demand-side management will be of strategic importance for energy companies in the near future. In collaboration with the EDF energy company we are working on the formulation and solving of optimization problems on demand-side management in smart micro-grids for single- and multi-user frameworks. These complex problems require taking into account multiple conflicting objectives and constraints and many (deterministic/uncertain, discrete/continuous) parameters. A representative example of such BOPs that we are addressing is the scheduling of the activation of a large number of electrical and thermal appliances for a set of homes optimizing at least three criteria: maximizing the user's confort, minimizing its energy bill and minimzing peak consumption situations. On the other hand, we investigate the application of parallel Bayesian optimization for efficient energy storage in collaboration with the energy engineering department of University of Mons.
4.3 Big optimization for engineering design
The focus is for now put on the aerospace vehicle design, a complex multidisciplinary optimization process, we are exploring in collaboration with ONERA. The objective is to find the vehicle architecture and characteristics that provide the optimal performance (flight performance, safety, reliability, cost etc.) while satisfying design requirements 41. A representative topic we are investigating, and will continue to investigate throughout the lifetime of the project given its complexity, is the design of launch vehicles that involves at least four tightly coupled disciplines (aerodynamics, structure, propulsion and trajectory). Each discipline may rely on time-demanding simulations such as Finite Element analyses (structure) and Computational Fluid Dynamics analyses (aerodynamics). Surrogate-assisted optimization is highly required to reduce the time complexity. In addition, the problem is high-dimensional (dozens of parameters and more than three objectives) requiring different decomposition schemas (coupling vs. local variables, continuous vs. discrete even categorial variables, scalarization of the objectives). Another major issue arising in this area is the non-stationarity of the objective functions which is generally due to the abrupt change of a physical property that often occurs in the design of launch vehicles. In the same spirit than deep learning using neural networks, we use Deep Gaussian Processes (DGPs) to deal with non-stationary multi-objective functions. Finally, the resolution of the problem using only one objective takes one week using a multi-core processor. The first way to deal with the computational burden is to investigate multi-fidelity using DGPs to combine efficiently multiple fidelity models. This approach has been investigated this year within the context of the PhD thesis of A. Hebbal. In addition, ultra-scale computing is required at different levels to speed up the search and improve the reliability which is a major requirement in aerospace design. This example shows that we need to use the synergy between the three lines of our research program to tackle such BOPs.
Finally, we recently started to investigate the application of surrogate-based optimization in the epidemiologic context. Actually, we address in collaboration with Monash University (Australia) the contact reduction and vaccines allocation of Covid-19 and Tuberculosis.
5 Social and environmental responsibility
Optimization is ubiquitous to countless modern engineering and scientific applications with a deep impact on society and human beings. As such, the research of the Bonus team contributes to the establishment of high-level efficient solving techniques, improving solving quality, and addressing applications being more and more large-scale, complex, and beyond the solving ability of standard optimization techniques.
Furthermore, Bonus has performed technology transfer actions using different ways: open-source software development, transfer-to-industry initiatives, and teaching.
Our team has also initiated a start-up creation project. Actually, G. Pruvost who did his Ph.D thesis within Bonus (defended on Dec. 2021), co-founded the OPTIMO Technologies start-up, dealing with sustainable mobility issues (e.g. sustainable, personalized and optimized itinerary planning).
Another vector we used for the transfer to society is teaching. BONUS transferred/is transferring its knowledge and skills to Master students through teaching and internships. For instance, we allowed hundreds of students to get started with HPC optimization and ML.
6 Highlights of the year
6.1 Awards
- Best Paper nomination at the ACM GECCO'2022 26 (R. Cosson, B. Derbel and A. Liefooghe), the EMO@GECCO track (Evolutionary Multi-objective Optimization), in collaboration with R. Santana from the University of Basque Country, Spain.
6.2 Other highlights
7 New software and platforms
The core activity of Bonus is focused on the design, implementation and analysis of algorithmic approaches for efficient and effective optimization. In addition, we have an increasing activity in software development driven by our goal of making our algorithmic contributions freely available for the optimization community. On the one hand, this leads us to develop some homemade prototype codes: Permutation Branch-and-Bound (pBB) and Python library for Surrogate-based Optimization (pySBO). On the other hand, we started in 2020 to develop the more ambitious Python-based Parallel and distributed Evolving Objects (pyParadisEO) software framework. In addition, Bonus is strongly involved in the activities related to the Grid'5000 nation-wide distributed testbed as a scientific leader for the site located at Lille. Finally, the different software tools and Grid'5000 testbed are described below.
7.1 New software
7.1.1 pBB
-
Name:
Permutation Branch-and-Bound
-
Keywords:
Optimisation, Parallel computing, Data parallelism, GPU, Scheduling, Combinatorics, Distributed computing
-
Functional Description:
The algorithm proceeds by implicit enumeration of the search space by parallel exploration of a highly irregular search tree. pBB contains implementations for single-core, multi-core, GPU and heterogeneous distributed platforms. Thanks to its hierarchical work-stealing mechanism, required to deal with the strong irregularity of the search tree, pBB is highly scalable. Scalability with over 90% parallel efficiency on several hundreds of GPUs has been demonstrated on the Jean Zay supercomputer located at IDRIS.
- URL:
-
Contact:
Jan Gmys
7.1.2 ParadisEO
-
Keyword:
Parallelisation
-
Scientific Description:
ParadisEO (PARallel and DIStributed Evolving Objects) is a C++ white-box object-oriented framework dedicated to the flexible design of metaheuristics. Based on EO, a template-based ANSI-C++ compliant evolutionary computation library, it is composed of four modules: * Paradiseo-EO provides tools for the development of population-based metaheuristic (Genetic algorithm, Genetic programming, Particle Swarm Optimization (PSO)...) * Paradiseo-MO provides tools for the development of single solution-based metaheuristics (Hill-Climbing, Tabu Search, Simulated annealing, Iterative Local Search (ILS), Incremental evaluation, partial neighborhood...) * Paradiseo-MOEO provides tools for the design of Multi-objective metaheuristics (MO fitness assignment shemes, MO diversity assignment shemes, Elitism, Performance metrics, Easy-to-use standard evolutionary algorithms...) * Paradiseo-PEO provides tools for the design of parallel and distributed metaheuristics (Parallel evaluation, Parallel evaluation function, Island model) Furthermore, ParadisEO also introduces tools for the design of distributed, hybrid and cooperative models: * High level hybrid metaheuristics: coevolutionary and relay model * Low level hybrid metaheuristics: coevolutionary and relay model
-
Functional Description:
Paradiseo is a software framework for metaheuristics (optimisation algorithms aimed at solving difficult optimisation problems). It facilitates the use, development and comparison of classic, multi-objective, parallel or hybrid metaheuristics.
- URL:
-
Contact:
El-Ghazali Talbi
-
Partners:
CNRS, Université de Lille
7.1.3 pyparadiseo
-
Keywords:
Optimisation, Framework
-
Functional Description:
pyparadiseo is a Python version of ParadisEO, a C++-based open-source white-box framework dedicated to the reusable design of metaheuristics. It allows the design and implementation of single-solution and population-based metaheuristics for mono- and multi-objective, continuous, discrete and mixed optimization problems.
