
2024Activity reportProject-TeamTHOTH
RNSR: 201622034K- Research center Inria Centre at Université Grenoble Alpes
- Team name: Learning visual models from large-scale data
- In collaboration with:Laboratoire Jean Kuntzmann (LJK)
- Domain:Perception, Cognition and Interaction
- Theme:Vision, perception and multimedia interpretation
Keywords
Computer Science and Digital Science
- A3.4. Machine learning and statistics
- A5.3. Image processing and analysis
- A5.4. Computer vision
- A5.9. Signal processing
- A6.2.6. Optimization
- A8.2. Optimization
- A9.2. Machine learning
- A9.3. Signal analysis
- A9.7. AI algorithmics
Other Research Topics and Application Domains
- B9.5.6. Data science
1 Team members, visitors, external collaborators
Research Scientists
- Julien Mairal [Team leader, Inria, Senior Researcher, en détachement du corps des Mines, HDR]
- Karteek Alahari [Inria, Senior Researcher, HDR]
- Michael Arbel [Inria, Researcher]
- Pia Bideau [UGA, Researcher, junior chair from MIAI]
- Jocelyn Chanussot [Inria, Senior Researcher, en détachement de Grenoble INP, HDR]
- Pierre Gaillard [Inria, Researcher]
- Hadrien Hendrikx [Inria, Researcher]
Post-Doctoral Fellows
- Alessia Boccalatte [UGA, Post-Doctoral Fellow]
- Ankit Jha [UGA, Post-Doctoral Fellow, until Jun 2024]
- Heeseung Kwon [UGA, Post-Doctoral Fellow, until Oct 2024]
- Giacomo Meanti [Inria, Post-Doctoral Fellow, from Feb 2024]
- Romain Menegaux [Inria, from Feb 2024]
- Scott Pesme [Inria, Post-Doctoral Fellow, from Oct 2024]
PhD Students
- Loic Arbez [GRENOBLE INP]
- Tariq Berrada Ifriqi [Meta, CIFRE]
- Theo Bodrito [Inria, joint with Willow]
- Jules Bourcier [PRELIGENS, CIFRE, until Nov 2024]
- Timothee Darcet [Meta, CIFRE]
- Fares El Khoury [Inria, from Oct 2024]
- Camila Fernadez Morales [Inria, until May 2024]
- Renaud Gaucher [ECOLE POLY PALAISEAU]
- Emmanuel Jehanno [Inria]
- Zhiqi Kang [Inria]
- Paul Liautaud [SORBONNE UNIVERSITE]
- Bianca Marin Moreno [EDF, CIFRE]
- Juliette Marrie [NAVER LABS, CIFRE]
- Ieva Petrulionyte [UGA]
- Romain Seailles [ENS PARIS, from Sep 2024, joint with Willow]
- Amogh Tiwari [UGA, from Nov 2024]
- Eloïse Touron [Inria, from Oct 2024]
- Julien Zhou [CRITEO, CIFRE]
Technical Staff
- Juliette Bertrand [Inria, Engineer, from Feb 2024]
- Julien Horvat [UGA, Engineer, from Oct 2024]
- Thomas Ryckeboer [Inria, Engineer]
- Romain Seailles [Inria, Engineer, until Aug 2024]
- Mathis Tailland [UGA, Engineer, from Oct 2024]
Interns and Apprentices
- Mohamed Bacar Abdoulandhum [AMU, Intern, from Apr 2024 until Aug 2024]
- Emelie Mougin [UGA, Intern, from Jun 2024 until Aug 2024]
- Mathis Tailland [ENSIMAG, Intern, from Mar 2024 until Aug 2024]
Administrative Assistant
- Nathalie Gillot [Inria]
Visiting Scientists
- Nassim Ait Ali Braham [DLR]
- Nicolas Cubero Torres [UNIV MALAGA, from Apr 2024 until Jun 2024]
- Khaled Eldowa [Univ Milano, from Apr 2024 until Jun 2024]
- David Jimenez Sierra [Univ of Cordoba, Spain]
- Tzu-Hsuan Lin [ACADEMIA SINICA , from Apr 2024 until Oct 2024]
External Collaborators
- Noé Peterlongo [INPG SA, from Nov 2024]
- François Postic [INRAE, from Sep 2024]
2 Overall objectives
Thoth is a computer vision and machine learning team. Our initial goal was to develop machine learning models for analyzing the massive amounts of visual data that are currently available on the web. Then, the focus of the team has become more diverse. More precisely, we share a common objective of developing machine learning models that are robust and efficient (in terms of computational cost and data requirements).
Our main research directions are the following ones:
- visual understanding from limited annotations and data: Many state-of-the-art computer vision models are typically trained on a huge corpus of fully annotated data. We want to reduce the cost by developing new algorithms for unsupervised, self-supervised, continual, or incremental learning.
- efficient deep learning models, from theory to applications: We want to invent a new generation of machine learning models (in particular deep learning) with theoretical guarantees, efficient algorithms, and a wide range of applications. We develop for instance models for images, videos, graphs, or sequences.
- statistical machine learning and optimization: we are also developing efficient machine learning methods, with a focus on stochastic optimization for processing large-scale data, and online learning.
- pluri-disciplinary collaborations: Machine learning being at the crossing of several disciplines, we have successfully conducted collaborations in scientific domains that are relatively far from our domains of expertise. These fields are producing massive amounts of data and are in dire needs of efficient tools to make predictions or interpretations. For example, we have had the chance to collaborate with many colleagues from natural language processing, robotics, neuroimaging, computational biology, genomics, astrophysics for exoplanet detections, and we are currently involved in several remote sensing and hyperspectral imaging projects thanks to Jocelyn Chanussot (hosted by Thoth in the 2019 to 2022 period, now an INRIA senior scientist on leave from Grenoble INP since september 2023 ).
3 Research program
3.1 Designing and learning structured models
The task of understanding image and video content has been interpreted in several ways over the past few decades, namely image classification, detecting objects in a scene, recognizing objects and their spatial extents in an image, recovering scene geometry. However, addressing all these problems individually provides us with a partial understanding of the scene at best, leaving much of the visual data unexplained.
One of the main goals of this research axis is to go beyond the initial attempts that consider only a subset of tasks jointly, by developing novel models for a more complete understanding of scenes to address all the component tasks. We propose to incorporate the structure in image and video data explicitly into the models. In other words, our models aim to satisfy the complex sets of constraints that exist in natural images and videos. Examples of such constraints include: (i) relations between objects, like signs for shops indicate the presence of buildings, (ii) higher-level semantic relations involving the type of scene, geographic location, and the plausible actions as a global constraint, e.g., an image taken at a swimming pool is unlikely to contain cars, (iii) relating objects occluded in some of the video frames to content in other frames, where they are more clearly visible as the camera or the object itself move, with the use of long-term trajectories and video object proposals.
This research axis will focus on two topics. The first is developing deep features for video. This involves designing rich features available in the form of long-range temporal interactions among pixels in a video sequence to learn a representation that is truly spatio-temporal in nature. The second topic is aimed at learning models that capture the relationships among several objects and regions in a single image scene, and additionally, among scenes in the case of an image collection or a video. The main scientific challenges in this topic stem from learning the structure of the probabilistic graphical model as well as the parameters of the cost functions quantifying the relationships among its entities. In the following we will present work related to all these three topics and then elaborate on our research directions.
- Deep features for vision. Deep learning models provide a rich representation of complex objects but in return have a large number of parameters. Thus, to work well on difficult tasks, a large amount of data is required. In this context, video presents several advantages: objects are observed from a large range of viewpoints, motion information allows the extraction of moving objects and parts, and objects can be differentiated by their motion patterns. We initially plan to develop deep features for videos that incorporate temporal information at multiple scales. We then plan to further exploit the rich content in video by incorporating additional cues such as minimal prior knowledge of the object of interest, with the goal of learning a representation that is more appropriate for video understanding. In other words, a representation that is learned from video data and targeted at specific applications.
- Structured models. The interactions among various elements in a scene, such as the objects and regions in it, the motion of object parts or entire objects themselves, form a key element for understanding image or video content. These rich cues define the structure of visual data and how it evolves spatio-temporally. We plan to develop a novel graphical model to exploit this structure. The main components in this graphical model are spatio-temporal regions (in the case of video or simply image regions), which can represent object parts or entire objects themselves, and the interactions among several entities. The dependencies among the scene entities are defined with a higher order or a global cost function. A higher order constraint is a generalization of the pairwise interaction term, and is a cost function involving more than two components in the scene, e.g., several regions, whereas a global constraint imposes a cost term over the entire image or vide such as a prior knowledge on the number of people expected in the scene. The constraints we plan to include generalize several existing methods, which are limited to pairwise interactions or a small restrictive set of higher-order costs. In addition to learning the parameters of these novel functions, we will focus on learning the structure of the graph itself—a challenging problem that is seldom addressed in current approaches. This provides an elegant way to go beyond state-of-the-art deep learning methods, which are limited to learning the high-level interaction among parts of an object, by learning the relationships among objects.
3.2 Learning of visual models from minimal supervision
Today's approaches to visual recognition learn models for a limited and fixed set of visual categories with fully supervised classification techniques. This paradigm has been adopted in the early 2000's, and within it enormous progress has been made over the last decade.
The scale and diversity in today's large and growing image and video collections (such as, e.g., broadcast archives, and personal image/video collections) call for a departure from the current paradigm. This is the case because to answer queries about such data, it is unfeasible to learn the models of visual content by manually and precisely annotating every relevant concept, object, scene, or action category in a representative sample of everyday conditions. For one, it will be difficult, or even impossible to decide a-priori what are the relevant categories and the proper granularity level. Moreover, the cost of such annotations would be prohibitive in most application scenarios. One of the main goals of the Thoth project-team is to develop a new framework for learning visual recognition models by actively exploring large digital image and video sources (off-line archives as well as growing on-line content), and exploiting the weak supervisory signal provided by the accompanying metadata (such as captions, keywords, tags, subtitles, or scripts) and audio signal (from which we can for example extract speech transcripts, or exploit speaker recognition models).
Textual metadata has traditionally been used to index and search for visual content. The information in metadata is, however, typically sparse (e.g., the location and overall topic of newscasts in a video archive 1) and noisy (e.g., a movie script may tell us that two persons kiss in some scene, but not when, and the kiss may occur off the screen or not have survived the final cut). For this reason, metadata search should be complemented by visual content based search, where visual recognition models are used to localize content of interest that is not mentioned in the metadata, to increase the usability and value of image/video archives. The key insight that we build on in this research axis is that while the metadata for a single image or video is too sparse and noisy to rely on for search, the metadata associated with large video and image databases collectively provide an extremely versatile source of information to learn visual recognition models. This form of “embedded annotation” is rich, diverse and abundantly available. Mining these correspondences from the web, TV and film archives, and online consumer generated content sites such as Flickr, Facebook, or YouTube, guarantees that the learned models are representative for many different situations, unlike models learned from manually collected fully supervised training data sets which are often biased.
The approach we propose to address the limitations of the fully supervised learning paradigm aligns with “Big Data” approaches developed in other areas: we rely on the orders-of-magnitude-larger training sets that have recently become available with metadata to compensate for less explicit forms of supervision. This will form a sustainable approach to learn visual recognition models for a much larger set of categories with little or no manual intervention. Reducing and ultimately removing the dependency on manual annotations will dramatically reduce the cost of learning visual recognition models. This in turn will allow such models to be used in many more applications, and enable new applications based on visual recognition beyond a fixed set of categories, such as natural language based querying for visual content. This is an ambitious goal, given the sheer volume and intrinsic variability of the every day visual content available on-line, and the lack of a universally accepted formalism for modeling it. Yet, the potential payoff is a breakthrough in visual object recognition and scene understanding capabilities.
This research axis is organized into the following three sub-tasks:
- Weakly supervised learning. For object localization we will go beyond current methods that learn one category model at a time and develop methods that learn models for different categories concurrently. This allows “explaining away” effects to be leveraged, i.e., if a certain region in an image has been identified as an instance of one category, it cannot be an instance of another category at the same time. For weakly supervised detection in video we will consider detection proposal methods. While these are effective for still images, recent approaches for the spatio-temporal domain need further improvements to be similarly effective. Furthermore, we will exploit appearance and motion information jointly over a set of videos. In the video domain we will also continue to work on learning recognition models from subtitle and script information. The basis of leveraging the script data which does not have a temporal alignment with the video is to use matches in the narrative in the script and the subtitles (which do have a temporal alignment with the video). We will go beyond simple correspondences between names and verbs relating to self-motion, and match more complex sentences related to interaction with objects and other people. To deal with the limited number of occurrences of such actions in a single movie, we will consider approaches that learn action models across a collection of movies.
- Online learning of visual models. As a larger number of visual category models is being learned, online learning methods become important, since new training data and categories will arrive over time. We will develop online learning methods that can incorporate new examples for existing category models, and learn new category models from few examples by leveraging similarity to related categories using multi-task learning methods. Here we will develop new distance-based classifiers and attribute and label embedding techniques, and explore the use of NLP techniques such as skipgram models to automatically determine between which classes transfer should occur. Moreover, NLP will be useful in the context of learning models for many categories to identify synonyms, and to determine cases of polysemy (e.g. jaguar car brand v.s. jaguar animal), and merge or refine categories accordingly. Ultimately this will result in methods that are able to learn an“encyclopedia” of visual models.
- Visual search from unstructured textual queries. We will build on recent approaches that learn recognition models on-the-fly (as the query is issued) from generic image search engines such as Google Images. While it is feasible to learn models in this manner in a matter of seconds, it is challenging to use the model to retrieve relevant content in real-time from large video archives of more than a few thousand hours. To achieve this requires feature compression techniques to store visual representations in memory, and cascaded search techniques to avoid exhaustive search. This approach, however, leaves untouched the core problem of how to associate visual material with the textual query in the first place. The second approach we will explore is based on image annotation models. In particular we will go beyond image-text retrieval methods by using recurrent neural networks such as Elman networks or long short-term memory (LSTM) networks to generate natural language sentences to describe images.
3.3 Large-scale learning and optimization
We have entered an era of massive data acquisition, leading to the revival of an old scientific utopia: it should be possible to better understand the world by automatically converting data into knowledge. It is also leading to a new economic paradigm, where data is a valuable asset and a source of activity. Therefore, developing scalable technology to make sense of massive data has become a strategic issue. Computer vision has already started to adapt to these changes.
In particular, very high-dimensional models such as deep networks are becoming highly popular and successful for visual recognition. This change is closely related to the advent of big data. On the one hand, these models involve a huge number of parameters and are rich enough to represent well complex objects such as natural images or text corpora. On the other hand, they are prone to overfitting (fitting too closely to training data without being able to generalize to new unseen data) despite regularization; to work well on difficult tasks, they require a large amount of labeled data that has been available only recently. Other cues may explain their success: the deep learning community has made significant engineering efforts, making it possible to learn in a day on a GPU large models that would have required weeks of computations on a traditional CPU, and it has accumulated enough empirical experience to find good hyper-parameters for its networks.
To learn the huge number of parameters of deep hierarchical models requires scalable optimization techniques and large amounts of data to prevent overfitting. This immediately raises two major challenges: how to learn without large amounts of labeled data, or with weakly supervised annotations? How to efficiently learn such huge-dimensional models? To answer the above challenges, we will concentrate on the design and theoretical justifications of deep architectures including our recently proposed deep kernel machines, with a focus on weakly supervised and unsupervised learning, and develop continuous and discrete optimization techniques that push the state of the art in terms of speed and scalability.
This research axis will be developed into three sub-tasks:
- Deep kernel machines for structured data. Deep kernel machines combine advantages of kernel methods and deep learning. Both approaches rely on high-dimensional models. Kernels implicitly operate in a space of possibly infinite dimension, whereas deep networks explicitly construct high-dimensional nonlinear data representations. Yet, these approaches are complementary: Kernels can be built with deep learning principles such as hierarchies and convolutions, and approximated by multilayer neural networks. Furthermore, kernels work with structured data and have well understood theoretical principles. Thus, a goal of the Thoth project-team is to design and optimize the training of such deep kernel machines.
- Large-scale parallel optimization. Deep kernel machines produce nonlinear representations of input data points. After encoding these data points, a learning task is often formulated as a large-scale convex optimization problem; for example, this is the case for linear support vector machines, logistic regression classifiers, or more generally many empirical risk minimization formulations. We intend to pursue recent efforts for making convex optimization techniques that are dedicated to machine learning more scalable. Most existing approaches address scalability issues either in model size (meaning that the function to minimize is defined on a domain of very high dimension), or in the amount of training data (typically, the objective is a large sum of elementary functions). There is thus a large room for improvements for techniques that jointly take these two criteria into account.
- Large-scale graphical models. To represent structured data, we will also investigate graphical models and their optimization. The challenge here is two-fold: designing an adequate cost function and minimizing it. While several cost functions are possible, their utility will be largely determined by the efficiency and the effectiveness of the optimization algorithms for solving them. It is a combinatorial optimization problem involving billions of variables and is NP-hard in general, requiring us to go beyond the classical approximate inference techniques. The main challenges in minimizing cost functions stem from the large number of variables to be inferred, the inherent structure of the graph induced by the interaction terms (e.g., pairwise terms), and the high-arity terms which constrain multiple entities in a graph.
4 Application domains
4.1 Visual applications
Any solution to automatically understanding images and videos on a semantic level will have an immediate impact on a wide range of applications. For example:
- Semantic-level image and video access is highly relevant for visual search on the Web, in professional archives and personal collections.
- Visual data organization is applicable to organizing family photo and video albums as well as to large-scale information retrieval.
- Visual object recognition has potential applications ranging from autonomous driving, to service robotics for assistance in day-to-day activities as well as the medical domain.
- Real-time scene understanding is relevant for human interaction through devices such as HoloLens, Oculus Rift.
4.2 Pluri-disciplinary research
Machine learning is intrinsically pluri-disciplinary. By developing large-scale machine learning models and algorithms for processing data, the Thoth team became naturally involved in pluri-disciplinary collaborations that go beyond visual modelling. During the last few years, Thoth has conducted several collaborations in other fields such as neuroimaging, bioinformatics, natural language processing, and remote sensing.
5 Highlights of the year
5.1 Awards
- Timothée Darcet and his co-authors have received an outstanding paper award at the ICLR conference for their paper “Vision Transformers need registers”. There were 5 outstanding paper awards out of more than 10K submissions. They also received an outstanding paper finalist award from the TMLR journal for their work on DINOv2 (top 5 papers out of about 1000 publications).
- Karteek Alahari was selected as an ELLIS Fellow.
- Jocelyn Chanussot was recognized a Highly Cited Researcher by Clarivate Analytics (top 0.1% of the most influential researchers in their respective fields).
- J. Chanussot received the 2024 Best Paper award from the International Journal of Image and Data Fusion.
6 New software, platforms, open data
6.1 New software
6.1.1 Cyanure
-
Name:
Cyanure: An Open-Source Toolbox for Empirical Risk Minimization
-
Functional Description:
Cyanure is an open-source C++ software package with a Python interface. The goal of Arsenic is to provide state-of-the-art solvers for learning linear models, based on stochastic variance-reduced stochastic optimization with acceleration mechanisms and Quasi-Newton principles. Arsenic can handle a large variety of loss functions (logistic, square, squared hinge, multinomial logistic) and regularization functions (l2, l1, elastic-net, fused Lasso, multi-task group Lasso). It provides a simple Python API, which is very close to that of scikit-learn, which should be extended to other languages such as R or Matlab in a near future.
-
Release Contributions:
packaging on conda and pipy + various improvements
- URL:
-
Contact:
Julien Mairal
-
Participants:
Julien Mairal, Thomas Ryckeboer
6.1.2 HySUPP
-
Keyword:
Image processing
-
Functional Description:
Toolbox for hyperspectral unmixing. This is a Python package described in the following publication https://hal.science/hal-04180307v2/document
- URL:
-
Contact:
Julien Mairal
6.1.3 t-ReX
-
Name:
Software package for improving generalization in supervised models
-
Keywords:
Generalization, Supervised models
-
Scientific Description:
We consider the problem of training a deep neural network on a given classification task, e.g., ImageNet-1K (IN1K), so that it excels at both the training task as well as at other (future) transfer tasks. These two seemingly contradictory properties impose a trade-off between improving the model’s generalization and maintaining its performance on the original task. Models trained with self-supervised learning tend to generalize better than their supervised counterparts for transfer learning, yet, they still lag behind supervised models on IN1K. In this paper, we propose a supervised learning setup that leverages the best of both worlds. We extensively analyze supervised training using multi-scale crops for data augmentation and an expendable projector head, and reveal that the design of the projector allows us to control the trade-off between performance on the training task and transferability. We further replace the last layer of class weights with class prototypes computed on the fly using a memory bank and derive two models: t-ReX that achieves a new state of the art for transfer learning and outperforms top methods such as DINO and PAWS on IN1K, and t-ReX* that matches the highly optimized RSB-A1 model on IN1K while performing better on transfer tasks. Code and pretrained models: https://europe.naverlabs.com/t-rex
-
Functional Description:
In this repository, we provide: - Several pretrained t-ReX and t-ReX* models (proposed in Sariyildiz et al., ICLR 2023) in PyTorch. - Code for training our t-ReX and t-ReX* models on the ImageNet-1K dataset in PyTorch. - Code for running transfer learning evaluations of pretrained models via linear classification over pre-extracted features on 16 downstream datasets.
- URL:
-
Contact:
Karteek Alahari
6.1.4 MLXP
-
Name:
Machine Learning eXperimentalist for Python
-
Keywords:
Reproducibility, Replication and consistency, Machine learning
-
Functional Description:
MLXP is an open-source, simple, and lightweight experiment management tool based on Python. It streamlines the experimental process with minimal practitioner overhead while ensuring a high level of reproducibility. As an open-source package, MLXP facilitates experiment launching, logging, and efficient result exploitation. Key components include automated job launching and hierarchical configuration files, logging of experiment outputs along with metadata, automated code and job version management, seamless multi-job submission to a HPC job scheduler, and intuitive result exploitation capabilities including querying results, grouping and aggregation operations.
- URL:
-
Contact:
Michael Arbel
7 New results
7.1 Visual Recognition
Object-wise Distance Estimation for Event Camera Data
Participants: Nan Cai, Pia Bideau.
Event cameras provide a natural and data efficient representation of visual information, motivating novel computational strategies towards extracting visual information. Inspired by the biological vision system, in this work 23 propose a behavior driven approach for object-wise distance estimation from event camera data. This behavior-driven method mimics how biological systems, like the human eye, stabilize their view based on object distance: distant objects require minimal compensatory rotation to stay in focus, while nearby objects demand greater adjustments to maintain alignment. This adaptive strategy leverages natural stabilization behaviors to estimate relative distances effectively. Unlike traditional vision algorithms that estimate depth across the entire image, our approach targets local depth estimation within a specific region of interest. By aligning events within a small region, we estimate the angular velocity required to stabilize the image motion. We demonstrate that, under certain assumptions, the compensatory rotational flow is inversely proportional to the object's distance. The proposed approach achieves new state-of-the-art accuracy in distance estimation on the dataset EVIMO2.

Figure
Recognizing Facial Expressions in Multi-Modal Context
Participants: Florian Blume, Runfeng Qu, Pia Bideau, Martin Maier, Rasha Abdel Rahman, Olaf Hellwich.
Facial expression perception in humans inherently relies on prior knowledge and contextual cues, contributing to efficient and flexible processing. For instance, multi-modal emotional context (such as voice color, affective text, body pose, etc.) can prompt people to perceive emotional expressions in objectively neutral faces. Drawing inspiration from this, we introduce in our work 20 a novel approach for facial expression classification that goes beyond simple classification tasks. Our model accurately classifies a perceived face and synthesizes the corresponding mental representation perceived by a human when observing a face in context. With this, our model offers visual insights into its internal decision-making process. We achieve this by learning two independent representations of content and context using a VAE-GAN architecture. Subsequently, we propose a novel attention mechanism for context-dependent feature adaptation. The adapted representation is used for classification and to generate a context-augmented expression. We evaluate synthesized expressions in a human study, showing that our model effectively produces approximations of human mental representations. We achieve state-of-the-art classification accuracies.
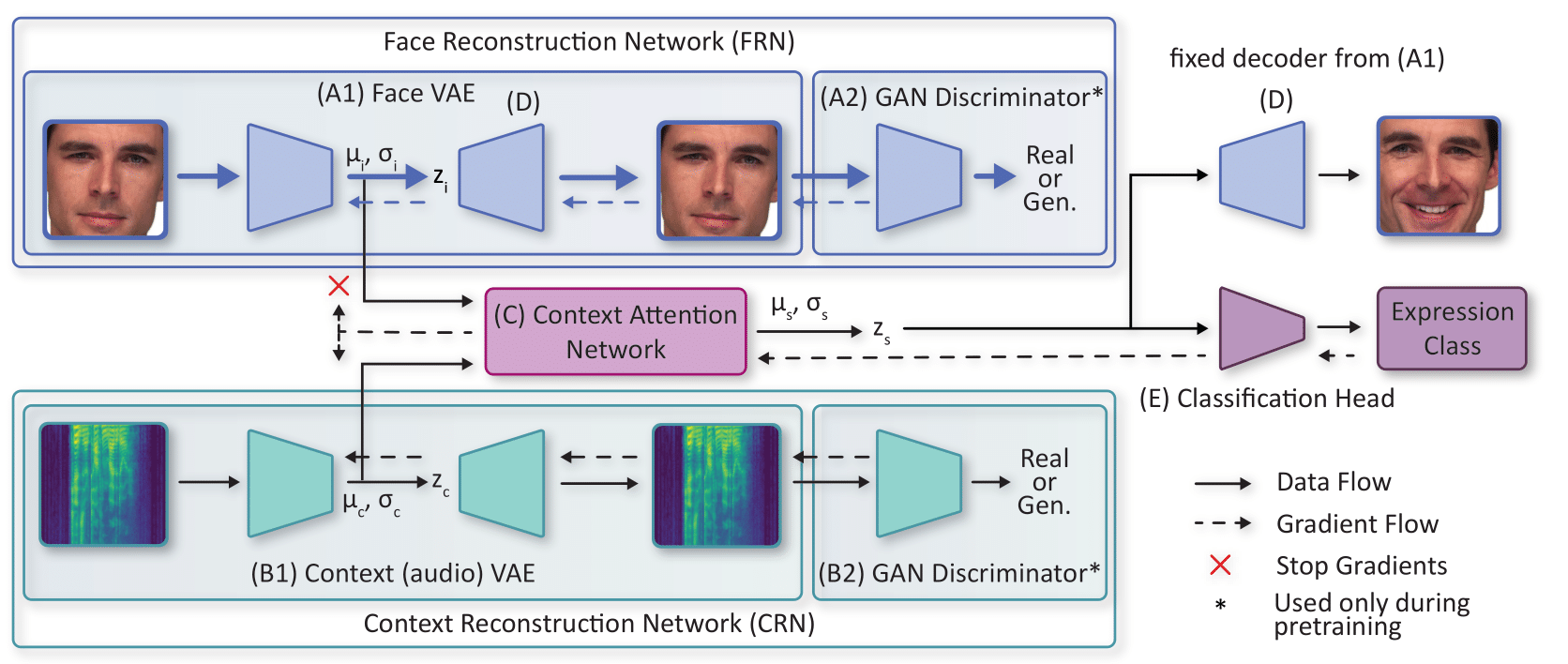
Figure
Participants: Marah Halawa, Florian Blume, Pia Bideau, Martin Maier, Rasha Abdel Rahman, Olaf Hellwich.
Human communication is multi-modal; e.g., face-to-face interaction involves auditory signals (speech) and visual signals (face movements and hand gestures). Hence, it is essential to exploit multiple modalities when designing machine learning-based facial expression recognition systems. In addition, given the ever-growing quantities of video data that capture human facial expressions, such systems should utilize raw unlabeled videos without requiring expensive annotations. Therefore, in this work 25, we employ a multitask multi-modal self-supervised learning method for facial expression recognition from in-the-wild video data. Our model combines three self-supervised objective functions: First, a multi-modal contrastive loss, that pulls diverse data modalities of the same video together in the representation space. Second, a multi-modal clustering loss that preserves the semantic structure of input data in the representation space. Finally, a multi-modal data reconstruction loss. We conduct a comprehensive study on this multimodal multi-task self-supervised learning method on three facial expression recognition benchmarks. To that end, we examine the performance of learning through different combinations of self-supervised tasks on the facial expression recognition downstream task. Our model ConCluGen outperforms several multi-modal self-supervised and fully supervised baselines on the CMU-MOSEI dataset. Our results generally show that multi-modal self-supervision tasks offer large performance gains for challenging tasks such as facial expression recognition, while also reducing the amount of manual annotations required.
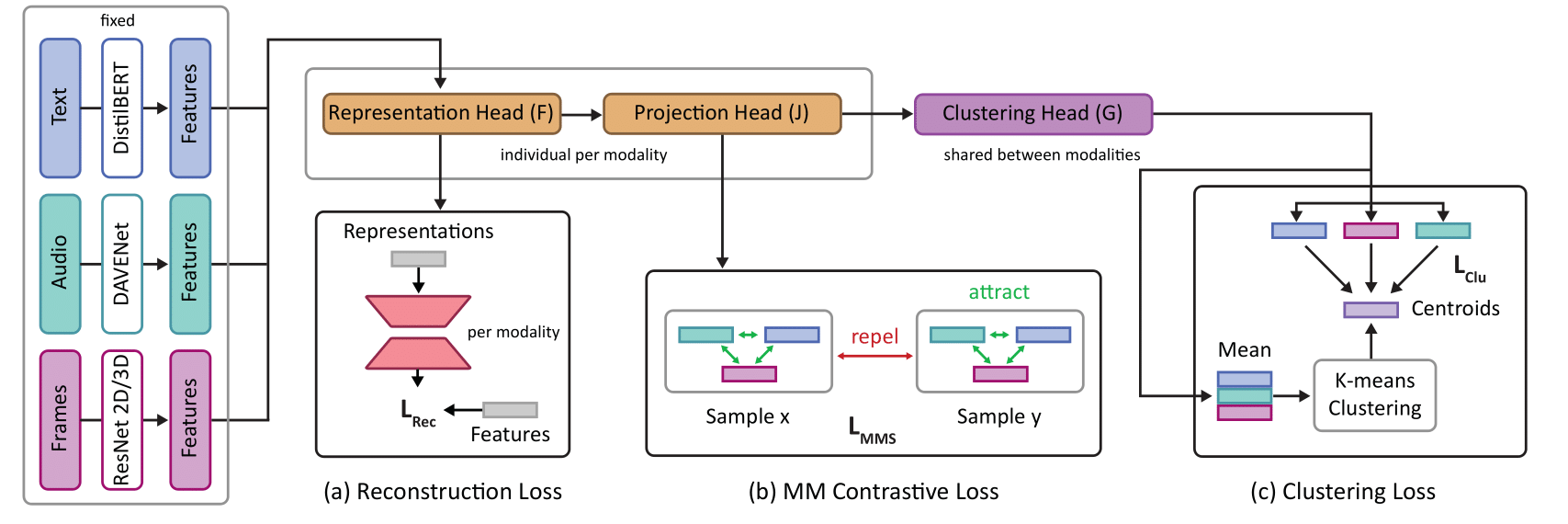
Figure
Vision Transformers Need Registers
Participants: Timothee Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski.
Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm tokens appearing during inference primarily in low-informative background areas of images, that are repurposed for internal computations. In 24, we propose a simple yet effective solution based on providing additional tokens to the input sequence of the Vision Transformer to fill that role. We show that this solution fixes that problem entirely for both supervised and self-supervised models (see Fig 4), sets a new state of the art for self-supervised visual models on dense visual prediction tasks, enables object discovery methods with larger models, and most importantly leads to smoother feature maps and attention maps for downstream visual processing.
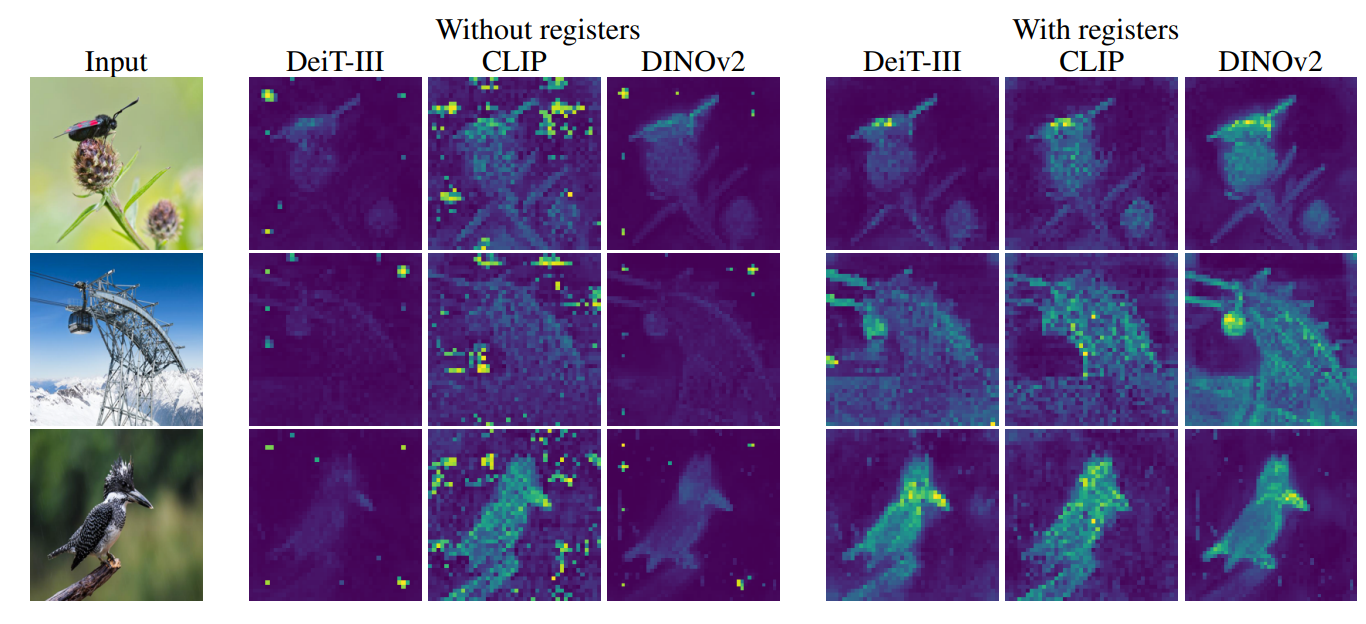
Figure
LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes.
Participants: Juliette Marrie, Romain Menegaux, Michael Arbel, Diane Larlus, Julien Mairal.
In 43, we address the problem of extending the capabilities of vision foundation models such as DINO, SAM, and CLIP, to 3D tasks. Specifically, we introduce a novel method to uplift 2D image features into 3D Gaussian Splatting scenes. Unlike traditional approaches that rely on minimizing a reconstruction loss, our method employs a simpler and more efficient feature aggregation technique, augmented by a graph diffusion mechanism. Graph diffusion enriches features from a given model, such as CLIP, by leveraging 3D geometry and pairwise similarities induced by another strong model such as DINOv2. Our approach achieves performance comparable to the state of the art on multiple downstream tasks while delivering significant speed-ups. Notably, we obtain competitive segmentation results using generic DINOv2 features, despite DINOv2 not being trained on millions of annotated segmentation masks like SAM. When applied to CLIP features, our method demonstrates strong performance in open-vocabulary object detection tasks, highlighting the versatility of our approach.
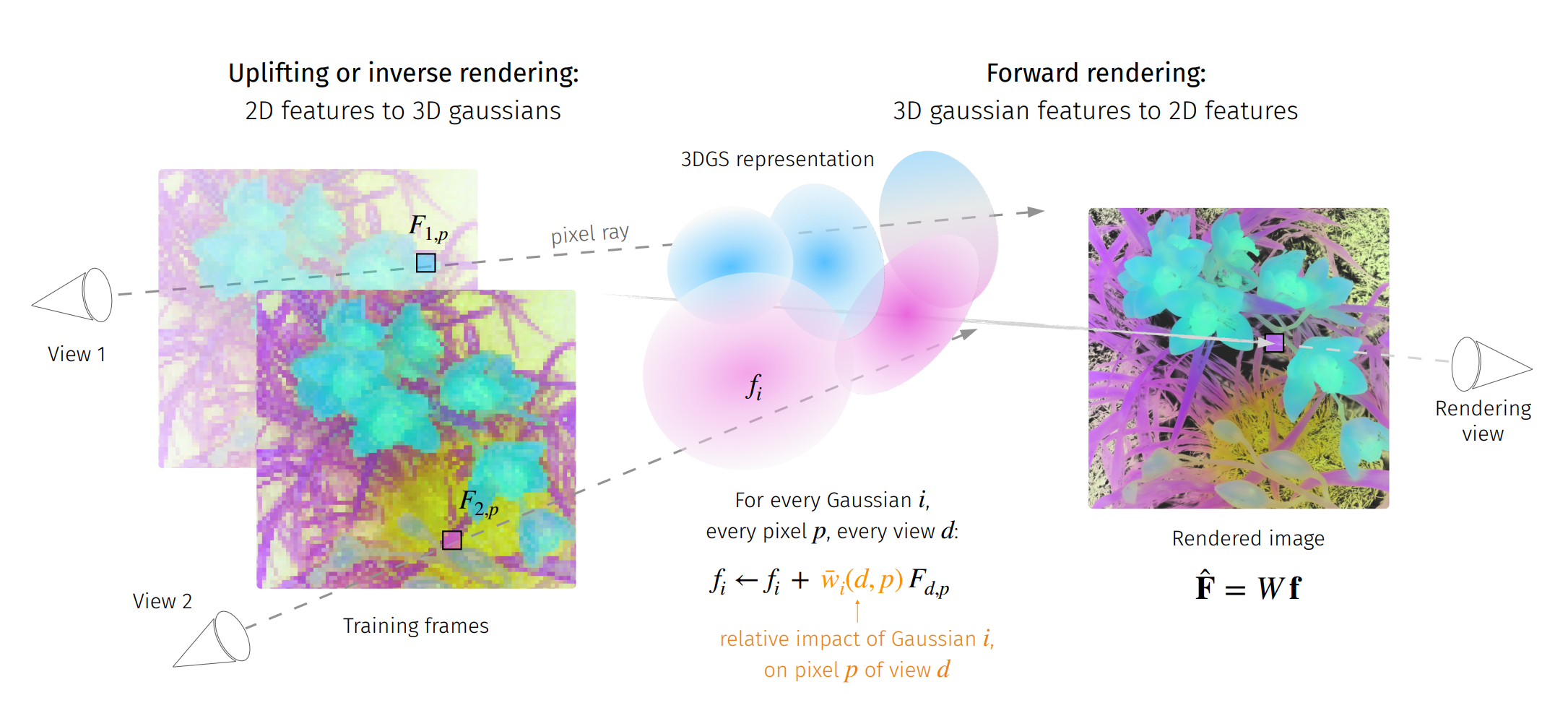
Figure
On Good Practices for Task-Specific Distillation of Large Pretrained Visual Models
Participants: Juliette Marrie, Michael Arbel, Julien Mairal, Diane Larlus.
Large pretrained visual models exhibit remarkable generalization across diverse recognition tasks. Yet, real-world applications often demand compact models tailored to specific problems. Variants of knowledge distillation have been devised for such a purpose, enabling task-specific compact models (the students) to learn from a generic large pretrained one (the teacher). In 9, we show that the excellent robustness and versatility of recent pretrained models challenge common practices established in the literature, calling for a new set of optimal guidelines for task-specific distillation. To address the lack of samples in downstream tasks, we also show that a variant of Mixup based on stable diffusion complements standard data augmentation. This strategy eliminates the need for engineered text prompts and improves distillation of generic models into streamlined specialized networks.
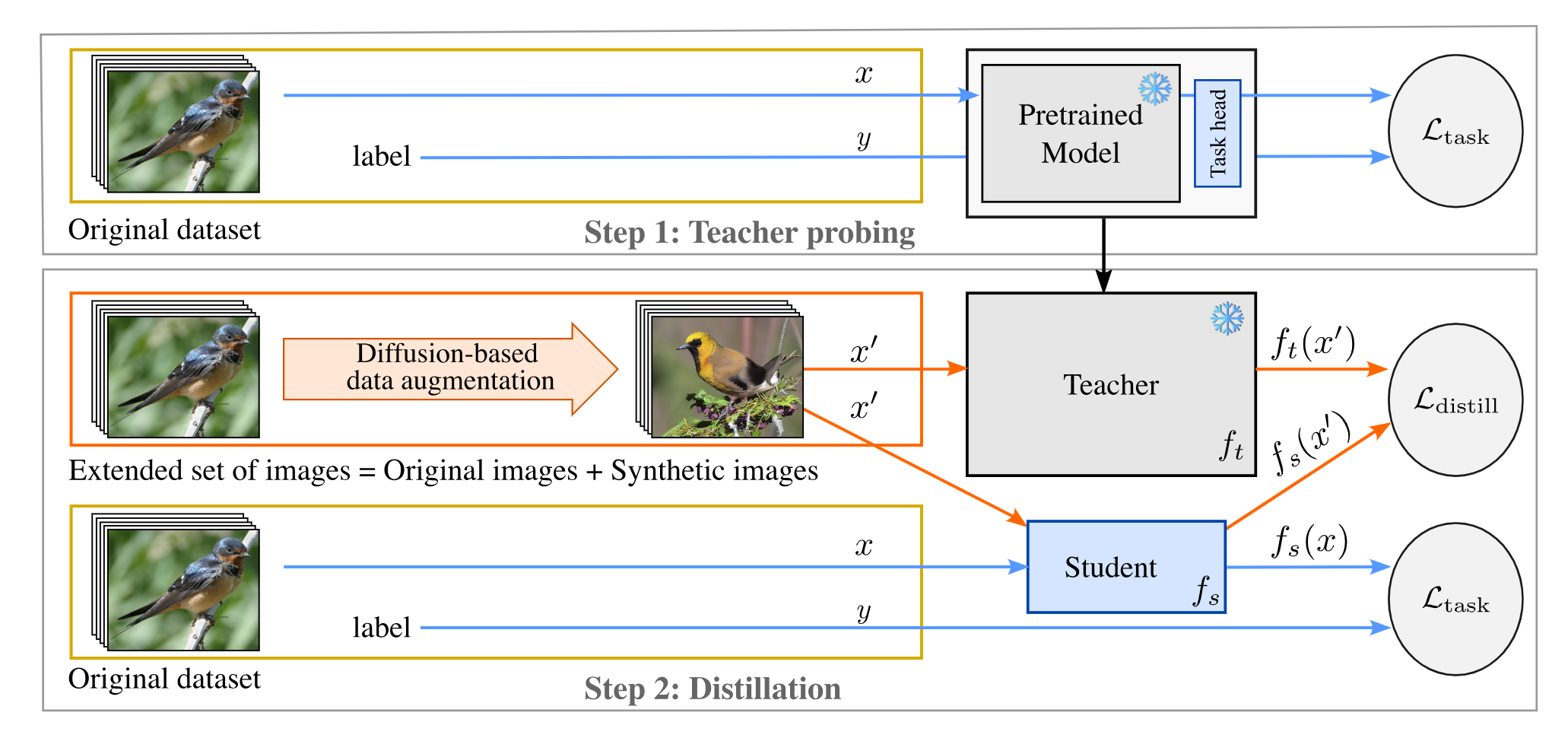
Figure
DINOv2: Learning Robust Visual Features without Supervision
Participants: Maxime Oquab, Timothee Darcet, Julien Mairal, Piotr Bojanowski, Armand Joulin.
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work 11 shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP on most of the benchmarks at image and pixel levels.
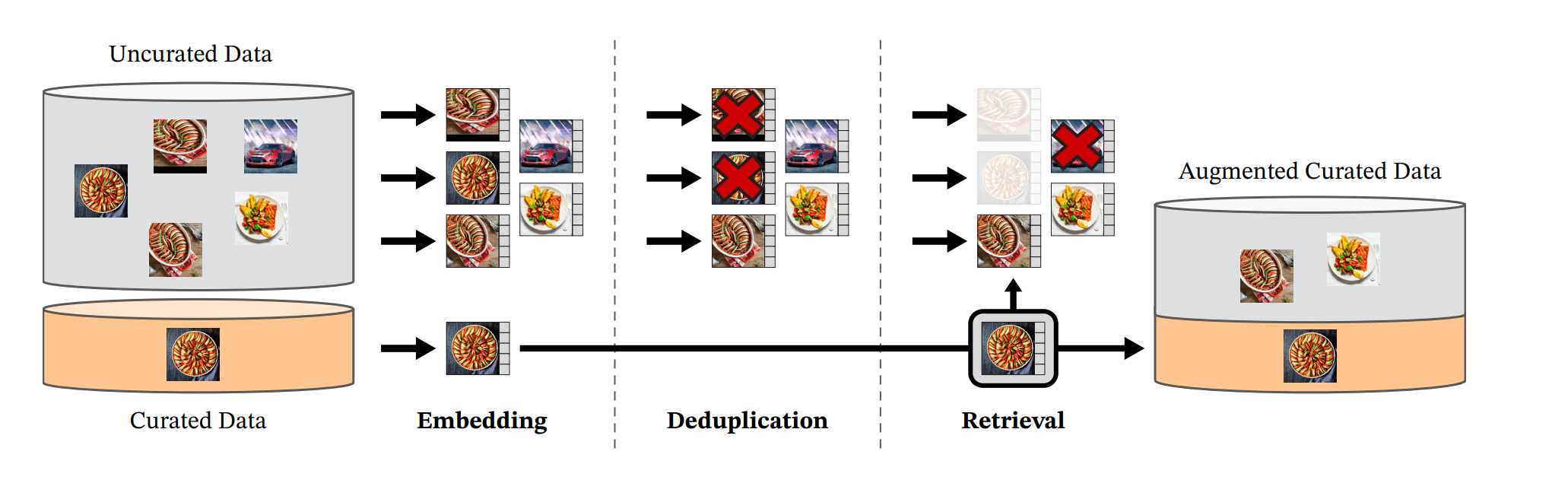
Figure
Learning Representations of Satellite Images From Metadata Supervision
Participants: Jules Bourcier, Gohar Dashyan, Karteek Alahari, Jocelyn Chanussot.