- URL:
-
Contact:
Jan Gmys
7.1.4 pySBO
-
Name:
PYthon library for Surrogate-Based Optimization
-
Keywords:
Parallel computing, Evolutionary Algorithms, Multi-objective optimisation, Black-box optimization, Optimisation
-
Functional Description:
The pySBO library aims at facilitating the implementation of parallel surrogate-based optimization algorithms. pySBO provides re-usable algorithmic components (surrogate models, evolution controls, infill criteria, evolutionary operators) as well as the foundations to ensure the components inter-changeability. Actual implementations of sequential and parallel surrogate-based optimization algorithms are supplied as ready-to-use tools to handle expensive single- and multi-objective problems. The illustrated documentation of pySBO is available on-line through a dedicated web-site.
- URL:
-
Contact:
Guillaume Briffoteaux
7.1.5 moead-framework
-
Name:
multi-objective evolutionary optimization based on decomposition framework
-
Keywords:
Evolutionary Algorithms, Multi-objective optimisation
-
Scientific Description:
Moead-framework aims to provide a python modular framework for scientists and researchers interested in experimenting with decomposition-based multi-objective optimization. The original multi-objective problem is decomposed into a number of single-objective sub-problems that are optimized simultaneously and cooperatively. This Python-based library provides re-usable algorithm components together with the state-of-the-art multi-objective evolutionary algorithm based on decomposition MOEA/D and some of its numerous variants.
-
Functional Description:
The package is based on a modular architecture that makes it easy to add, update, or experiment with decomposition components, and to customize how components actually interact with each other. A documentation is available online. It contains a complete example, a detailed description of all available components, and two tutorials for the user to experiment with his/her own optimization problem and to implement his/her own algorithm variants.
- URL:
-
Contact:
Geoffrey Pruvost
7.1.6 Zellij
-
Keywords:
Global optimization, Partitioning, Metaheuristics, High Dimensional Data
-
Functional Description:
The package generalizes a family of decomposition algorithms by implementing four distinct modules (geometrical objects, tree search algorithms, exploitation and exploration algorithms such as Genetic Algorithm, Bayesian Optimization or Simulated Annealing). The package is divided into two versions, a regular and a parallel one. The main target of Zellij is to tackle HyperParameter Optimization (HPO) and Neural Architecture Search (NAS). Thanks to to this framework, we are able to reproduce various decomposition based algorithms, such as DIRECT, Simultaneous Optimistic Optimization, Fractal Decomposition Algorithm, FRACTOP... Future works will focus on multi-objective problems, NAS, distributed version and a graphic interface for monitoring and plotting.
- URL:
-
Contact:
Thomas Firmin
7.2 New platforms
7.2.1 Grid'5000 testbed: major achievements in 2022
Participants: Nouredine Melab [contact person], Dimitri Delabroye.
- Keywords: Experimental testbed, large-scale computing, high-performance computing, GPU computing, cloud computing, big data
-
Functional description: Grid'5000 is a project initiated in 2003 by the French government and later supported by different research organizations including Inria, CNRS, the french universities, Renater which provides the wide-area network, etc. The overall objective of Grid'5000 was to build by 2007 a mutualized nation-wide experimental testbed composed of at least 5000 processing units and distributed over several sites in France (one of them located at Lille). From a scientific point of view, the aim was to promote scientific research on large-scale distributed systems. Beyond BONUS, Grid'5000 is highly important for the HPC-related communities from our three institutions (ULille, Inria and CNRS) as well as from outside.
Within the framework of CPER contract “Data", the equipment of Grid'5000 at Lille has been renewed in 2017-2018 in terms of hardware resources (GPU-powered servers, storage, PDUs, etc.) and infrastructure (network, inverter, etc.). The renewed testbed has been used extensively by many researchers from Inria and outside. Half-day trainings have been organized with the collaboration of Bonus to allow the newcomer users to get started with the use of the testbed. A new IA-dedicated CPER contract “CornelIA" has been accepted (2021-2027). As scientific leader of Grid'5000 at Lille, N. Melab is being strongly involved in the renewal of the equipment and the recruitment of engineering staff.
- URL: Grid'5000
8 New results
During the year 2022, we addressed different issues/challenges related to the three lines of our research program. The major contributions are summarized in the following sections. Besides, alongside these contributions we came out with other contributions 14, 29, 28, 30, 18 that are not discussed here-after to keep the presentation focused on the major achievements.
8.1 Decomposition-based optimization
We report three major contributions in decomposition-based optimization. The decomposition is performed in the decision space using a tree or graph-based approach. The first one 12 concerns discrete optimization using the tree-based state-of-the-art Branch-and-Bound algorithm and its petascale parallelization to uncommonly solve challenging unsolved standard benchmarks. The two other ones are respectively related to graybox and blackbox optimization. Actually, in 23, we investigated the design of large-scale combinatorial graybox problems using variable interaction graphs. In addition, in 33 we addressed tree-based optimistic optimization for continuous blackbox functions. These contributions are summarized in the following.
8.1.1 Exact parallel decomposition for permutational flowshop
Participants: Jan Gmys [contact person].
Among state-of-the-art exact algorithms, the Branch-and-bound generic algorithm is based on decomposing the search space following a tree search strategy. In 12, we specifically tackle Makespan minimization in permutation flow-shop scheduling, wh is a well-known hard combinatorial optimization problem. Among the 120 standard benchmark instances proposed by E. Taillard in 1993, 23 have remained unsolved for almost three decades. In this work, we present our attempts to solve these instances to optimality using parallel Branch-and-Bound (BB) on the GPU-accelerated Jean Zay supercomputer. We report the exact solution of 11 previously unsolved problem instances and improved upper bounds for eight instances. The solution of these problems requires both algorithmic improvements and leveraging the computing power of peta-scale high-performance computing platforms. The challenge consists in efficiently performing parallel depth-first traversal of a highly irregular and fine-grained search tree on distributed systems composed of hundreds of massively parallel accelerator devices and multicore processors. We present and discuss the design and implementation of our decomposition-based BB for permutations, and experimentally evaluate its parallel performance on up to 384 V100 GPUs (2 million CUDA cores) and 3840 CPU cores. The optimality proof for the largest solved instance requires about 64 CPU-years of computation—using 256 GPUs and over 4 million parallel search agents, the traversal of the search tree is completed in 13 hours, exploring nodes.8.1.2 Large-scale graybox decomposition
Participants: Bilel Derbel [contact person], Lorenzo Canonne.