Self-supervised learning is increasingly applied to Earth observation problems that leverage satellite and other remotely sensed data. Within satellite imagery, metadata such as time and location often hold significant semantic information that improves scene understanding. In 21, we introduce Satellite Metadata-Image Pretraining (SatMIP) (see Figure 8), a new approach for harnessing metadata in the pretraining phase through a flexible and unified multimodal learning objective. SatMIP represents metadata as textual captions and aligns images with metadata in a shared embedding space by solving a metadata-image contrastive task. Our model learns a non-trivial image representation that can effectively handle recognition tasks. We further enhance this model by combining image self-supervision and metadata supervision, introducing SatMIPS. As a result,SatMIPS improves over its image-image pretraining baseline, SimCLR, and accelerates convergence. Comparison against four recent contrastive and masked autoencoding-based methods for remote sensing also highlight the efficacy of our approach. Furthermore, our framework enables multimodal classification with metadata to improve the performance of visual features, and yields more robust hierarchical pretraining. Code and pretrained models will be made available at: Satmip software.
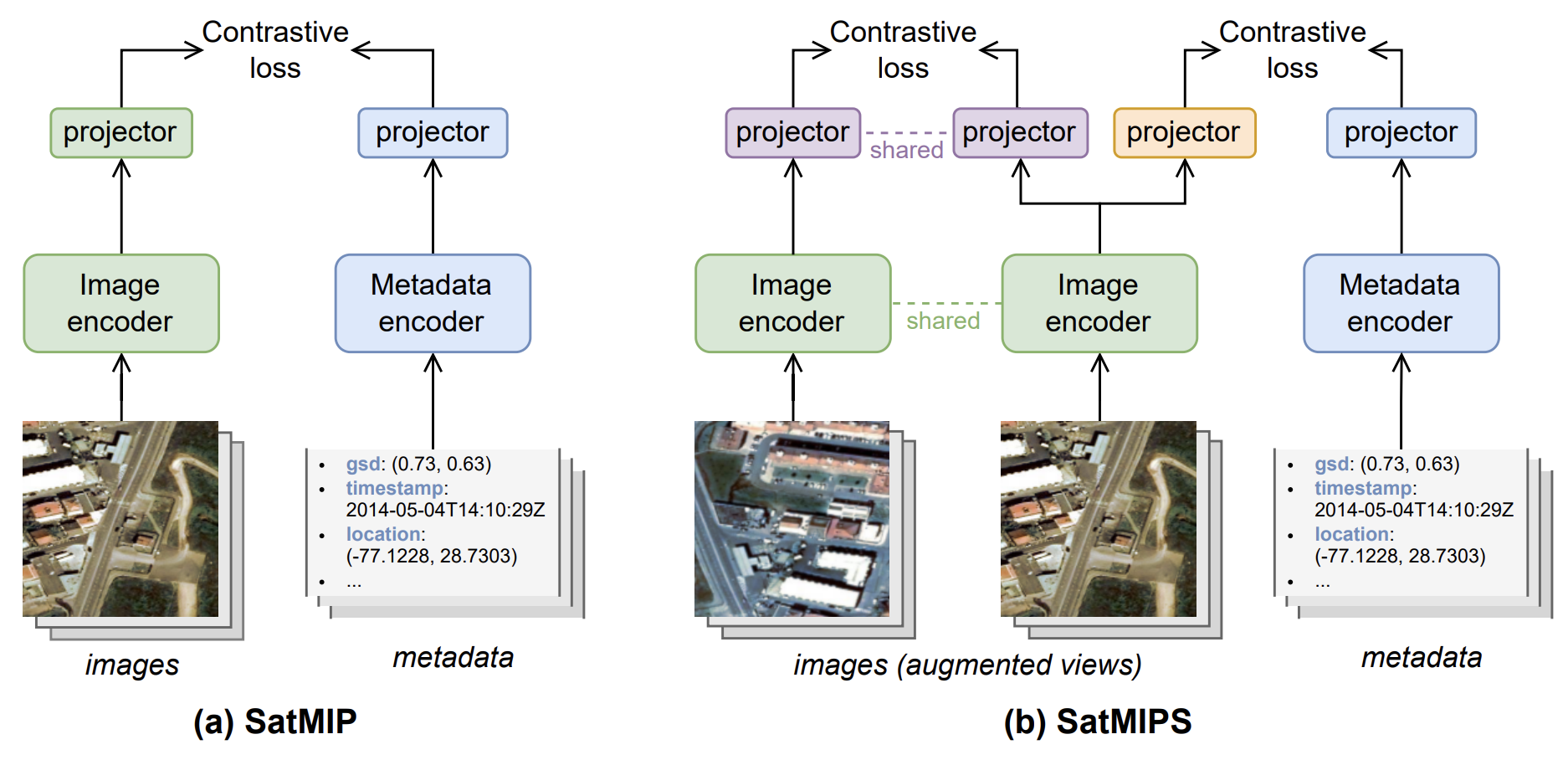
Figure
On Improved Conditioning Mechanisms and Pre-training Strategies for Diffusion Models
Participants: Tariq Berrada Ifriqi, Pietro Astolfi, Melissa Hall, Reyhane Askari-Hemmat, Yohann Benchetrit, Marton Havasi, Matthew Muckley, Karteek Alahari, Adriana Romero-Soriano, Jakob Verbeek, Michal Drozdzal.
Large-scale training of latent diffusion models (LDMs) has enabled unprecedented quality in image generation. However, the key components of the best performing LDM training recipes are oftentimes not available to the research community, preventing apple-to-apple comparisons and hindering the validation of progress in the field. In 27, we perform an in-depth study of LDM training recipes focusing on the performance of models and their training efficiency. To ensure apple-to-apple comparisons, we re-implement five previously published models with their corresponding recipes. Through our study, we explore the effects of (i) the mechanisms used to condition the generative model on semantic information (e.g., text prompt) and control metadata (e.g., crop size, random flip flag, etc.) on the model performance, and (ii) the transfer of the representations learned on smaller and lower-resolution datasets to larger ones on the training efficiency and model performance. We then propose a novel conditioning mechanism that disentangles semantic and control metadata conditionings and sets a new state-of-the-art in class-conditional generation on the ImageNet-1k dataset – with FID improvements of 7% on 256 and 8% on 512 resolutions – as well as text-to-image generation on the CC12M dataset – with FID improvements of 8% on 256 and 23% on 512 resolution (see examples in Figure 9).

Figure
Unlocking Pre-trained Image Backbones for Semantic Image Synthesis
Participants: Tariq Berrada, Jakob Verbeek, Camille Couprie, Karteek Alahari.
Semantic image synthesis, i.e., generating images from user-provided semantic label maps, is an important conditional image generation task as it allows to control both the content as well as the spatial layout of generated images. Although diffusion models have pushed the state of the art in generative image modeling, the iterative nature of their inference process makes them computationally demanding. Other approaches such as GANs are more efficient as they only need a single feed-forward pass for generation, but the image quality tends to suffer on large and diverse datasets. In this work 19, we propose a new class of GAN discriminators for semantic image synthesis that generates highly realistic images by exploiting feature backbone networks pre-trained for tasks such as image classification. We also introduce a new generator architecture with better context modeling and using cross-attention to inject noise into latent variables, leading to more diverse generated images. Our model, which we dub DP-SIMS, achieves state-of-the-art results (see examples in Figure 10) in terms of image quality and consistency with the input label maps on ADE-20K, COCO-Stuff, and Cityscapes, surpassing recent diffusion models while requiring two orders of magnitude less compute for inference.

Figure
Guided Distillation for Semi-Supervised Instance Segmentation
Participants: Tariq Berrada, Camille Couprie, Karteek Alahari, Jakob Verbeek.
Although instance segmentation methods have improved considerably, the dominant paradigm is to rely on fully-annotated training images, which are tedious to obtain. To alleviate this reliance, and boost results, semi-supervised approaches leverage unlabeled data as an additional training signal that limits overfitting to the labeled samples. In this context, we present novel design choices 18 to significantly improve teacher-student distillation models. In particular, we (i) improve the distillation approach by introducing a novel “guided burn-in” stage, and (ii) evaluate different instance segmentation architectures, as well as backbone networks and pre-training strategies. Contrary to previous work which uses only supervised data for the burn-in period of the student model, we also use guidance of the teacher model to exploit unlabeled data in the burn-in period. Our improved distillation approach leads to substantial improvements over previous state-of-the-art results. For example, on the Cityscapes dataset we improve mask-AP from 23.7 to 33.9 when using labels for 10% of images, and on the COCO dataset we improve mask-AP from 18.3 to 34.1 when using labels for only 1% of the training data (see Figure 11).
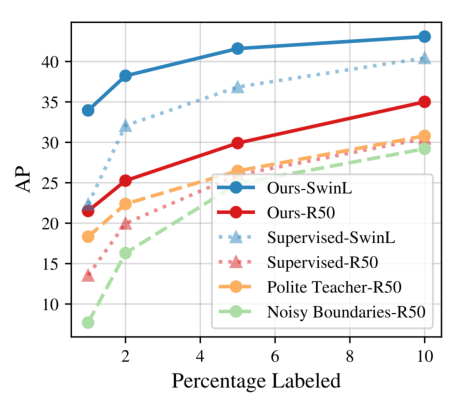
Figure
7.2 Statistical Machine Learning
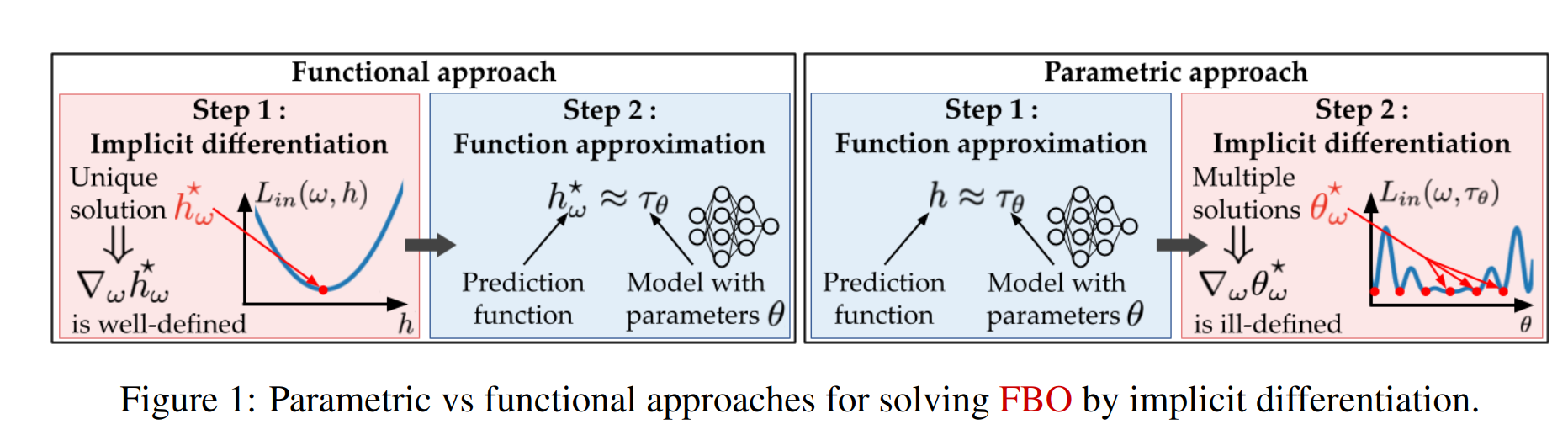
Functional Bilevel Optimization for Machine Learning
Participants: Ieva Petrulionyte, Julien Mairal, Michael Arbel.
In 30, we introduce a new functional point of view on bilevel optimization problems for machine learning, where the inner objective is minimized over a function space. These types of problems are most often solved by using methods developed in the parametric setting, where the inner objective is strongly convex with respect to the parameters of the prediction function. The functional point of view does not rely on this assumption and notably allows using over-parameterized neural networks as the inner prediction function. We propose scalable and efficient algorithms for the functional bilevel optimization problem and illustrate the benefits of our approach on instrumental regression and reinforcement learning tasks.
Figure
From CNNs to Shift-Invariant Twin Wavelet Models
Participants: Hubert Leterme, Kévin Polisano, Valérie Perrier, Karteek Alahari.
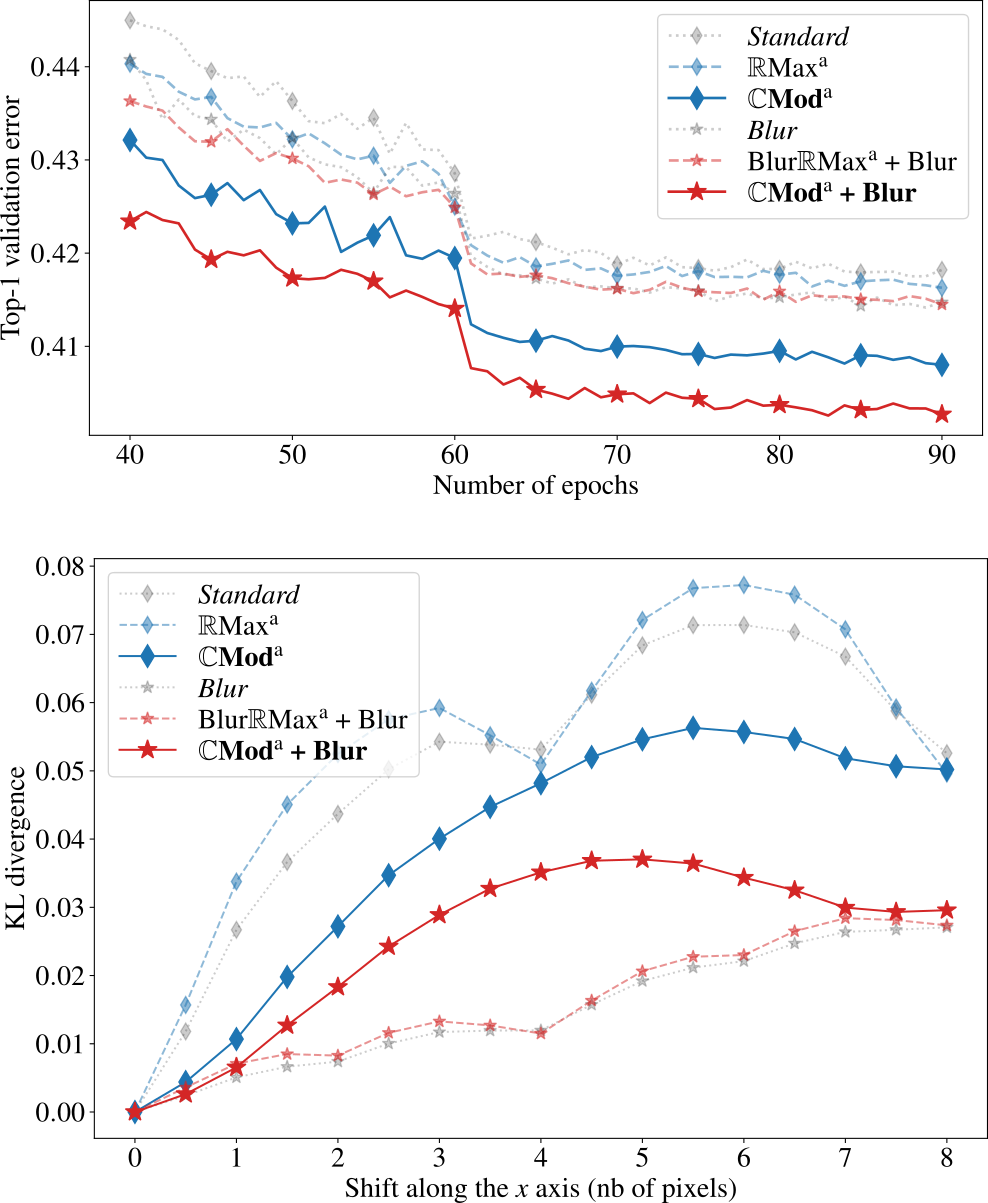
In this paper 28, we propose a novel antialiasing method to increase shift invariance in convolutional neural networks (CNNs). More precisely, we replace the conventional combination “real-valued convolutions + max pooling” (Max) by “complex-valued convolutions + modulus” (Mod), which produce stable feature representations for band-pass filters with well-defined orientations. In an earlier work, we proved that, for such filters, the two operators yield similar outputs. Therefore, Mod can be viewed as a stable alternative to Max. To separate band-pass filters from other freely-trained kernels, in this paper, we designed a “twin” architecture based on the dual-tree complex wavelet packet transform (DT-WPT), which generates similar outputs as standard CNNs with fewer trainable parameters. In addition to improving stability to small shifts, our experiments on AlexNet and ResNet showed increased prediction accuracy on natural image datasets such as ImageNet and CIFAR10. Furthermore, our approach outperformed recent antialiasing methods based on low-pass filtering by preserving high-frequency information, while reducing memory usage. Figure 13 compares the accuracy and shift invariance of the various methods.