In 23, we revisited the state-of-the-art graybox DRILS algorithm (Deterministic Recombination and Iterated Local Search) which was initially designed to tackle large-scale k-bounded pseudo-boolean optimization problems by additively decomposing the underlying objective function on the basis of the so-called variable interaction graph (VIG). The DRILS algorithm follows the framework of a hybrid iterated local search by combining the efficient identification of improving moves and the fast recombination of local optima. Besides, the DRILS algorithm uses a perturbation mechanism in order to feed state-of-the-art graybox crossovers with promising local optima. The perturbation is a key element to avoid that the search gets trapped. In this paper, we focused on two main questions: (i) how the perturbation is performed, and (ii) how strong it should be. We propose two alternative designs of the perturbation within the framework of DRILS. The so-obtained algorithms are proved to provide substantial improvements. This is demonstrated based on extensive experiments using a diverse set of NKQ-landscapes, with different degrees of ruggedness, as well as, different dimensions ranging from relatively small (thounsands variables) to very large (million variables). Besides, we provide a comprehensive analysis on the impact of the proposed mechanisms allowing us to highlight the guiding principles for an accurate design and configuration of the perturbation as a function of landscape characteristics.
8.1.3 Parallel simultaneous optimistic optimisation for continuous blackbox functions
Participants: Bilel Derbel [contact person], David Redon, Pierre Fortin [Univ. Lille].
In 33, we consider the design of parallel blackbox numerical optimization using the so-called Simultaneous Optimistic Optimization (SOO) algorithm. SOO is a deterministic tree-based global optimizer which is based on decomposing the search space in different cells that are searched until the global optimum is eventually found. A key design ingredient allowing SOO to expose theoretically provable performance guarantees (under mild conditions) is to balance the exploitation/exploration trade-off when selecting and expanding the so-defined cells. In this work, we consider the efficient shared-memory parallelization of SOO on a high-end HPC architecture with dozens of CPU cores. We thereby propose different strategies based on eliciting the possible levels of parallelism underlying the SOO algorithm. We show that the naive approach, performing multiple evaluations of the blackbox function in parallel, does not scale with the number of cores. By contrast, we show that a parallel design based on the SOO-tree traversal is able to provide substantial improvements in terms of scalability and performance. We validate our parallel design on a compute server with two 64-core processors, using a number of diverse benchmark functions with both increasing dimensions (up to 40) and number of cores (up to 256 with SMT).
8.2 ML-assisted optimization
As pointed out in our research program 3.2, we investigate the ML-assisted optimization following two directions: (1) efficient building of surrogates and their integration into optimization algorithms to deal with expensive black-box objective functions, and (2) automatically building and predicting/improving optimization algorithms. Following these two directions, we contributed with some new results in 2022. Regarding the first direction, we revisited in 15 the state-of-the-art EGO algorithm in the context of multi-objective context considering uncommonly the correlation between objectives. The proposed approach has been validated within the context of aerospace vehicle design. In addition, we investigated EGO in 17 for parameter exploration in mechanical design. Following the second direction, we investigated reinforcement learning 35, 27 and fitness landscape analysis 25, 11, 26 in the multi-objective context. Furthermore, we studied neural embeddings for single-objective fitness landscape analysis 34. Finally, we proposed some surveys/taxonomies on the synergy between ML and optimzation in 20, 16, 19.
8.2.1 Gaussien Process-guided optimization for solving Real-World problems
Participants: Nouredine Melab [contact person], El-Ghazali Talbi, Ali Hebbal, Mathieu Balesdent, Loïc Brevault.
Bayesian Optimization has become a widely used approach to perform optimization involving computationally intensive black-box functions, such as the design optimization of complex engineering systems. It is often based on Gaussian Process regression as a Bayesian surrogate model of the exact functions. Bayesian Optimization has been applied to single and multi-objective optimization problems.
In the case of multi-objective optimization, the Bayesian models used in optimization often consider the multiple objectives separately and do not take into account the possible correlation between them near the Pareto front. In 15, a Multi-Objective Bayesian Optimization algorithm based on Deep Gaussian Process is proposed in order to jointly model the objective functions. It allows to take advantage of the correlations (linear and non-linear) between the objectives in order to improve the search space exploration and speed up the convergence to the Pareto front. The proposed algorithm is compared to classical Bayesian Optimization in four analytical functions and two aerospace engineering problems. On the other hand, we introduce in 17, a novel approach for the inverse identification of model parameters using EGO in mechanical engineering.
8.2.2 Multi-objective reinforcement learning
Participants: El-Ghazali Talbi [contact person], Pascal Bouvry [University of Luxembourg], Gabriel Duflo [University of Luxembourg], Grégoire Danoy [University of Luxembourg], Florian Felten [University of Luxembourg].
The fields of Reinforcement Learning (RL) and Optimization aim at finding an optimal solution to a problem, characterized by an objective function. On the one hand, the exploration-exploitation dilemma (EED) is a well known subject in those fields. On the other hand, many real-world problems involve the optimization of multiple objectives.
In 35, we introduce a modular framework for Multi-Policy Multi-Objective Reinforcement Learning (MPMORL) as an opportunity to learn various optimised behaviours. The proposed framework helps to study the EED in Inner-Loop MPMORL algorithms. We also present three new exploration strategies inspired from the metaheuristics domain. To assess the performance of our methods on various environments, we use a classical benchmark - the Deep Sea Treasure (DST) - as well as propose a harder version of it. Our experiments show all of the proposed strategies outperform the existing standard -greedy based methods.
In 27, we specifically focus on the so-called Unmanned Aerial Vehicles (UAVs) for civilian applications. UAVs feature unique properties such as three-dimensional mobility and payload flexibility which provide unprecedented advantages when conducting missions like infrastructure inspection or search and rescue. In this context, we consider to use several UAVs as a swarm as a novel promising approach. Our goal is then to automate the design of UAV swarming behaviors to tackle an area coverage problem. We there-by investigate the modeling of this problem from a multi-objective perspective. Then, we contribute a hyper-heuristic based on multi-objective reinforcement learning for generating distributed heuristics. Experimental results demonstrate the good stability of the generated heuristic on instances with different sizes and its capacity to well balance the multiple objectives of the optimization problem.
8.2.3 Multi-objective fitness landscape analysis
Participants: Bilel Derbel [contact person], Arnaud Liefooghe [contact person], Raphaël Cosson, Sébastien Verel [ULCO, Calais], Qingfu Zhang [City University, Hong Kong], Hernan Aguirre [Shinshu University, Japan], Kiyoshi Tanaka [Shinshu University, Japan], Richard Allmendinger [The University of Manchester, UK], Andrzej Jaszkiewicz [Poznan University of Technology, Poland], Christiane Tammer [MLU, Martin-Luther-Universität Halle Wittenberg], Roberto Santana [University of Basque Country, Spain].
The difficulty of solving a multi-objective optimization problem is impacted by a number of factors implying different challenges.
In 25, we address the design of effective multi-objective features enabling the development of automated landscape-aware multi-objective techniques. More particularly, we study simple cost-adjustable sampling strategies for extracting different state-of-the-art features. Based on extensive experiments, we report a comprehensive analysis on the impact of sampling on landscape feature values, and the subsequent automated algorithm selection task. In particular, we identify different global trends of feature values leading to non-trivial cost-vs-accuracy trade-off(s), and we provide evidence that the feature sampling strategy can improve the prediction accuracy of automated algorithm selection.