Figure
Towards Efficient and Optimal Covariance-Adaptive Algorithms for Combinatorial Semi-Bandits
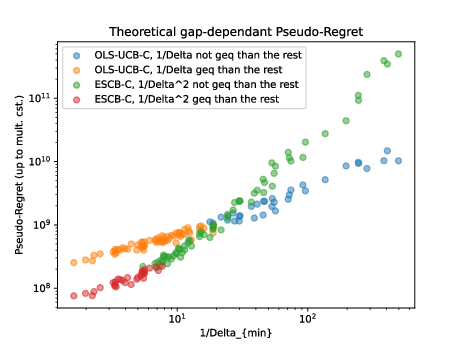
Participants: Julien Zhou, Pierre Gaillard, Thibaud Rahier, Julyan Arbel.
In 44, we address the problem of stochastic combinatorial semi-bandits, where a player selects among actions from the power set of a set containing base items. Adaptivity to the problem's structure is essential in order to obtain optimal regret upper bounds. As estimating the coefficients of a covariance matrix can be manageable in practice, leveraging them should improve the regret. We design two “optimistic” covariance-adaptive algorithms relying on online estimations of the covariance structure, with improved gap-free regret. Our second algorithm is the first sampling-based algorithm satisfying a gap-free regret (up to poly-logs).
Regret
Logarithmic Regret for Unconstrained Submodular Maximization Stochastic Bandit
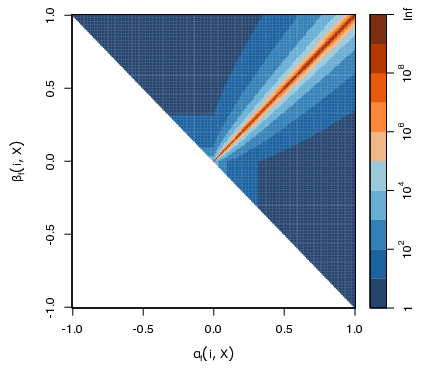
Participants: Julien Zhou, Pierre Gaillard, Thibaud Rahier, Julyan Arbel.
In 32, we address the online unconstrained submodular maximization problem (Online USM), in a setting with stochastic bandit feedback. In this framework, a decision-maker receives noisy rewards from a nonmonotone submodular function, taking values in a known bounded interval. This paper proposes Double-Greedy - Explore-then-Commit (DG-ETC), adapting the Double-Greedy approach from the offline and online full-information settings. DG-ETC satisfies a problem dependent upper bound for the -approximate pseudo-regret, as well as a problem-free one at the same time, outperforming existing approaches. To that end, we introduce a notion of hardness for submodular functions, characterizing how difficult it is to maximize them with this type of strategy.
Hardness
MetaCURL: Non-stationary Concave Utility Reinforcement Learning
Participants: Bianca Marin Moreno, Pierre Gaillard, Margaux Brégère, Nadia Oudjane.
In 42, we explore online learning in episodic Markov decision processes on non-stationary environments (changing losses and probability transitions). Our focus is on the Concave Utility Reinforcement Learning problem (CURL), an extension of classical RL for handling convex performance criteria in state-action distributions induced by agent policies. While various machine learning problems can be written as CURL, its non-linearity invalidates traditional Bellman equations. Despite recent solutions to classical CURL, none address non-stationary MDPs. This paper introduces MetaCURL, the first CURL algorithm for non-stationary MDPs. It employs a meta-algorithm running multiple black-box algorithms instances over different intervals, aggregating outputs via a sleeping expert framework. The key hurdle is partial information due to MDP uncertainty. Under partial information on the probability transitions (uncertainty and non-stationarity coming only from external noise, independent of agent state-action pairs), the algorithm achieves optimal dynamic regret without prior knowledge of MDP changes. Unlike approaches for RL, MetaCURL handles adversarial losses. We believe our approach for managing non-stationarity with experts can be of interest to the RL community.
Adaptive Boosting for Online Nonparametric Regression
Participants: Paul Liautaud, Pierre Gaillard, Olivier Wintenberger.
In 41, we study online gradient boosting for nonparametric regression with arbitrary deterministic sequences and general convex losses. The procedure relies on sequentially training generic weak learners using the gradient step of the strong learner. Based on chaining-trees, we employ parameter-free online algorithms on specific weak learners to achieve, after iterations, optimal regret , across Hölder function classes. Moreover, by boosting chaining-trees as node experts within a core tree, our proposed algorithm competes effectively against any pruned tree prediction. Improved regret performances are achieved over oracle pruning, which is aware of the Hölder profile. As a result, we obtain the first computationally efficient algorithm with locally adaptive optimal rates for online regression in an adversarial setting.
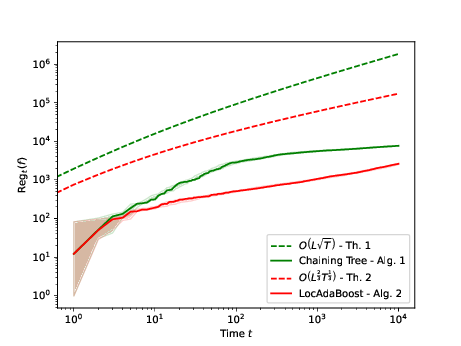
Regret
Online Learning Approach for Survival Analysis
Participants: Camila Fernandez, Pierre Gaillard, Olivier Wintenberger.
In 38, we introduce an online mathematical framework for survival analysis, allowing real time adaptation to dynamic environments and censored data. This framework enables the estimation of event time distributions through an optimal second order online convex optimization algorithm—Online Newton Step (ONS). This approach, previously unexplored, presents substantial advantages, including explicit algorithms with non-asymptotic convergence guarantees. Moreover, we analyze the selection of ONS hyperparameters, which depends on the exp-concavity property and has a significant influence on the regret bound. We introduce an adaptive aggregation method that ensures robustness in hyperparameter selection while maintaining fast regret bounds. These findings can extend beyond the survival analysis field, and are relevant for any case characterized by poor exp-concavity and unstable ONS. Additionally, we propose a stochastic approach for ONS that guarantees logarithmic regret in the case of an exponential hazard model. Next, these assertions are illustrated by simulation experiments, followed by an application to a real dataset. 37 also provides some experimental comparaison of existing algorithms for survival analysis.
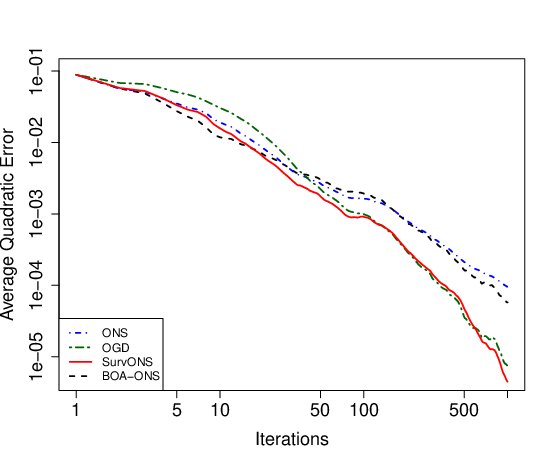
Error
Structured Prediction in Online Learning
Participants: Pierre Boudard, Pierre Gaillard, Alessandro Rudi.
In 35, we study a theoretical and algorithmic framework for structured prediction in the online learning setting. The problem of structured prediction, i.e. estimating function where the output space lacks a vectorial structure, is well studied in the literature of supervised statistical learning. We show that our algorithm is a generalisation of optimal algorithms from the supervised learning setting, and achieves the same excess risk upper bound also when data are not i.i.d. Moreover, we consider a second algorithm designed especially for non-stationary data distributions, including adversarial data. We bound its stochastic regret in function of the variation of the data distributions.
7.3 Pluri-disciplinary Research
deep PACO: Combining statistical models with deep learning for exoplanet detection and characterization in direct imaging at high contrast
Participants: Olivier Flasseur, Theo Bodrito, Julien Mairal, Jean Ponce, Maud Langlois, Anne-Marie Lagrange.
Direct imaging is an active research topic in astronomy for the detection and the characterization of young sub-stellar objects. The very high contrast between the host star and its companions makes the observations particularly challenging. In this context, post-processing methods combining several images recorded with the pupil tracking mode of telescope are needed. In previous works, we have presented a data-driven algorithm, PACO, capturing locally the spatial correlations of the data with a multi-variate Gaussian model. PACO delivers better detection sensitivity and confidence than the standard post-processing methods of the field. However, there is room for improvement due to the approximate fidelity of the PACO statistical model to the time evolving observations. In 5 we propose to combine the statistical model of PACO with supervised deep learning. The data are first pre-processed with the PACO framework to improve the stationarity and the contrast. A convolutional neural network (CNN) is then trained in a supervised fashion to detect the residual signature of synthetic sources. Finally, the trained network delivers a detection map. The photometry of detected sources is estimated by a second CNN. We apply the proposed approach to several datasets from the VLT/SPHERE instrument. Our results show that its detection stage performs significantly better than baseline methods (cADI, PCA), and leads to a contrast improvement up to half a magnitude compared to PACO. The characterization stage of the proposed method performs on average on par with or better than the comparative algorithms (PCA, PACO) for angular separation above 0.5. This approach is illustrated in Figure 18.
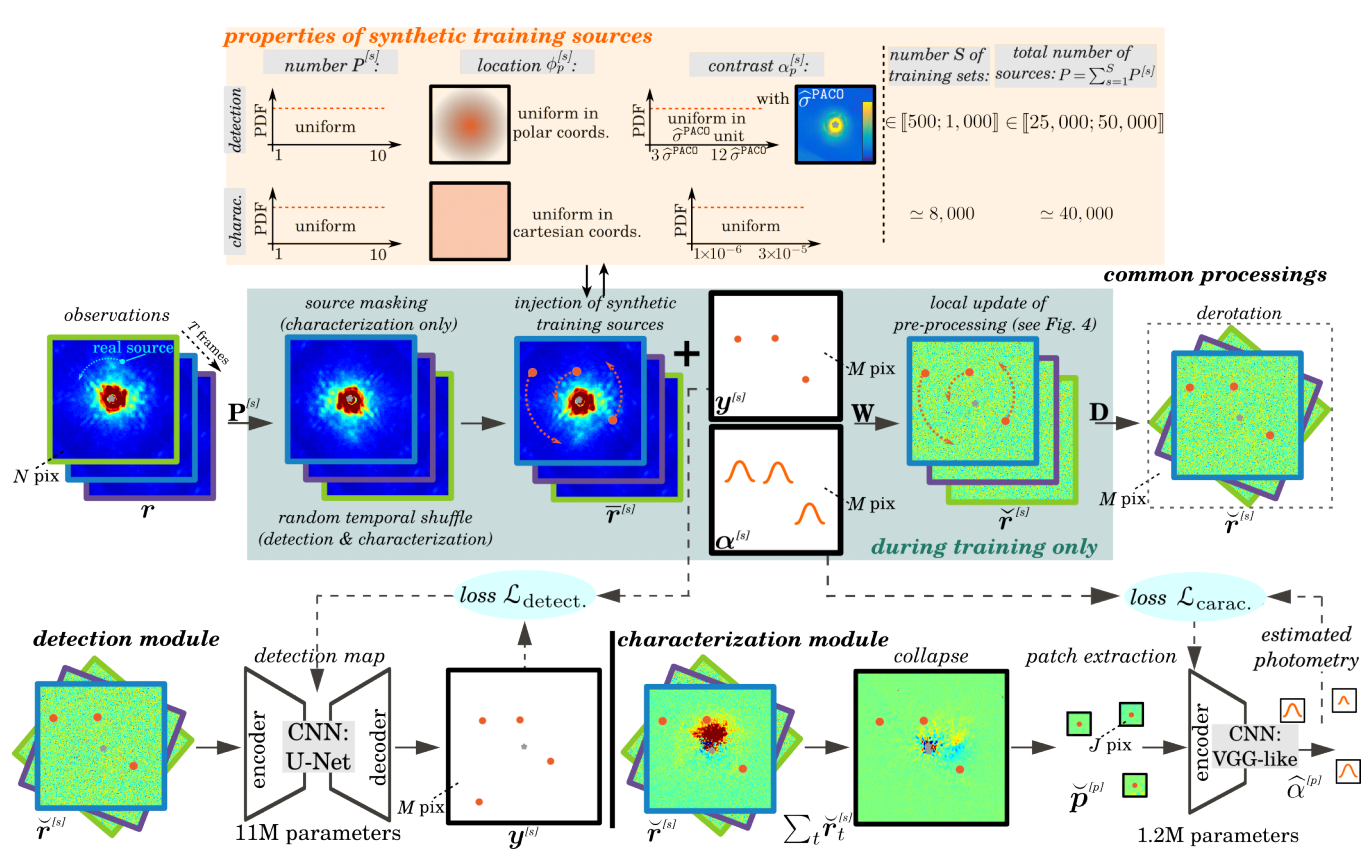
Figure
MODEL&CO: Exoplanet detection in angular differential imaging by learning across multiple observations
Participants: Theo Bodrito, Olivier Flasseur, Julien Mairal, Jean Ponce, Maud Langlois, Anne-Marie Lagrange.