In 11, we study how the difficulty of solving a multi-objective optimization problem is impacted by the number of objectives to be optimized. In fact, the presence of many objectives typically introduces a number of challenges that affect the choice/design of optimization algorithms. We investigate the drivers of these challenges from two angles: (i) the influence of the number of objectives on problem characteristics and (ii) the practical behavior of commonly used procedures and algorithms for coping with many objectives. In addition to reviewing various drivers, we report theoretical and empirical findings allowing us to derive practical recommendations to support algorithm design.
Finally, in 26, we investigate the difficulty of searching multi-objective landscapes with heterogeneous objectives in terms of multi-modality. We first propose a model of multi-objective NK landscapes, where each objective has a different degree of variable interactions, as a benchmark to investigate heterogeneous multi-objective optimization problems. We then show that the use of a rank-annotated neighborhood network with labeled local optimal solutions, together with landscape metrics extracted from the heterogeneous objectives, thoroughly characterizes bi-objective NK landscapes with a different level of heterogeneity among the objectives.
8.2.4 Neural embeddings for NK-landscape analysis
Participants: Bilel Derbel [contact person], Arnaud Liefooghe [contact person], Roberto Santana [University of Basque Country, Spain].
Understanding the landscape underlying a given optimization problem is of fundamental interest. Different representations may be used to better understand how the ruggedness of the landscape is influenced by the problem parameters, such as the problem dimension, the degree of non-linearity and the structure of variable interactions. In 34, we focus on NK-landscpae as a representative and challenging combinatorial optimization benchmark. We then propose to use neural embedding, that is a continuous vectorial representation obtained as a result of applying a neural network to a prediction task, in order to investigate the characteristics of NK landscapes. The main assumption is that neural embeddings are able to capture important features that reflect the difficulty of the landscape. We propose a method for constructing NK embeddings, together with metrics for evaluating to what extent this embedding space encodes valuable information from the original NK landscape. Furthermore, we study how the embedding dimensionality and the parameters of the NK model influence the characteristics of the NK embedding space. Finally, we evaluate the performance of optimizers that solve the continuous representations of NK models by searching for solutions in the embedding space.
8.2.5 Surveys on the Synergy between ML and optimization
Participants: El-Ghazali Talbi [contact person], Maryam Karimi Mamaghan [IMT Atlantique, Brest, France], Mehrdad Mohammadi [IMT Atlantique, Brest, France], Patrick Meyer [IMT Atlantique, Brest, France], Amir Mohammad Karimi-Mamaghan [University of Tehran, Iran].
During the past few years, research in applying machine learning (ML) to design efficient, effective, and robust metaheuristics has become increasingly popular. Many of those machine learning-supported metaheuristics have generated high-quality results and represent state-of-the-art optimization algorithms. Although various approaches have been proposed, there is a lack of a comprehensive survey and taxonomy on this research topic. In 20, 16, we investigate different opportunities for using ML into metaheuristics. In particular, we define uniformly the various ways synergies that might be achieved, and provide a review on the use of ML techniques in the design of different elements of meta-heuristics for different purposes including algorithm selection, fitness evaluation, initialization, evolution, parameter setting, and cooperation. A detailed taxonomy is also proposed according to the concerned search component: target optimization problem and low-level and high-level components of metaheuristics.
Besides, specifically with respect to deep neural networks (DNN), research in applying optimization approaches in the automatic design of DNN has also become increasingly popular. Although various approaches have been proposed, there is a lack of a comprehensive survey and taxonomy on this hot research topic as well. In 19, we propose a unified way to describe the various optimization algorithms that focus on common and important search components of optimization algorithms: representation, objective function, constraints, initial solution(s), and variation operators.
8.3 Parallel optimization
During the year 2022, we have contributed with some parallel optimization techniques. In 13, 31, we investigated the design and the implementation of parallel batch-based Bayesian algorithms for expensive optimization problems. The proposed approach has been validated using an energy storage problem. In 21, 22, we investigated the design of parallel surrogate-assisted algorithms with application to Covid-19 problems (vaccines allocation and contact reduction). Two approaches have been considered: surrogate-assisted vs. surrogate-guided algorithms and their hybridization in 21. The multi-objective context is also addressed in 22. In 32, 24, we investigated the analysis of the Chapel productivity-aware programming language within the context of parallel optimization. These contributions are discussed in more details in the following.
8.3.1 Parallel Batch-based Bayesian Optimization with application to energy storage
Participants: Nouredine Melab [contact person], Jan Gmys, Maxime Gobert [University of Mons], Jean-François Toubeau [University of Mons], Daniel Tuyttens [University of Mons], François Vallée [University of Mons].
Bayesian Optimization (BO) with Gaussian process regression is a popular framework for the optimization of time-consuming cost functions. However, the joint exploitation of BO and parallel processing capabilities remains challenging, despite intense research efforts over the last decade. In particular, the choice of a suitable batch-acquisition process, responsible for selecting promising candidate solutions for batch-parallel evaluation, is crucial. Even though some general recommendations can be found in the literature, many of its hyperparameters remain problem-specific. Moreover, the limitations of existing approaches in terms of scalability, especially for moderately expensive objective functions, are barely discussed. In 13, 31, we investigate five parallel BO algorithms based on different batch-acquisition processes, applied to the optimal scheduling of Underground Pumped Hydro-Energy Storage stations and classical benchmark functions. Efficient management of such energy-storage units requires parallel BO algorithms able to find solutions in a very restricted time to comply with the responsive energy markets. Our experimental results shed the light on the effectiveness of existing parallel BO algorithms, as well as, of the effective batch size for a good trade-off between execution speed and solution quality.
8.3.2 Parallel surrogate-based optimization with application to COVID-19 problems
Participants: Nouredine Melab [contact person], Guillaume Briffoteaux, Mohand Mezmaz [University of Mons], Romain Ragonnet [Monash University [Melbourne]], Daniel Tuyttens [University of Mons], Pierre Tomenko [University of Mons].
Parallel Surrogate-Assisted Evolutionary Algorithms (P-SAEAs) are based on surrogate-informed reproduction operators to propose new candidates to solve computationally expensive optimization problems. Differently, Parallel Surrogate-Driven Algorithms (P-SDAs) rely on the optimization of a surrogate-informed metric to acquire new promising solutions. The former are promoted to deal with moderately computationally expensive problems while the latter are put forward on very costly problems. In 21, we investigate the design of hybrid strategies combining the acquisition processes of both P-SAEAs and P-SDAs to retain the best of both categories of methods. The objective is to reach robustness with respect to the computational budgets and parallel scalability. In 22, we tackle the simulation-based and computationally expensive COVID-19 vaccines allocation problem. We investigate a multi-objective formulation considering simultaneously the total number of deaths, peak hospital occupancy and relaxation of mobility restrictions. We then consider to compare the performance of recently proposed surrogate-free and surrogate-based parallel algorithms.
8.3.3 Chapel-based high performance optimization
Participants: Nouredine Melab [contact person], Guillaume Helbecque, Jan Gmys, Pascal Bouvry [University of Luxembourg], Tiago Carneiro [University of Luxembourg], Loizos Koutsantonis [University of Luxembourg], Emmanuel Kieffer [University of Luxembourg].
The increase in complexity, diversity and scale of high performance computing environments, as well as the increasing sophistication of parallel applications and algorithms call for productivity-aware programming languages for high-performance computing. Among them, the Chapel programming language stands out as one of the more successful approaches based on the Partitioned Global Address Space programming model. Although Chapel is designed for productive parallel computing at scale, the question of its effectiveness and competitiveness with well-established conventional parallel programming environments arises.
In 32, we compare the performance of Chapel-based fractal generation on shared- and distributed- memory platforms with corresponding OpenMP and MPI+X implementations. The parallel computation of the Mandelbrot set is chosen as a test-case for its high degree of parallelism and its irregular workload. Experiments are performed on a cluster composed of 192 cores using the French national testbed Grid'5000. Chapel as well as its default tasking layer demonstrate high performance in shared-memory context, while Chapel competes with hybrid MPI+OpenMP in distributed-memory environment.
In 24, we consider Chapel-based implementation of highly irregular tree-based search algorithms for combinatorial optimization problems. The parameterization of such parallel algorithms is complex, consisting of several parameters, even if a high-productivity language is used in their conception. We there-by present a local search for automatic parameterization of ChapelBB, a distributed tree search Chapel based algorithm. The main objective of the proposed heuristic is to overcome the limitation of manual parameterization, which covers a limited feasible space. The reported results show that the heuristic-based parameterization increases up to 30% the performance of ChapelBB on 2048 cores (4096 threads) when solving the N-Queens problem and up to 31% when solving instances of the Flow-shop scheduling problem.
9 Bilateral contracts and grants with industry
9.1 Bilateral grants with industry
Our current industrial granted projects are completely at the heart of the Bonus project. They are summarized in the following.
- EDF (2021-2024, Paris): this joint project with EDF, a major electrical power player in France, targets the automatic design and configuration of deep neural networks applied to the energy consumption forecasting. A budget of 62K€ is initially allocated, in the context of the PGMO programme of Jacques Hadamard foundation of mathematics. A budget of 150K€ is then allocated for funding a PhD thesis (CIFRE).
- ONERA & CNES (2016-2023, Paris): the focus of this project with major European players in vehicle aerospace is put on the design of aerospace vehicles, a high-dimensional expensive multidisciplinary problem. Such problem needs the use of the research lines of Bonus to be tackled effectively and efficiently. Two jointly supervised PhD students (J. Pelamatti and A. Hebbal) have been involved in this project. The PhD thesis of J. Pelamatti has been defended in March 2020 and that of A. Hebbal 46 in January 2021. Another one (J. Gamot) has started in November 2020. The objective of this latter is to deal with the design and implementation of ultra-scale multi-objective highly constrained optimization methods for solving the internal layout problem of future aerospace systems.
- Confiance.ai project (2021-2024, Paris): this joint project with the SystemX Institute of Research and Technology (IRT) and Université Polytechnique Hauts-de-France is focused on multi-objective automated design and optimization of deep neural networks with applications to embedded systems. A Ph.D student (H. Ouertatani) has been hired in Oct. 2021 to work on this topic.
10 Partnerships and cooperations
10.1 International initiatives
10.1.1 Associate Teams in the framework of an Inria International Lab or in the framework of an Inria International Program
AnyScale
Participants: E-G Talbi.
-
Title:
Parallel Fractal-based Chaotic optimization: Application to the optimization of deep neural networks for energy management
-
Duration:
2022-2024
-
Coordinator:
Rachid Ellaia (ellaia@emi.ac.ma)
-
Partners:
- Ecole Mohammadia d'Ingénieurs Rabat (Maroc)
-
Inria contact:
El-Ghazali Talbi
-
Summary:
Many scientific and industrial disciplines are more and more concerned by big optimisation problems (BOPs). BOPs are characterised by a huge number of mixed decision variables and/or many expensive objective functions. Bridging the gap between computational intelligence, high performance computing and big optimisation is an important challenge for the next decade in solving complex problems in science and industry.
The goal of this associated team project is to come up with breakthrough in nature-inspired algorithms jointly based on any-scale fractal decomposition and chaotic approaches for BOPs. Those algorithms are massively parallel and can be efficiently designed and implemented on heterogeneous exascale supercomputers including millions of CPU/GPU (Graphics Processing Units) cores. The convergence between chaos, fractals and massively parallel computing will represent a novel computing paradigm for solving complex problems.
From the application and validation point of view, we target the automatic design of deep neural networks, applied to the prediction of the electrical enerygy consumption and production.
10.1.2 Participation in other International Programs
International associated Lab MODO
Participants: Arnaud Liefooghe, Bilel Derbel.
-
Title:
Frontiers in Massive Optimization and Computational Intelligence (MODO)
-
Partner Institution(s):
Shinshu University, Japan
-
Start Date:
2017
-
Abstract:
The MODO lab global goal is to federate the French and Japanese researchers interested in tackling challenging optimization problems, where one has to deal with the dimensionality, heterogeneity and expensive objective functions, using innovative approaches at the crossroads of combinatorial optimization, fitness landscape analysis, and machine learning.
- Link:
MoU RIKEN R-CCS
Participants: Bilel Derbel, Lorenzo Canonne.
-
Title:
Memoremdum of Understanding
-
Partner Institution(s):
RIKEN Center of Computational Science, Japan
-
Start Date:
2021
-
Abstract:
This MoU aims at strengthening the research collaboration with one of the world-wide leading institute in HPC targeting the solving of computing intensive optimizaion problems on top of the japanese Fugaku supercomputer facilities (ranked second in the last TOP500).
10.2 International research visitors
10.2.1 Visits of international scientists
Tiago Carneiro
-
Status
Post-doctoral
-
Institution of origin:
University of Luxembourg
-
Country:
Luxembourg
-
Dates:
March and December 2022
-
Context of the visit:
Ultra-scale Optimization
-
Mobility program/type of mobility:
research stay
Jose Francisco Chicano Garcia
-
Status
Associate Professor
-
Institution of origin:
Univeristy of Malaga, Spain
-
Country:
Malaga, Spain
-
Dates:
July to September 2022
-
Context of the visit:
Graybox optimization for pseudo-boolean and permutation problems.