Direct imaging of exoplanets is particularly challenging due to the high contrast between the planet and the star luminosities, and their small angular separation. In addition to tailored instrumental facilities implementing adaptive optics and coronagraphy, post-processing methods combining several images recorded in pupil tracking mode are needed to attenuate the nuisances corrupting the signals of interest. Most of these post-processing methods build a model of the nuisances from the target observations themselves, resulting in strongly limited detection sensitivity at short angular separations due to the lack of angular diversity. To address this issue, we propose in 1 to build the nuisance model from an archive of multiple observations by leveraging supervised deep learning techniques. The proposed approach casts the detection problem as a reconstruction task and captures the structure of the nuisance from two complementary representations of the data. Unlike methods inspired by reference differential imaging, the proposed model is highly non-linear and does not resort to explicit image-to-image similarity measurements and subtractions. The proposed approach also encompasses statistical modelling of learnable spatial features. The latter is beneficial to improve both the detection sensitivity and the robustness against heterogeneous data. We apply the proposed algorithm to several data sets from the VLT/SPHERE instrument, and demonstrate a superior precision-recall trade-off compared to the PACO algorithm. Interestingly, the gain is especially important when the diversity induced by ADI is the most limited, thus supporting the ability of the proposed approach to learn information across multiple observations.
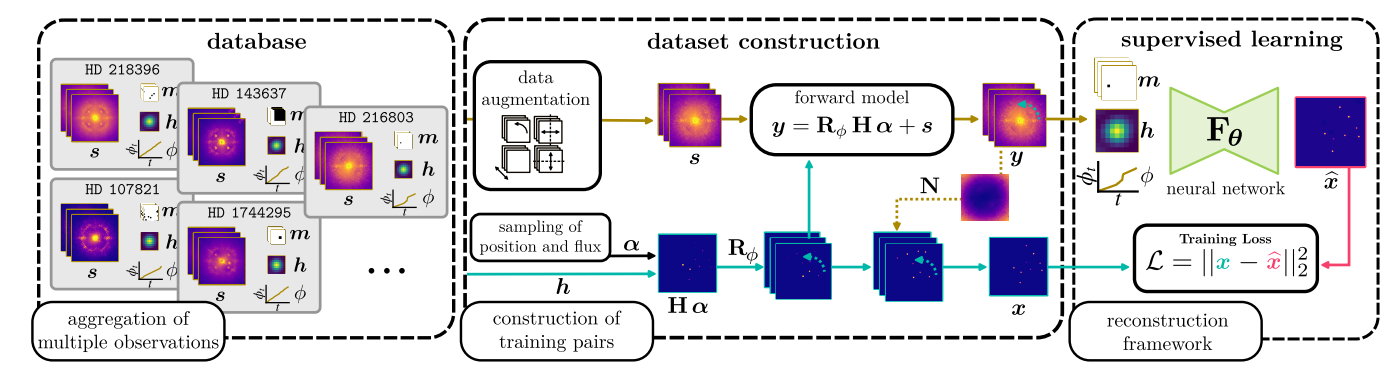
Figure
Image Processing and Machine Learning for Hyperspectral Unmixing: An Overview and the HySUPP Python Package
Participants: Behnood Rasti, Alexandre Zouaoui, Julien Mairal, Jocelyn Chanussot.
Spectral pixels are often a mixture of the pure spectra of the materials, called endmembers, due to the low spatial resolution of hyperspectral sensors, double scattering, and intimate mixtures of materials in the scenes. Unmixing estimates the fractional abundances of the endmembers within the pixel. Depending on the prior knowledge of endmembers, linear unmixing can be divided into three main groups: supervised, semi-supervised, and unsupervised (blind) linear unmixing. Advances in Image processing and machine learning substantially affected unmixing. This paper 14 provides an overview of advanced and conventional unmixing approaches. Additionally, we draw a critical comparison between advanced and conventional techniques from the three categories. We compare the performance of the unmixing techniques on three simulated and two real datasets. The experimental results reveal the advantages of different unmixing categories for different unmixing scenarios. Moreover, we provide an open-source Python-based package available at github.com/BehnoodRasti/HySUPP to reproduce the results.
Fast Semi-supervised Unmixing using Non-convex Optimization
Participants: Behnood Rasti, Alexandre Zouaoui, Julien Mairal, Jocelyn Chanussot.
In this 13, we introduce a novel linear model tailored for semisupervised/library-based unmixing. Our model incorporates considerations for library mismatch while enabling the enforcement of the abundance sum-to-one constraint (ASC). Unlike conventional sparse unmixing methods, this model involves nonconvex optimization, presenting significant computational challenges. We demonstrate the efficacy of Alternating Methods of Multipliers (ADMM) in cyclically solving these intricate problems. We propose two semisupervised unmixing approaches, each relying on distinct priors applied to the new model in addition to the ASC: sparsity prior and convexity constraint. Our experimental results validate that enforcing the convexity constraint outperforms the sparsity prior for the endmember library. These results are corroborated across three simulated datasets (accounting for spectral variability and varying pixel purity levels) and the Cuprite dataset. Additionally, our comparison with conventional sparse unmixing methods showcases considerable advantages of our proposed model, which entails nonconvex optimization. Notably, our implementations of the proposed algorithms—fast semisupervised unmixing (FaSUn) and sparse unmixing using soft-shrinkage (SUnS)—prove considerably more efficient than traditional sparse unmixing methods. SUnS and FaSUn were implemented using PyTorch and provided in a dedicated Python package called Fast Semisupervised Unmixing (FUnmix), which is open-source and available at https://github.com/BehnoodRasti/FUnmix.
Enhancing Contrastive Learning with Positive Pair Mining for Few-shot Hyperspectral Image Classification
Participants: Nassim Ait Ali Braham, Julien Mairal, Jocelyn Chanussot, Lichao Mou, Xiao Xiang Zhu.
In recent years, deep learning has emerged as the dominant approach for hyperspectral image (HSI) classification. However, deep neural networks require large annotated datasets to generalize well. This limits the applicability of deep learning for real-world HSI classification problems, as manual labeling of thousands of pixels per scene is costly and time consuming. In this article, we tackle the problem of few-shot HSI classification by leveraging state-of-the-art self-supervised contrastive learning with an improved view-generation approach. Traditionally, contrastive learning algorithms heavily rely on hand-crafted data augmentations tailored for natural imagery to generate positive pairs. However, these augmentations are not directly applicable to HSIs, limiting the potential of self-supervised learning in the hyperspectral domain. To overcome this limitation, we introduce in 2 two positive pair-mining strategies for contrastive learning on HSIs. The proposed strategies mitigate the need for high-quality data augmentations, providing an effective solution for few-shot HSI classification. Through extensive experiments, we show that the proposed approach improves accuracy and label efficiency on four popular HSI classification benchmarks. Furthermore, we conduct a thorough analysis of the impact of data augmentation in contrastive learning, highlighting the advantage of our positive pair-mining approach.
7.4 Optimization
Exponential Moving Average of Weights in Deep Learning: Dynamics and Benefits
Participants: Daniel Morales Brotons, Thijs Vogels, Hadrien Hendrikx.
Weight averaging of Stochastic Gradient Descent (SGD) iterates is a popular method for training deep learning models. While it is often used as part of complex training pipelines to improve generalization or serve as a ‘teacher’ model, weight averaging lacks proper evaluation on its own. In this work 10, we present a systematic study of the Exponential Moving Average (EMA) of weights. We first explore the training dynamics of EMA, give guidelines for hyperparameter tuning, and highlight its good early performance, partly explaining its success as a teacher. We also observe that EMA requires less learning rate decay compared to SGD since averaging naturally reduces noise, introducing a form of implicit regularization. Through extensive experiments, we show that EMA solutions differ from last-iterate solutions. EMA models not only generalize better but also exhibit improved i) robustness to noisy labels, ii) prediction consistency, iii) calibration and iv) transfer learning. Therefore, we suggest that an EMA of weights is a simple yet effective plug-in to improve the performance of deep learning models. Figure 20 shows the typical performance gap between SGD and EMA.
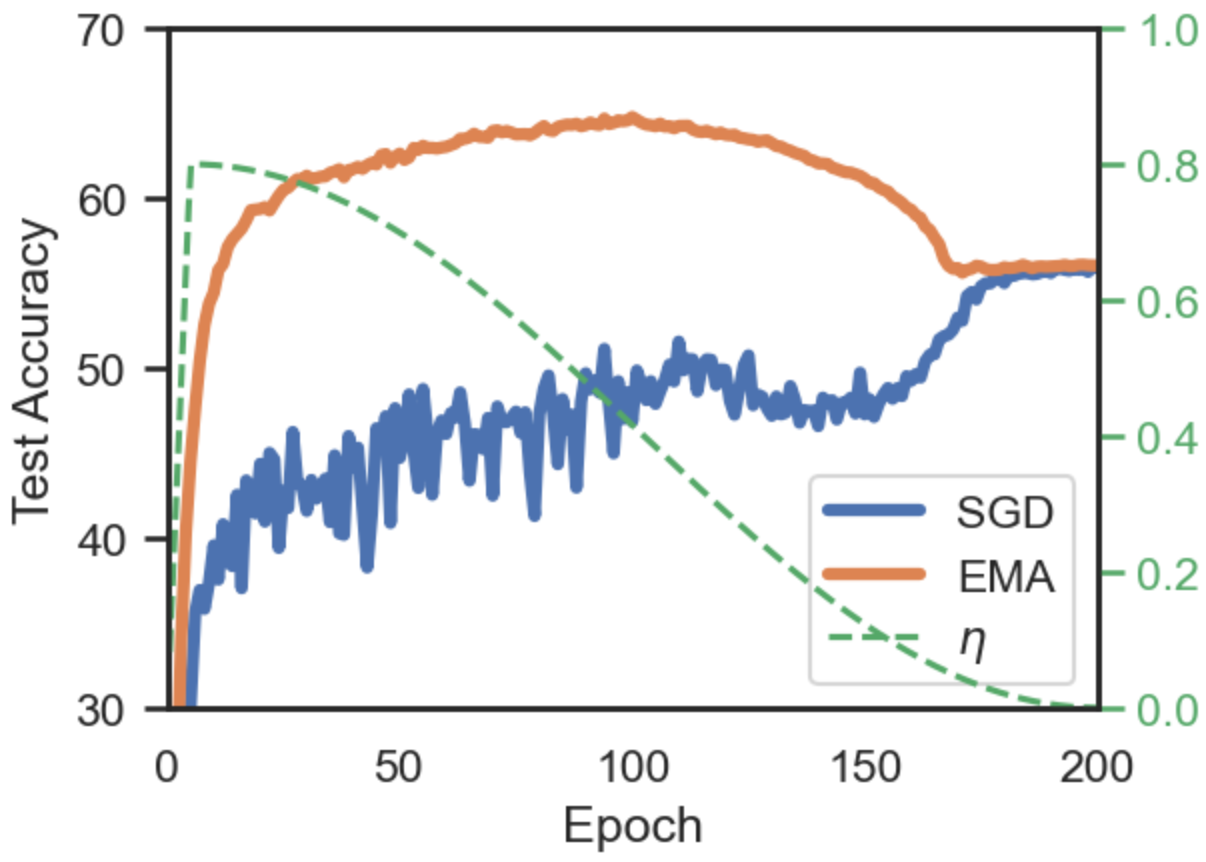
Figure
The Relative Gaussian Mechanism and its Application to Private Gradient Descent
Participants: Hadrien Hendrikx, Paul Mangold, Aurélien Bellet.
The Gaussian Mechanism (GM), which consists in adding Gaussian noise to a vector-valued query before releasing it, is a standard privacy protection mechanism. In particular, given that the query respects some L2 sensitivity property (the L2 distance between outputs on any two neighboring inputs is bounded), GM guarantees Rényi Differential Privacy (RDP). Unfortunately, precisely bounding the L2 sensitivity can be hard, thus leading to loose privacy bounds. In this paper 26, we consider a Relative L2 sensitivity assumption, in which the bound on the distance between two query outputs may also depend on their norm. Leveraging this assumption, we introduce the Relative Gaussian Mechanism (RGM), in which the variance of the noise depends on the norm of the output. We prove tight bounds on the RDP parameters under relative L2 sensitivity, and characterize the privacy loss incurred by using output-dependent noise. In particular, we show that RGM naturally adapts to a latent variable that would control the norm of the output. Finally, we instantiate our framework to show tight guarantees for Private Gradient Descent, a problem that naturally fits our relative L2 sensitivity assumption. Figure 21 shows that enforcing privacy through the Relative Gaussian Mechanism is competitive with the standard Gaussian Mechanism applied to clipped gradients.
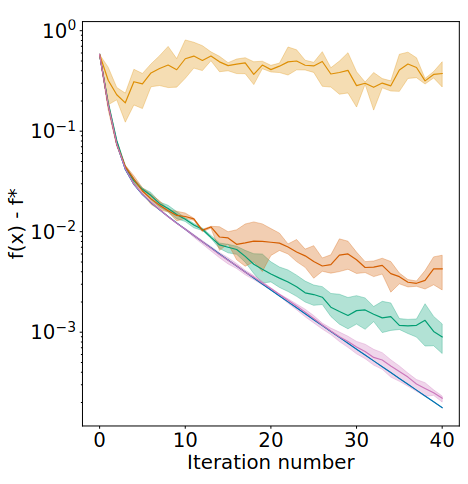
Figure
The Relative Gaussian Mechanism and its Application to Private Gradient Descent
Participants: Renaud Gaucher, Aymeric Dieuleveut, Hadrien Hendrikx.
Distributed approaches have many computational benefits, but they are vulnerable to attacks from a subset of devices transmitting incorrect information. This work 39 investigates Byzantine-resilient algorithms in a decentralized setting, where devices communicate directly with one another. We investigate the notion of breakdown point, and show an upper bound on the number of adversaries that decentralized algorithms can tolerate. This is done through careful study of a specific graph topology, presented in Figure 22. We introduce CG + , an algorithm at the intersection of ClippedGossip and NNA, two popular approaches for robust decentralized learning. CG + meets our upper bound, and thus obtains optimal robustness guarantees, whereas neither of the existing two does. We provide experimental evidence for this gap by presenting an attack tailored to sparse graphs which breaks NNA but against which CG + is robust.
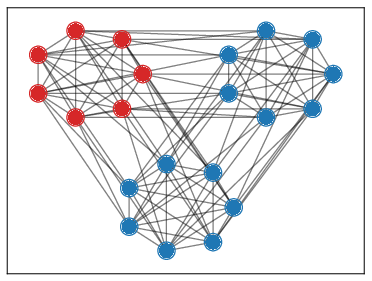
Figure
Investigating Variance Definitions for Mirror Descent with Relative Smoothness
Participants: Hadrien Hendrikx.
Mirror Descent is a popular algorithm, that extends Gradients Descent (GD) beyond the Euclidean geometry. One of its benefits is to enable strong convergence guarantees through smooth-like analyses, even for objectives with exploding or vanishing curvature. This is achieved through the introduction of the notion of relative smoothness, which holds in many of the common use-cases of Mirror descent. While basic deterministic results extend well to the relative setting, most existing stochastic analyses require additional assumptions on the mirror, such as strong convexity (in the usual sense), to ensure bounded variance. In this work 40, we revisit Stochastic Mirror Descent (SMD) proofs in the (relatively-strongly-) convex and relatively-smooth setting, and introduce a new (less restrictive) definition of variance (see Figure 23), which can generally be bounded (globally) under mild regularity assumptions. We then investigate this notion in more details, and show that it naturally leads to strong convergence guarantees for stochastic mirror descent. Finally, we leverage this new analysis to obtain convergence guarantees for the Maximum Likelihood Estimator of a Gaussian with unknown mean and variance.