-
Mobility program/type of mobility:
research stay
Gregoire Danoy
-
Status
Research scientist
-
Institution of origin:
University of Luxembourg
-
Country:
Luxembourg
-
Dates:
Feb. 2022
-
Context of the visit:
Maetaheuristics and machine learning
-
Mobility program/type of mobility:
research stay
Rachid Ellaia
-
Status
Professor
-
Institution of origin:
EMI
-
Country:
Morocco
-
Dates:
July 2022
-
Context of the visit:
Chaotic optimization
-
Mobility program/type of mobility:
research stay
Nikolaus Frohner
-
Status
PhD student
-
Institution of origin:
Technische Universität Wien, TUW
-
Country:
Vienna, Austria
-
Dates:
September 2021 to Januray 2022
-
Context of the visit:
Parallel combinatorial optimization
-
Mobility program/type of mobility:
research stay
Byung-Woo Hong
-
Status
Associate Professor
-
Institution of origin:
Chung-Ang University, Korea
-
Country:
Seoul, Korea
-
Dates:
June to August 2022
-
Context of the visit:
Multiple gradient descent for supervised machine learning computing intensive tasks
-
Mobility program/type of mobility:
research stay
Badr Abou El Majd
-
Status
Professor
-
Institution of origin:
University Mohammed V
-
Country:
Rabat, Morocco
-
Dates:
September 2021 to September 2022
-
Context of the visit:
Optimization and machine learning
-
Mobility program/type of mobility:
research stay
Imanol Unanue
-
Status
PhD student
-
Institution of origin:
University of Basque Country, Spain
-
Country:
Saint-Sébastien, Spain
-
Dates:
May to July 2022
-
Context of the visit:
Walsh-based decomposition for analyzing combinatorial optimization problem
-
Mobility program/type of mobility:
research stay
10.2.2 Visits to international teams
Research stays abroad
- E-G. Talbi, Université de Luxembourg (Luxembourg) et EMI, Université Mohammed V de Rabat (Maroc), short visits in 2022
- N. Melab, Université de Mons (Belgique), short visits in 2022 (2 PhD co-supervision)
10.3 European initiatives
10.3.1 Other european programs/initiatives
Collaboration with European organisations
- University of Mons, Belgium, Parallel surrogate-assisted optimization, large-scale exact optimization, two joint PhDs (M. Gobert and G. Briffoteaux).
- University of Luxembourg, Hyper-Heuristic for Generating UAV Swarming Behaviours.
- University of Coimbra, Exact and heuristic multi-objective search.
- University of Manchester, UK, Multi- and many-objective optimization.
- University of Elche and University of Murcia, Spain, Matheuristics for DEA.
10.4 National initiatives
10.4.1 ANR
- ANR PEPR Numpex/Axis Exa-MA (2022-2027, Grant: Total: 6,5M€). The goal of the high-performance Digital for Exascale (Numpex) program, dedicated to both scientific research and industry, is twofold: (1) designing and developing the software building-blocks for the future exascale supercomputers, and (2) preparing the major application areas aimed at fully harnessing the capabilities of these latter. Numpex is composed of 5 axes including Exa-MA, which stands for Exascale computing: Methods and Algorithms and is organized in 7 WPs including Optimize at Exascale (WP5). The overall goal of WP5 consists in the design and implementation of exascale algorithms to efficiently and effectively solve large optimization problems. The research topics of the Bonus team are perfectly in line with the framework of WP5. E-G. Talbi and N. Melab are respectively the leader of and a contributor to this work-package.
- ANR PIA Equipex+ MesoNet (2021-2027, Grant: Total: 14,2M€, For ULille: 1,4M€). The goal of the project is to set up a distributed infrastructure dedicated to the coordination of HPC and AI in France. This inclusive and structuring project, supported by GENCI partners (MESRI, CNRS, CEA, CPU, INRIA), aims to integrate at least one mesocenter by region making them regional references and relays. The infrastructure, fully integrated with the European Open Science Cloud (EOSC) initiative, should have a significant impact on the appropriation by researchers of the national and regional public HPC and AI facilities. Coordinated by GENCI, MesoNet gathers 22 partners including the mesocenter located at ULille, for which N. Melab is the co-PI. The MesoNet infrastucture is highly important for the research activities of Bonus and many other research groups including those of Inria. In addition to the funding dedicated to hardware equipment including nation-wide federated supercomputer and storage, funding will be devoted to research engineers, one of them for ULille (4,5 years), and a PhD for Bonusas well.
- Bilateral ANR-FNR France/Luxembourg PRCI UltraBO (2023 2026, Grant: 207K€ for Bonus, PI: N. Melab) in collaboration with University of Luxembourg (Co-PI: G. Danoy). According to Top500 modern supercomputers are increasingly large (millions of cores), heterogeneous (CPU-GPU, …) and less reliable (MTBF 1h) making their programming more complex. The development of parallel algorithms for these ultra-scale supercomputers is in its infancy especially in combinatorial optimization. Our objective is to investigate the MPI+X and PGAS-based approaches for the exascale-aware design and implementation of hybrid algorithms combining exact methods (e.g. B&B) and metaheuristics (e.g. Evolutionary Algorithms) for solving challenging optimization problems. We will address in a holistic (uncommon) way three roadblocks on the road to exascale: locality-aware ultra-scalability, CPU-GPU heterogeneity and checkpointing-based fault tolerance. Our application challenge is to solve to optimality very hard benchmark instances (e.g. Flow-shop ones unsolved for 25 years). For the validation, various-scale supercomputers will be used, ranging from petascale platforms, to be used for debugging, including Jean Zay (France), ULHPC (Luxembourg), SILECS/Grid’5000 (CPER CornelIA) and MesoNet (PIA Equipex+) to exascale supercomputers, to be used for real production, including the two first supercomputers of Top500 (Frontier via our Georgia Tech partner, Fugaku via our Riken partner) as well as the two EuroHPC coming ones.
10.5 Regional initiatives
- CPER CornelIA (2021-2027, Grant: 820K€): this project aims at strengthening the research and infrastructure necessary for the development of scientific research in responsible and sustainable Artificial Intelligence at the regional (Hauts-de-France) level. The scientific leader at Lille (N. Melab) is in charge of the management of the the renewal of the hardware equipment of Grid'5000 nation-wide experimental testbed and hiring an engineer for its system & network administration and user support and development.
11 Dissemination
11.1 Promoting scientific activities
11.1.1 Scientific events: organisation
General chair, scientific chair
- E-G. Talbi (Steering committee Chair): Intl. Conf. on Optimization and Learning (OLA).
- E-G. Talbi (Steering committee): IEEE Workshop Parallel Distributed Computing and Optimization (IPDPS/PDCO).
- E-G. Talbi (Steering committee): Intl. Conf. on Metaheuristics and Nature Inspired Computing (META).
- A. Liefooghe (Steering committee): Eur. Conf. on Evolutionary Computation in Combinatorial Optimisation (EvoCOP)
- B. Derbel (special session co-chair): Advances in Decomposition based Evolutionary Multi-objecvtive Optimization (ADEMO), sepecial session at CEC/WCCI 2022, Padua, Italy (with S. Z. Martinez, K. Li, Q. Zhang).
11.1.2 Scientific events: selection
Chair of conference program committees
- B. Derbel (ECOM Track co-chair), GECCO 2022: Genetic and Evolutionary Computation Conference (Boston, USA, 2022).
- A. Liefooghe (Proceedings co-chair), EA 2022: Conference on Artificial Evolution (Exeter, UK, 2022).