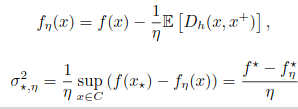
Figure
Model-Based Super-Resolution for Sentinel-5P Data
Participants: Jocelyn Chanussot.
Sentinel-5P provides excellent spatial information, but its resolution is insufficient to characterize the complex distribution of air contaminants within limited areas. As physical constraints prevent significant advances beyond its nominal resolution, employing processing techniques like single-image super-resolution (SISR) can notably contribute to both research and air quality monitoring applications. This study 3 presents the very first use of such methodologies on Sentinel-5P data. We demonstrate that superior results may be obtained if the degrading filter used to simulate pairs of low- and high-resolution (HR) images is tailored to the acquisition technology at hand, an issue frequently ignored in the scientific literature on the subject. Because of this, as well as the fact that these data have never been deployed in any previous studies, the primary theoretical contribution of this article is the estimation of the degradation model of TROPOspheric Monitoring Instrument (TROPOMI), the sensor mounted on Sentinel-5P. Leveraging this model—which is essential for applications involving super-resolution—we additionally improve a well-known deconvolution-based strategy and present a brand-new neural network that outperforms both traditional super-resolution techniques and well-established neural networks in the field. The findings of this study, which are supported by experimental tests on real Sentinel-5P radiance images, using both full-scale and reduced-scale protocols, offer a baseline for enhancing algorithms that are driven by the understanding of the imaging model and provide an efficient way of evaluating innovative approaches on all the available images.
The code is available at https://github.com/alcarbone/S5P_SISR_Toolbox.
Spectral–Spatial Transformer for Hyperspectral Image Sharpening
Participants: Jocelyn Chanussot.
Convolutional neural networks (CNNs) have recently achieved outstanding performance for hyperspectral (HS) and multispectral (MS) image fusion. However, CNNs cannot explore the long-range dependence for HS and MS image fusion because of their local receptive fields. To overcome this limitation, a transformer is proposed to leverage the long-range dependence from the network inputs 4. Because of the ability of long-range modeling, the transformer overcomes the sole CNN on many tasks, whereas its use for HS and MS image fusion is still unexplored. In this article, we propose a spectral–spatial transformer (SST) to show the potentiality of transformers for HS and MS image fusion. We devise first two branches to extract spectral and spatial features in the HS and MS images by SST blocks, which can explore the spectral and spatial long-range dependence, respectively. Afterward, spectral and spatial features are fused feeding the result back to spectral and spatial branches for information interaction. Finally, the high-resolution (HR) HS image is reconstructed by dense links from all the fused features to make full use of them.
SpectralGPT: Spectral Remote Sensing FoundationModel
Participants: Jocelyn Chanussot.
The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT 6, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS Big Data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; and 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS Big Data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Quantum Information-Empowered Graph Neural Network for Hyperspectral Change Detection
Participants: Jocelyn Chanussot.
Change detection (CD) is a critical remote sensing technique for identifying changes in the Earth’s surface over time. The outstanding substance identifiability of hyperspectral images (HSIs) has significantly enhanced the detection accuracy, making hyperspectral CD (HCD) an essential technology. The detection accuracy can be further upgraded by leveraging the graph structure of HSIs, motivating us to adopt the graph neural networks (GNNs) in solving HCD. For the first time, this work introduces a quantum deep network (QUEEN) into HCD. Unlike GNN and CNN, both extracting the affine-computing features, QUEEN provides fundamentally different unitary-computing features 7. We demonstrate that through the unitary feature extraction procedure, QUEEN provides radically new information for deciding whether there is a change or not. Hierarchically, a graph feature learning (GFL) module exploits the graph structure of the bitemporal HSIs at the superpixel level, while a quantum feature learning (QFL) module learns the quantum features at the pixel level, as a complementary to GFL by preserving pixel-level detailed spatial information not retained in the superpixels. In the final classification stage, a quantum classifier is designed to cooperate with a traditional fully connected classifier.
Cross-City Semantic Segmentation (C2Seg) in Multimodal Remote Sensing: Outcome of the 2023 IEEE WHISPERS C2Seg Challenge
Participants: Jocelyn Chanussot.
Given the ever-growing availability of remote sensing data (e.g., Gaofen in China, Sentinel in the EU, and Landsat in the USA), multimodal remote sensing techniques have been garnering increasing attention and have made extraordinary progress in various Earth observation (EO)-related tasks. The data acquired by different platforms can provide diverse and complementary information. The joint exploitation of multimodal remote sensing has been proven effective in improving the existing methods of land-use/land-cover segmentation in urban environments. To boost technical breakthroughs and accelerate the development of EO applications across cities and regions, one important task is to build novel cross-city semantic segmentation models based on modern artificial intelligence technologies and emerging multimodal remote sensing data. This leads to the development of better semantic segmentation models with high transferability among different cities and regions. The Cross-City Semantic Segmentation contest is organized in conjunction with the 13th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS) 8.
Investigating Abiotic Sources of Spectral Variability From Multitemporal Hyperspectral Airborne Acquisitions Over the French Guyana Canopy
Participants: Jocelyn Chanussot.
Classifiers trained on airborne hyperspectral imagery are proficient in identifying tree species in hyperdiverse tropical rainforests. However, spectral fluctuations, influenced by intrinsic and environmental factors, such as the heterogeneity of individual crown properties and atmospheric conditions, pose challenges for large-scale mapping. This study proposes an approach to assess the instability of airborne imaging spectroscopy reflectance in response to environmental variability. Through repeated overflights of two tropical forest sites in French Guiana, we explore factors that affect the spectral similarity between dates and acquisitions. By decomposing acquisitions into subsets and analyzing different sources of variability, we analyze the stability of reflectance and various vegetation indices with respect to specific sources of variability. Factors such as the variability of the viewing and sun angles or the variability of the atmospheric state shed light on the impact of sources of spectral instability, informing processing strategies. Our experiments conclude that the environmental factors that affect the canopy reflectance the most vary according to the considered spectral domain. In the short wave infrared (SWIR) domain, solar angle variation is the main source of variability, followed by atmospheric and viewing angles. In the visible and near infrared (VNIR) domain, atmospheric variability dominates, followed by solar angle and viewing angle variabilities. Despite efforts to address these variabilities, significant spectral instability persists, highlighting the need for more robust representations and improved correction methods for reliable species-specific signatures. 12
VOGTNet: Variational Optimization-Guided Two-Stage Network for Multispectral and Panchromatic Image Fusion
Participants: Jocelyn Chanussot.
Multispectral image (MS) and panchromatic image (PAN) fusion, which is also named as multispectral pansharpening, aims to obtain MS with high spatial resolution and high spectral resolution. However, due to the usual neglect of noise and blur generated in the imaging and transmission phases of data during training, many deep learning (DL) pansharpening methods fail to perform on the dataset containing noise and blur. To tackle this problem, a variational optimization-guided two-stage network (VOGTNet) for multispectral pansharpening is proposed in this work, and the performance of variational optimization (VO)-based pansharpening methods relies on prior information and estimates of spatial-spectral degradation from the target image to other two original images. Concretely, we propose a dual-branch fusion network (DBFN) based on supervised learning and train it by using the datasets containing noise and blur to generate the prior fusion result as the prior information that can remove noise and blur in the initial stage. Subsequently, we exploit the estimated spectral response function (SRF) and point spread function (PSF) to simulate the process of spatial-spectral degradation, respectively, thereby making the prior fusion result and the adaptive recovery model (ARM) jointly perform unsupervised learning on the original dataset to restore more image details and results in the generation of the high-resolution MSs in the second stage. Experimental results indicate that the proposed VOGTNet improves pansharpening performance and shows strong robustness against noise and blur. Furthermore, the proposed VOGTNet can be extended to be a general pansharpening framework, which can improve the ability to resist noise and blur of other supervised learning-based pansharpening methods. 15
The source code is available at https://github.com/HZC-1998/VOGTNet.
MeSAM: Multiscale Enhanced Segment Anything Model for Optical Remote Sensing Images
Participants: Jocelyn Chanussot.
Segment anything model (SAM) has been widely applied to various downstream tasks for its excellent performance and generalization capability. However, SAM exhibits three limitations related to remote sensing (RS) semantic segmentation task: 1) the image encoders excessively lose high-frequency information, such as object boundaries and textures, resulting in rough segmentation masks; 2) due to being trained on natural images, SAM faces difficulty in accurately recognizing objects with large-scale variations and uneven distribution in RS images; and 3) the output tokens used for mask prediction are trained on natural images and not applicable to RS image segmentation. In this article, we explore an efficient paradigm for applying SAM to the semantic segmentation of RS images. Furthermore, we propose multiscale enhanced SAM (MeSAM), a new SAM fine-tuning method more suitable for RS images to adapt it to semantic segmentation tasks. Our method first introduces an inception mixer into the image encoder to effectively preserve high-frequency features. Second, by designing a mask decoder with RS correction and incorporating multiscale connections, we make up the difference in SAM from natural images to RS images. Experimental results demonstrated that our method significantly improves the segmentation accuracy of SAM for RS images, outperforming some state-of-the-art (SOTA) methods. 16
The code will be available at https://github.com/Magic-lem/MeSAM.
S2MAE: A Spatial-Spectral Pretraining Foundation Model for Spectral Remote Sensing Data
Participants: Jocelyn Chanussot.
In the expansive domain of computer vision, a myriad of pre-trained models are at our disposal. However, most of these models are designed for natural RGB images and prove inadequate for spectral remote sensing (RS) images. Spectral RS images have two main traits: (1) multiple bands capturing diverse feature information, (2) spatial alignment and consistent spectral sequencing within the spatial-spectral dimension. In this paper, we introduce Spatial-SpectralMAE (S2MAE), a specialized pre-trained architecture for spectral RS imagery. S2MAE employs a 3D transformer for masked autoencoder modeling, integrating learnable spectral-spatial embeddings with a 90% masking ratio. The model efficiently captures local spectral consistency and spatial invariance using compact cube tokens, demonstrating versatility to diverse input characteristics. This adaptability facilitates progressive pretraining on extensive spectral datasets. The effectiveness of S2MAE is validated through continuous pretraining on two sizable datasets, totaling over a million training images. The pre-trained model is subsequently applied to three distinct downstream tasks, with in-depth ablation studies conducted to emphasize its efficacy.29
8 Bilateral contracts and grants with industry
8.1 Bilateral contracts with industry
Participants: Julien Mairal, Karteek Alahari, Pierre Gaillard, Jocelyn Chanussot.
In 2024, we had:
- two CIFRE PhD students with Facebook: Timothée Darcet (co-advised by J. Mairal) and Tariq Berrada Ifriqi (co-advised by K. Alahari).
- one CIFRE PhD student with Naver Labs Europe: Juliette Marrie (co-advised by J. Mairal and M. Arbel).
- one CIFRE PhD student with Preligens: Jules Bourcier (co-advised by K. Alahari and J. Chanussot)
- one CIFRE PhD student with Nokia Bell Labs: Camila Fernández (co-advised by P. Gaillard)
- one intern with Enhance Lab: Balthazar Neveu (co-advised by J. Mairal).
- one intern with "Pour une Agriculture du Vivant": Mohamed Bacar Abdoulandhum (co-advised by H. Hendrikx)
9 Partnerships and cooperations
9.1 International initiatives
9.1.1 Associate Teams in the framework of an Inria International Lab or in the framework of an Inria International Program
4TUNE
-
Title:
Adaptive, Efficient, Provable and Flexible Tuning for Machine Learning
-
Duration:
2020 -> 2024
-
Coordinator:
Peter Grünwald (pdg@cwi.nl)
-
Partners:
- CWI Amsterdam (Pays-Bas)
-
Inria contact:
Pierre Gaillard
-
Summary:
The long-term goal of 4TUNE is to push adaptive machine learning to the next level. We aim to develop refined methods, going beyond traditional worst-case analysis, for exploiting structure in the learning problem at hand. We will develop new theory and design sophisticated algorithms for the core tasks of statistical learning and individual sequence prediction. We are especially interested in understanding the connections between these tasks and developing unified methods for both. We will also investigate adaptivity to non-standard patterns encountered in embedded learning tasks, in particular in iterative equilibrium computations.
9.2 European initiatives
9.2.1 Horizon Europe
APHELEIA
APHELEIA project on cordis.europa.eu
-
Title:
Reconciling Classical and Modern (Deep) Machine Learning for Real-World Applications
-
Duration:
From September 1, 2023 to August 31, 2028
-
Partners:
- INSTITUT NATIONAL DE RECHERCHE EN INFORMATIQUE ET AUTOMATIQUE (INRIA), France
-
Inria contact:
Mairal Julien
- Coordinator:
-
Summary:
Despite the undeniable success of machine learning in addressing a wide variety of technological and scientific challenges, the current trend of training predictive models with an evergrowing number of parameters from an evergrowing amount of data is not sustainable. These huge models, often engineered by large corporations benefiting from huge computational resources, typically require learning a billion or more of parameters. They have proven to be very effective in solving prediction tasks in computer vision, natural language processing, and computational biology, for example, but they mostly remain black boxes that are hard to interpret, computationally demanding, and not robust to small data perturbations.
With a strong emphasis on visual modeling, the grand challenge of APHELEIA is to develop a new generation of machine learning models that are more robust, interpretable, and efficient, and do not require massive amounts of data to produce accurate predictions. To achieve this objective, we will foster new interactions between classical signal processing, statistics, optimization, and modern deep learning. Our goal is to reduce the need for massive data by enabling scientists and engineers to design trainable machine learning models that directly encode a priori knowledge of the task semantics and data formation process, while automatically prefering simple and stable solutions over complex ones. These models will be built on solid theoretical foundations with convergence and robustness guarantees, which are important to make real-life trustworthy predictions in the wild. We will implement these ideas in an open-source software toolbox readily applicable to visual recognition and inverse imaging problems, which will also handle other modalities. This will stimulate interdisciplinary collaborations, with the potential to be a game changer in the way scientists and engineers design machine learning problems.
9.3 National initiatives
9.3.1 ANR Project BONSAI
Participants: Michael Arbel.
- Project BONSAI is a multi-disciplinary project aiming at integrating knowledge produced by experts, in the form of simulators, into current machine learning frameworks through bilevel optimization for accurate and efficient inference. We address three challenges. The first one is to develop a deep learning-based approach to simulation-based inference that can adapt to data using bilevel optimization. A second challenge is to depoly the methods to real-world problems which have their specificities. A third challenge is to develop bilevel optimization methods that can handle the non-convexity and over-parameterization arising from using deep learning. The principal investigator is Michael Arbel, and the project involves participants from Toulouse School of Economics, TIMC team at UGA and other INRIA teams (Statify). This project started in April 2024.
9.3.2 MIAI chair: Towards More Data Efficiency in Machine Learning
Participants: Julien Mairal, Karteek Alahari, Massih-Reza Amini, Margot Selosse, Juliette Marrie, Romain Menegaux, Ieva Petrulyonite.
- Training deep neural networks when the amount of annotated data is small or in the presence of adversarial perturbations is challenging. More precisely, for convolutional neural networks, it is possible to engineer visually imperceptible perturbations that can lead to arbitrarily different model predictions. Such a robustness issue is related to the problem of regularization and to the ability to generalizing with few training examples. Our objective is to develop theoretically-grounded approaches that will solve the data efficiency issues of such huge-dimensional models. The principal investigator is Julien Mairal.
9.3.3 MIAI chair: Learning Visual Representations from Interaction for Robot Manipulation Tasks
Participants: Pia Bideau, Karteek Alahari.
- How to grasp an object has been studied in computer vision and robotics and several approaches to this problem exist - either given a 3D shape of an object contact points are determined that lead to a stable hand object configuration or an other line of work aims at reconstructing stable hand object configurations modelling the reconstruction process of hand pose and object pose jointly. In both cases many solutions are possible, although a majority might not be the natural approach that humans would chose - mainly because the intention behind the grasp is omitted. This project aims at learning visual representations from interaction that encode activity information. Encoding such contextual information appears not only to be relevant to synthesise feasible grasps furthermore this is likely to enhance future generalisation skills facilitating adaptation across the same activity but different objects - grasping a cup to pour something into something shares similar motion pattern as grasping a bottle to pour something into something. Inspired by the effectiveness of human grasping, we aim at finding similarly adaptable representations that are capable of guiding complex manipulation skills. To this end we will fuse ideas relying on classical probabilistic modeling of distributions over possible motion trajectories and latent action representations from a conditional variational autoencoder (CVAE). Both of these directions come with complementary strengths and thus provide promising capabilities of modulating the degree of action abstractions at test time to enable both coarse and fine-grained control for real world robot manipulation tasks. The chair is taking place in collaboration with Karteek Alahari, Xavier Alameda-Pineda, and Pierre-Brice Wieber. We have recruited one PhD student and have an intern starting in February 2025.
9.3.4 MIAI chair: Multiscale multimodal multitemporal remote sensing
Participants: Jocelyn Chanussot.
- J. Chanussot was the co-chair, with Wilfried Thuiller (Laboratory for Alpine Ecology) of this MIAI chair that focused on developping advanced methodologies for the exploitation of remote sensing data.
9.3.5 Deep Red
Participants: Jocelyn Chanussot.
- J. Chanussot is the chair of the Deep Red project from the Foundation Grenoble INP under the patronage of Lynred company (2022-2026). The project aims at popularizing the technology of infrared imaging for new usages.
9.3.6 PEPR project Numpex
Participants: Hadrien Hendrikx.
- The 'Numpex' programme's objectives are to design and develop the software building blocks required to equip future 'exascale machines' and to prepare the major application domains that aim to fully exploit the capabilities of such machines for scientific research and industry alike. This project is part of France's response to the next EuroHPC call for expressions of interest (Projet Exascale France) in hosting one of the two major exascale machines planned in Europe for 2024. In this way 'Numpex' will contribute to the creation of a set of tools, software, applications and training which will enable France to remain one of the leaders in the field of international competition through its national Exascale ecosystem that is in step with European strategy.
9.3.7 PEPR project Origins
Participants: Julien Mairal.
- Thoth is involved in the axis “Direct imaging and exoplanet characterization” of the PEPR Origins. This is an on-going collaboration with astronomers from Observatoire de Paris and Lyon and with the Willow team.
10 Dissemination
10.1 Promoting scientific activities
10.1.1 Scientific events: organisation
General chair, scientific chair
- J. Chanussot was general co-chair for IEEE GRSS WHISPERS 2024 (200 participants, Helsinki, Finland).
- J. Chanussot will be general co-chair for IEEE IGARSS 2025 (3000-4000 expected participants, Brisbane, Australia).
10.1.2 Scientific events: selection
Chair of conference program committees
- K. Alahari will be a program co-chair for ECCV 2028 (Bucharest, Romania).
Member of the conference program committees
- K. Alahari was an area chair for ACCV 2024, CVPR 2024, ECCV 2024, and will be area chair for upcoming CVPR 2025, ICCV 2025.
Reviewer
The permanent members, postdocs and senior PhD students of the team reviewed numerous papers for international conferences in artificial intelligence, computer vision and machine learning, including AISTATS, CVPR, ECCV, ICML, ICLR, NeurIPS in 2024.
10.1.3 Journal
Member of the editorial boards
- J. Mairal. Editor for Journal of Machine Learning Reseach (JMLR).
- K. Alahari. Associate editor of International Journal of Computer Vision (IJCV).
- J. Chanussot. Associate editor of IEEE Transactions on Geoscience and Remote Sensing (TGRS).
Reviewer - reviewing activities
The permanent members, postdocs and senior PhD students of the team reviewed numerous papers for international journals in computer vision (IJCV, PAMI), machine learning (JMLR), remote sensing (TGRS), and statistics (AOS).
10.1.4 Invited talks
- J. Mairal. Invited seminar at the Liphy laboratory (physics laboratory), Grenoble.
- J. Mairal. Invited talk at the CRAL laboratory (astrophysics laboratory), Lyon.
- J. Mairal. Invited talk at the LPLC laboratory (cosmology laboratory), Grenoble.
- J. Mairal. Invited talk at Bordeaux University.
- J. Mairal. Invited talk at a workshop organized by Academie des Sciences, Paris.
- J. Mairal. Invited talk at the DEEPK 2024 workshop. Leuven.
- J. Mairal. Invited talk at the LOL workshop, Luminy.
- J. Mairal. Keynote speaker at the Themosia conference (chemistry conference), Rouen.
- J. Mairal. Keynote speaker at the PEPR IA Kick-off day. Grenoble.
- K. Alahari. Invited talks at Minalogic, Grenoble.
- K. Alahari. Invited seminar at CHROMA team, Grenoble.
- P. Gaillard. Invited talk at Erice Summer School, Italy.
- M. Arbel. Invited talk at ACM conference on reproductibility and replicability, Rennes France.
- H. Hendrikx. Invited talk at plénière défi Inria FedMalin, Lyon.
- H. Hendrikx. Invited talk at Kickoff défi Nokia-Inria, Paris.
- H. Hendrikx. Invited talk at plénière PEPR Redeem, Autrans.
- H. Hendrikx. Invited talk at EUROPT, Lund University, Lund.
- H. Hendrikx. Invited talk at the CMAP (Applied math department of Ecole Polytechnique), Puy Saint-Vincent.
- H. Hendrikx. Invited talk at the WDCL workshop, Paris.
- J. Chanussot. Invited talk at the ML4Earth Foundation Models for Earth Observation workshop, Munich, Germany.
- J. Chanussot. Invited talk at IsTerre, Grenoble.
- S. Pesme. Invited talk at the DAO-GHOST seminar in Grenoble.
- S. Pesme. Invited talk at the Gipsa-lab seminar in Grenoble.
- S. Pesme. Invited talk at the MLSP seminar in Lyon.
- S. Pesme. Invited talk at the MALGA seminar in Genoa.
- P. Bideau invited talk at the French Korean Workshop on AI, Networks, Programming Languages and Mathematical Sciences at KAIST, Session: Generative AI.
- P. Bideau invited talk at the INRIA-DFKI Summer School on AI for Robotics, Saarbrücken (Germany).
- P. Bideau invited talk at the Multidisciplinary Institute for Artificial Intelligence (MIAI), Université Grenoble Alpes.
10.1.5 Scientific expertise
- K. Alahari was a member of the CRCN/ISFP 2024 recruitment committee at Grenoble.
- P. Gaillard was member of the recruitment committee for an Assistant Professor position at Univ. Paris-Cité.
- P. Gaillard was member of the recruitment commitee for a lecturer position at Sorbonne Univ.
10.1.6 Research administration
- J. Mairal is a member of the scientific committee (COS) of Inria Grenoble's research center, and also a member of the scientific committee of MIAI.
- K. Alahari is the deputy scientifc director in charge of AI at Inria.
- K. Alahari is one of the scientific directors of the PEPR AI research programme.
- K. Alahari is responsible for the Mathematics and Computer Science specialist field at the MSTII doctoral school.
- K. Alahari is a member of commission prospection postes at LJK.
- J. Chanussot is a member of the Commission Recherche, University Grenoble Alps.
10.2 Teaching - Supervision - Juries
10.2.1 Teaching
- Master: K. Alahari, Advanced Machine Learning, 9h eqTD, M2, UGA, Grenoble.
- Master: K. Alahari, Continually Learning Visual Representations, 15.75h eqTD, M2, Grenoble INP.
- Master: K. Alahari, Graphical Models Inference and Learning, 13.5h eqTD, MVA, M2, CentraleSupelec, Paris.
- Master/PhD: K. Alahari, African Computer Vision Summer School, 4.5h eqTD, Nairobi, Kenya.
- Master: P. Bideau, Advanced Machine Learning, 4.5h eqTD, M2, UGA, Grenoble.
- Master: J. Marrie, Kernel methods for statistical learning, 12h eqTD, M2, African Master on Machine Intelligence (AMMI).
- PhD: J. Mairal, Machine Learning for science, 6h eqTD, algoSB winter school, Cargese.
- Master: J. Mairal, Kernel methods for statistical learning, 12.5h eqTD, M2, ENS Paris-Saclay, France.
- Master: J. Mairal, Kernel methods for statistical learning, 13.5h eqTD, M2, UGA, Grenoble.
- Master: P. Gaillard, Sequential Learning, 13.5h eqTD, M2, Ecole Normale Supérieure, Cachan, France.
- Master: P. Gaillard, Kernel methods for statistical learning, 18h eqTD, M2, UGA, Grenoble.
- Master: P. Gaillard, Online Convex Opitmization, 18h eqTD, M2, Sorbonne Université, Paris.
- Master: P. Gaillard, Mathematical foundations of machine learning, 13.5eqTD, M2, UGA, Grenoble.
- Master: H. Hendrikx, Generalization Properties of Machine Learning Algorithms, 9h eqTD, M2, Université Paris Saclay, Orsay.
- Master: H. Hendrikx, Numerical Optimisation, 25h eqTD, M1, Université Grenoble Alpes, Grenoble.
- Master: M. Arbel, Kernel methods for statistical learning, 13.5h eqTD, M2, UGA, Grenoble.
- Master: M. Arbel, Kernel methods for statistical learning, 12.5h eqTD, M2 MVA, ENS Paris-Saclay.
- Master: J. Chanussot, Hyperspectral remote sensing, 25h eqTD, M2 SICOM, Grenoble INP PHELMA/ENSE3.
- Master: J. Chanussot, Infra-red image processing and artificial intelligence, 15h eqTD, M1 Grenoble INP programme kaléidoscope.
- Master: J. Chanussot, projet intégrateur, 20h eqTD, M2 ASI Grenoble INP ENSE3.
- Master: G. Meanti, lectures on Natural Language Processing, 12 eqTD, University of Genova
- Master: R. Menegaux. Introdiction to Deep Learning, 4.5h eqTD, Sacl-AI 4 Science Workshop, Université Paris-Saclay.
- Master: R. Menegaux. Kernel Methods in Machine Learning, 40h eqTD, African Master’s in Machine Intelligence, Mbour Senegal.
- Master: I. Petrulyonite. Programming Language Semantics and Compiler Design, 33h eqTD. UGA.
10.2.2 Supervision
- Jules Bourcier defended his PhD in Nov 2024. He was co-advised by K. Alahari, J. Chanussot and G. Dashyan (Preligens/Safran.AI).
- Gaspard Beugnot defended his PhD in Jan 2024. He was co-advised by J. Mairal and A. Rudi (Inria Sierra).
10.2.3 Juries
- J. Mairal was member of the PhD committee of Amim El Ahmad, Telecom ParisTech.
- J. Mairal was member of the PhD committee of Benjamin Lambert, UGA.
- J. Mairal was member of the PhD committee of Yingyi Chen, KU Leuven.
- J. Mairal was president of the PhD committee of Yangtao Wang, UGA.
- J. Mairal was president of the PhD committee of Aurelien Gauffre, UGA.
- J. Mairal was reviewer and president of the jury for the PhD thesis of Leon Zheng, ENS Lyon.
- J. Mairal was reviewer for the PhD thesis of Michaël Sander, ENS-PSL.
- J. Mairal was reviewer for the PhD thesis of Charles Laroche, Université Paris-Cité.
- K. Alahari was reviewer for the PhD thesis of Pierre Marza, INSA Lyon.
- K. Alahari was reviewer for the PhD thesis of Louis Fournier, Sorbonne Univ.
- K. Alahari was reviewer and president of the jury for the PhD thesis of Karim Radouane, IMT Mines Alès.
- K. Alahari was reviewer for the PhD thesis of Di Yang, Uôiv. Cote d'Azur.
- K. Alahari was reviewer for the PhD thesis of Harsh Rangawi, IISc Bangalore, India.
- K. Alahari was reviewer for the PhD thesis of Guillaume Lacharme, Univ. Tours.
- K. Alahari was member of the PhD committee of Deniz Engin, Univ. Rennes.
- P. Gaillard was member of the PhD committee of Victor Boone, UGA.
- P. Gaillard was member of the PhD committee of Clara Carlier, IPP Paris.
- H. Hendrikx was member of the PhD committee of Edwige Cyffers, Université de Lille.
- J. Chanussot was reviewer for the PhD thesis of Muhammad Saad Shaikh, Mid Sweden University (Sweden).
- J. Chanussot was reviewer for the PhD thesis of Alex Levering, Wageningen University (The Netherlands).
- J. Chanussot was reviewer for the PhD thesis of Mohamed Abderrazak CHERIF, Université Côte d’Azur, Géoazur.
- J. Chanussot was reviewer for the PhD thesis of Manohar Kumar C.V.S.S., Indian Institute of Space Science and Technology (India).
- J. Chanussot was reviewer for the PhD thesis of Sadia Hussain Dar, Indian Institute of Technology Delhi (India).
- J. Chanussot was reviewer for the PhD thesis of Joseph Jenkins, Université de Toulon.
- J. Chanussot was reviewer for the PhD thesis of Kinan Abbas, Université Littoral Côte d’Opale.
- J. Chanussot was reviewer for the PhD thesis of Mohamed Ali Ghannami, ENSTA Bretagne
- J. Chanussot was reviewer for the PhD thesis of P. Shalmiya, SASTRA, (India)
- J. Chanussot was reviewer for the PhD thesis of Hamza Rami, Institut Polytechnique de Paris
- J. Chanussot was president of the jury for the PhD thesis of Sara Arioli, Université Grenoble Alpes
- J. Chanussot was reviewer for the PhD thesis of Cheick Tidiani Cissé, Université de Technologie de Belfort-Montbéliard
- J. Chanussot was president of the jury for the PhD thesis of Tristan Montagnon, Université Grenoble Alpes
- J. Chanussot was reviewer for the PhD thesis of Max Muzeau, Université Paris Saclay
10.3 Popularization
10.3.1 Others science outreach relevant activities
- J. Mairal participated in a round table on “IA et numérique : Éthique, impact sur la société et sur la science” at Inria's scientific days.
- P. Gaillard participated in a round table on “IA et énergie” at Tech&Fest, Grenoble
- J. Chanussot constructed from scratch an escape game, named “l’affaire Pélican” for the Tech&Fest, Grenoble. The preparation of the game involved 18 students from 5 engineering schools, a 160sqm space was specifically organized featuring different rooms with challenges that needed the use of infrared sensing to be solved. 260 participants could experience the game in teams of 5. The project received some media coverage (TV Grenoble, Dauphiné Libéré, Blogs…).
11 Scientific production
11.1 Publications of the year
International journals
International peer-reviewed conferences
Conferences without proceedings
Doctoral dissertations and habilitation theses
Reports & preprints