Member of the conference program committees
- The ACM Genetic and Evolutionary Computation Conference (GECCO).
- The IEEE Congress on Evolutionary Computation (CEC).
- European Conference on Evolutionary Computation in Combinatorial Optimization (EvoCOP).
- Iternational Conference on Evolutionary Multi-criterion Optimization (EMO).
- European Conference on Evolutionary Computation in Combinatorial Optimisation (EvoCOP)
- Iternational conference on Parallel Problem Solving from Nature (PPSN).
- Intl. Conf. on Optimization and Learning (OLA)
11.1.3 Journal
Member of the editorial boards
- N. Melab: Associate Editor of ACM Computing Surveys (IF: 10.282), since 2019.
- A. Liefooghe: Reproducibility Board Member of ACM Transactions on Evolutionary Learning and Optimization, since 2019.
- E-G. Talbi: Guest Editor (with H. Masri) of a special issue in Annals of Operations Research on Recent advances in multi-objective optimization, 2022
Reviewer - reviewing activities
- Transactions on Evolutionary Computation (IEEE TEC, IF: 11.554), IEEE.
- ACM Transactions on Evolutionary Learning and Optimization.
- Applied Soft Computing (Elsevier, IF: 8.263)
- RAIRO Opertaions Research
- IEEE Transactions on Systems, Man and Cybernetics: Systems (IEEE, IF: 11.471)
11.1.4 Invited talks
- A. Liefooghe, Landscape analysis and feature-based automated algorithm selection for multi-objective optimization, Invited talk, Working group on Application and Theory of Multiobjective Optimization (GdR RO), Nov 2022, Paris, France.
- E-G. Talbi, How machine learning can help metaheuristics?, Keynote speaker, MIC’2022 Metaheuristics International Conference, July 2022, Syracusa, Italy.
- E-G. Talbi, An optimization vision of machine learning", Keynote speaker, EMEA Business Analytics Conference, Online, Jan 2022.
- E-G. Talbi, Machine learning at the service of optimization, Keynote speaker, 3rd Int. Conf. on Decision Aid Sciences and Applications DASA’2022, Chiang Rai, Thailand, March 2022.
11.1.5 Leadership within the scientific community
- N. Melab: Scientific leader of Grid’5000 HPC testbed at Lille, since 2004.
- E-G. Talbi: Co-president of the working group “META: Metaheuristics - Theory and applications”, GDR RO and GDR MACS.
- E-G. Talbi: Co-Chair of the IEEE Task Force on Cloud Computing within the IEEE Computational Intelligence Society.
- B. Derbel: Chair of the IEEE CIS Task Force on Decomposition-based Techniques in Evolutionary Computation (DTEC)
- A. Liefooghe: executive board member and co-secretary of the association “Artificial Evolution” (EA).
- A. Liefooghe: member of the scientific council of GdR RO, and co-animator of the MH2PPC axis (CNRS).
11.1.6 Scientific expertise
- N. Melab: Reviewer expert for FODECYT (National Research and Development Agency, Chile), 2022
11.1.7 Research administration
- N. Melab: Member of the Scientific Board for the Inria Lille - Nord Europe research center, since Feb. 2019.
- N. Melab: Member of the steering committee of “Maison de la Simulation”, since 2016.
- B. Derbel: member of the CER committee (applications to Ph.D and post-doctoral positions), Inria Lille—Nord Europe.
- B. Derbel: Member of the Scientific Board for the MADIS doctoral school at the University of Lille, since 2022.
- A. Liefooghe: elected member of the national council of universities (CNU 27), in charge of the evaluation process education staff: qualification to (Associate) Professor positions, promoting decisions, etc.
11.2 Teaching - Supervision - Juries
11.2.1 Teaching
Taught courses
- International Master lecture: N. Melab, Supercomputing, 45h ETD, M2, Université de Lille, France.
- Master lecture: N. Melab, Operations Research, 60h ETD, M1, Université de Lille, France.
- Licence: A. Liefooghe, Introduction to Programming, 36h ETD, L1, Université de Lille, France.
- Licence: A. Liefooghe, Algorithms and Programming, 36h ETD, L1, Université de Lille, France.
- Licence: A. Liefooghe, Algorithms and Data structure, 36h ETD, L2, Université de Lille, France.
- Licence: A. Liefooghe, Linear programming, 36h ETD, L3, Université de Lille, France.
- Licence: A. Liefooghe, Graphs, 18h ETD, L3, Université de Lille, France.
- Master: A. Liefooghe, Multi-criteria Decision Aid and Optimization, 60h ETD, M2, Université de Lille, France.
- Master: B. Derbel, Algorithms and Complexity, 35h, M1, Université de Lille, France
- Master: B. Derbel, Optimization and machine learning, 24h, M1, Université de Lille, France
- Licence: B. Derbel, Algorithms and data structures, 35h, L2, Université de Lille, France
- Engineering school: E-G. Talbi, Advanced optimization, 36h, Polytech'Lille, Université de Lille, France.
- Engineering school: E-G. Talbi, Data mining, 36h, Polytech'Lille, Université de Lille, France.
- Engineering school: E-G. Talbi, Operations research, 60h, Polytech'Lille, Université de Lille, France.
- Engineering school: E-G. Talbi, Graphs, 25h, Polytech'Lille, Université de Lille, France.
Teaching responsabilities
- Master leading: N. Melab, Co-head (with T. Rey) of the international Master 2 of High-performance Computing and Simulation, Université de Lille, France.
- Master leading: B. Derbel, head of the Master MIAGE, Université de Lille, France. Until July 2022.
- Responsible for Communication: A. Liefooghe, Computer Science Department, Université de Lille, France.
- Head of the international relations: E-G. Talbi, Polytech'Lille, Université de Lille, France.
- Head of the international relations: B. Derbel, Computer Science Department, Faculty of Science and Technology, Université de Lille, France.
11.2.2 Supervision
- PhD defense: Nicolas Berveglieri, Meta-models and machine learning for massive expensive optimization 36, Bilel Derbel and Arnaud Liefooghe. Defended Nov. 2022.
- PhD defense (cotutelle): Alexandre Jesus, Algorithm selection in multi-objective optimization 38, Bilel Derbel and Arnaud Liefooghe (Université de Lille), Luís Paquete (University of Coimbra, Portugal). Defended Dec. 2022.
- PhD Defense (cotutelle): Guillaume Briffoteaux, Parallel Surrogate-based Algorithms for Expensive Optimization Problems 37, Nouredine Melab (Université de Lille) and Daniel Tuyttens (Université de Mons, Belgium). Defended Oct. 2022,
- PhD Defense: Jeremy Sadet, Surrogate-based optimization in automotive brake design 40, El-Ghazali Talbi (Université de Lille), Thierry Tison (Université Polytechnique Hauts-de-France, France). Defended June 2022.
- PhD in progress (cotutelle): Maxime Gobert, Parallel multi-objective global optimization with applications to several simulation-based exlporation parameter, Oct 2018, Nouredine Melab (Université de Lille) and Daniel Tuyttens (Université de Mons, Belgium).
- PhD in progress: David Redon, Enabling Large Scale Computational Intelligence with HPC, started Oct. 2020, Bilel Derbel, and Pierre Fortin (Université de Lille)
- PhD in progress: Raphael Cosson, Design, selection and configuration of adaptive algorithms for cross-domain optimization, Nov. 2019, Bilel Derbel and Arnaud Liefooghe.
- PhD in progress: Juliette Gamot, Multidisciplinary design and analysis of aerospace concepts with a focus on internal placement optimization, Nov. 2020, El-Ghazali Talbi and Nouredine Melab, co-supervisors from ONERA: L. Brevault and M. Balesdent.
- PhD in progress: Lorenzo Canonne, Massively Parallel Gray-box and Large Scale Optimization, Oct. 2020, Bilel Derbel, Arnaud Liefooghe and Omar Abdelkafi.
- PhD in progress: Guillaume Helbecque, Productivity-aware parallel cooperative combinatorial optimization for ultra-scale supercomputers, Oct. 2021, Nouredine Melab, co-supervisor from University of Luxembourg: P. Bouvry.
- PhD in progress: Thomas Firmin, Pulse neuron networks and parameter optimization for massively parallel GPU-powered clusters, Oct. 2021, El-Ghazali Talbi, co-supervisor from Emeraude Team (CRIStAL labs): P. Boulet.
- PhD in progress: Houssem Ouertatani, Multi-objective optimization of deep neural networks for embedded applications, Oct. 2021, El-Ghazali Talbi, co-supervisor from Université Polytechnique Hauts-de-France: S. Niar.
11.2.3 Juries
- E-G. Talbi (Reviewer): PhD thesis of Mariem Bouzid, Optimisation de l’ordonnancement avec considérations environnementales, Université Technologique de Troyes, defended on Sep., 2022.
- N. Melab (Reviewer): PhD thesis of Morgan Séguéla, Stratégie de réplication de données dans des systèmes larges échelles pour prendre en compte la consommation énergétique et la dépense, Université de Toulouse, defended on May 2022.
- E-G. Talbi (Reviewer): PhD thesis of Jorg Willi Stork, Way of the fittest, University of Vrije Universiteit Amsterdam (Netherlands) and Cologne (Germany), defended on Jan. 2022.
11.3 Popularization
11.3.1 Internal or external Inria responsibilities
- N. Melab: Chargé de Mission of High Performance Computing and Simulation at Université de Lille, since 2010.
12 Scientific production
12.1 Major publications
- 1 articleA Survey on the Metaheuristics Applied to QAP for the Graphics Processing Units.Parallel Processing Letters2632016, 1--20
- 2 articleFTH-B&B: A Fault-Tolerant HierarchicalBranch and Bound for Large ScaleUnreliable Environments.IEEE Trans. Computers6392014, 2302--2315
- 3 articleParadisEO: A Framework for the Reusable Design of Parallel and Distributed Metaheuristics.J. Heuristics1032004, 357--380
- 4 articleProblem Features versus Algorithm Performance on Rugged Multiobjective Combinatorial Fitness Landscapes.Evolutionary Computation2542017
- 5 phdthesisContributions to single- and multi- objective optimization: towards distributed and autonomous massive optimization.Université de Lille2017
- 6 inproceedingsMulti-objective Local Search Based on Decomposition.Parallel Problem Solving from Nature - PPSN XIV - 14th International Conference, Edinburgh, UK, September 17-21, 2016, Proceedings2016, 431--441
- 7 articleIVM-based parallel branch-and-bound using hierarchical work stealing on multi-GPU systems.Concurrency and Computation: Practice and Experience2992017
- 8 articleLandscape-aware performance prediction for evolutionary multi-objective optimization.IEEE Transactions on Evolutionary Computation2462020, 1063-1077
- 9 articleGPU Computing for Parallel Local Search Metaheuristic Algorithms.IEEE Trans. Computers6212013, 173--185
- 10 articleDeterministic metaheuristic based on fractal decomposition for large-scale optimization.Appl. Soft Comput.612017, 468--485
12.2 Publications of the year
International journals
International peer-reviewed conferences
Conferences without proceedings
Doctoral dissertations and habilitation theses
12.3 Cited publications
- 41 inbookSpace Engineering: Modeling and Optimization with Case Studies.G.Giorgio FasanoJ. D.János D. PintérSpringer International Publishing2016, Advanced Space Vehicle Design Taking into Account Multidisciplinary Couplings and Mixed Epistemic/Aleatory Uncertainties1--48URL: http://dx.doi.org/10.1007/978-3-319-41508-6_1
- 42 inproceedingsOn the Impact of Multiobjective Scalarizing Functions.Parallel Problem Solving from Nature - PPSN XIII - 13th International Conference, Ljubljana, Slovenia, September 13-17, 2014. Proceedings2014, 548--558
- 43 inproceedingsA fine-grained message passing MOEA/D.IEEE Congress on Evolutionary Computation, CEC 2015, Sendai, Japan, May 25-28, 20152015, 1837--1844
- 44 inproceedingsParadiseo: From a Modular Framework for Evolutionary Computation to the Automated Design of Metaheuristics.GECCO 2021 - Genetic and Evolutionary Computation Conference2021 Genetic and Evolutionary Computation Conference CompanionACM SigevoLille / Virtual, FranceACMJuly 2021, 1522-1530
- 45 articleParallel surrogate-assisted global optimization with expensive functions – a survey.Structural and Multidisciplinary Optimization54(1)2016, 3--13
- 46 phdthesisDeep Gaussian Processes for the Analysis and Optimization of Complex Systems -Application to Aerospace System Design.Université de LilleJanuary 2021
- 47 articleEfficient Global Optimization of Expensive Black-Box Functions.Journal of Global Optimization13(4)1998, 455--492
- 48 inproceedingsHow to deal with mixed-variable optimization problems: An overview of algorithms and formulations.Advances in Structural and Multidisciplinary Optimization, Proc. of the 12th World Congress of Structural and Multidisciplinary Optimization (WCSMO12)Springer2018, 64--82URL: http://dx.doi.org/10.1007/978-3-319-67988-4_5
- 49 articleCRAFT: A library for easier application-level Checkpoint/Restart and Automatic Fault Tolerance.CoRRabs/1708.020302017, URL: http://arxiv.org/abs/1708.02030
- 50 articleData Structures in the Multicore Age.Communications of the ACM5432011, 76--84
- 51 articleAddressing Failures in Exascale Computing.Int. J. High Perform. Comput. Appl.282May 2014, 129--173
- 52 articleCombining metaheuristics with mathematical programming, constraint programming and machine learning.Annals OR24012016, 171--215
- 53 articleParallel Branch-and-Bound in multi-core multi-CPU multi-GPU heterogeneous environments.Future Generation Comp. Syst.562016, 95--109
- 54 articleA Decision Variable Clustering-Based Evolutionary Algorithm for Large-Scale Many-Objective Optimization.IEEE Trans. Evol. Computation2212018, 97--112