

Section: Scientific Foundations
Experimentation Methodology
Participants : Sébastien Badia, Pierre-Nicolas Clauss, El Mehdi Fekari, Stéphane Genaud, Jens Gustedt, Marion Guthmuller, Lucas Nussbaum, Martin Quinson, Cristian Rosa, Luc Sarzyniec, Christophe Thiéry.
As emphasized above, our scientific objects are constituted by modern distributed systems. The scientific questions that we address mainly concern the performance and correction of these systems. Their specificities are their ever increasing size, complexity and dynamics. This has reached a point where it becomes practically impossible to fully understand these systems through the fine description of their components' interaction. In that sense, computer science occupies a relatively unique position in epistemology since its scientific objects are human built artifacts, but become too complex to be directly understood by humans. This mandates a shift from the methodologies traditionally used in speculative sciences, where the knowledge is built a priori without experiments, to the ones of natural sciences, centered on the accumulation of knowledge through experiments.
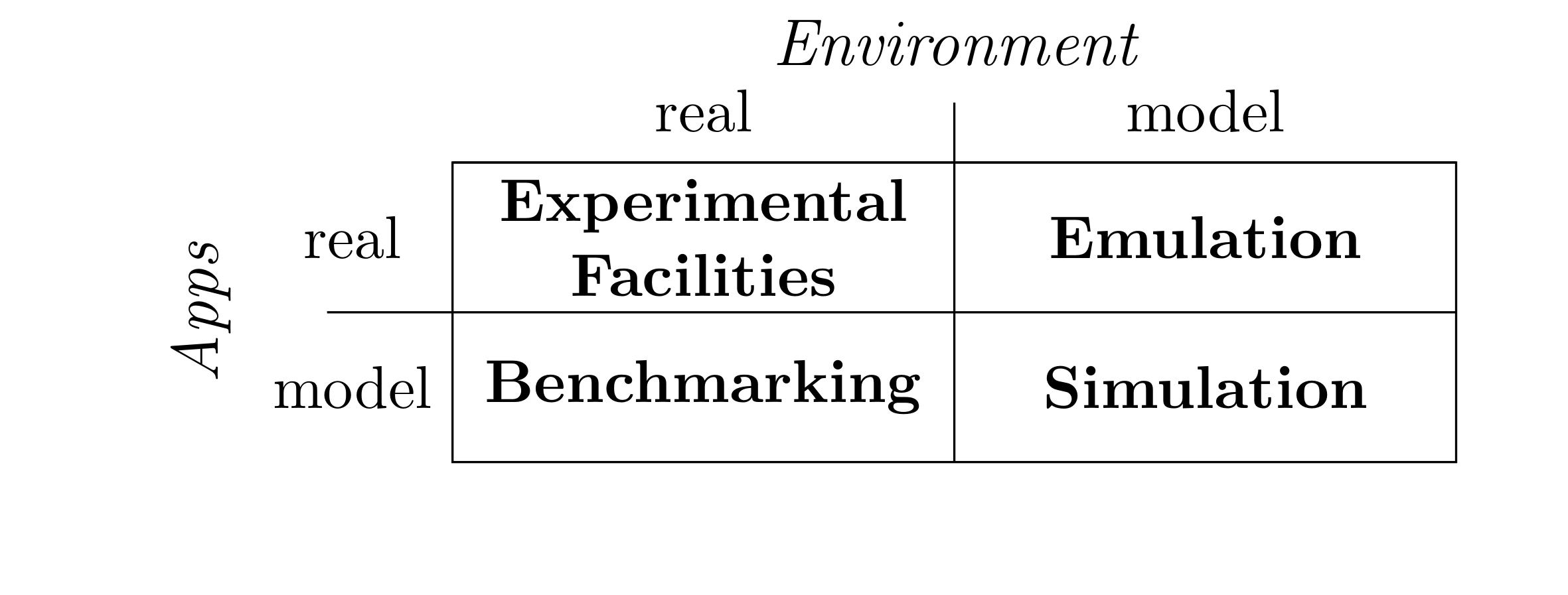
These experiments can naturally be conducted on real platforms, but it is rarely practical to do so on real production platforms: the experiments can be disruptive to the production usage, and ongoing production can impose an uncontrollable bias on experiments. Direct execution on experimental facilities such as Grid'5000 alleviate these issues by providing a computing infrastructure similar to the targeted production platforms but dedicated to experiments and completely controllable. The obvious advantage of such direct execution is that it removes almost any experimental bias but it is naturally not applicable for some studies where the application to test or the target platform are not available. That is why simulation is very attractive to conduct what if analysis, for example to dimension a platform still to be built according to a given requirement, or to select the best algorithm for an application which is still to be written. Several intermediate steps exist between simulation and direct execution: benchmarking consists in experimenting with a real environment using synthetic applications while emulation consists in executing a real application on a platform model. The former is mainly used to devise some absolute insight about the environment without taking the application specificities into account. The latter is helpful to assess the behavior of an application on an environment that is not available [7] .
These experimental methodologies are complementary, and the experimenters should combine them accordingly to benefit from their strengths in the process leading from an idea to a released product. Simulation is well adapted to the study of algorithms and helps in the realization of prototypes; direct execution on experimental facilities is an essential tool to change a prototype into an application; emulation permits to test the application in a wide range of conditions to transform it into a robust product.
Our team is active on most experimental methodologies (the only exception is benchmarking, since it consists in abstracting from the application to focus on the platforms while our whole approach is centered on the applications). This gives us an ideal position to attack the larger challenge of improving experimental methodology in distributed systems research, in order to put it on par with what is done in other sciences. We will ensure that our methods and tools support a top-quality and unified experimental process by bridging interfaces and validating our work through series of experiments spanning all methodologies.
This axis and the Structuring applications axis benefit from each other by building a positive feedback loop: the Structuring applications axis provides first-class use cases, while the Experimentation axis helps to confirm the design choices made in the first axis. Other use cases are provided by our ongoing collaborations with the production grids community, with industry and with the Grid'5000 ecosystem (through INRIA AEN Hemera).
Simulation and dynamic verification.
Our team plays a key role in the SimGrid project, a mature simulation toolkit widely used in the distributed computing community. Since over ten years, we work on the validity, scalability and robustness of our tool. In the recent years, we increased its audience by targeting the P2P research community in addition to the one for grid scheduling. It now allows precise simulations of millions of nodes using a single computer.
In the future, we aim at extending further the applicability to Clouds and Exascale systems. Therefore, we will provide disk and memory models in addition to the already existing network and CPU models. We will also pursue our efforts on the tool's scalability and efficiency. Interfaces constitute another important work axis, with the addition of specific APIs on top of our simulation kernel. They will provide the “syntactic sugar” needed to express algorithms of these communities. For example, virtual machines will be handled explicitly in the interface provided for Cloud studies. Similarly, we will pursue our work on an implementation of the MPI standard allowing to study real applications using that interface. This work will also be extended to other interfaces such as OpenMP or the ones developed in our team to structure the applications, e.g ORWL. During the next evaluation period, we also consider using our toolbox to give online performance predictions to the runtimes. It would allow these systems to improve their adaptability to the changing performance conditions experienced on the platform.
We recently integrated a model checking kernel in our tool to enable formal correction studies in addition to the practical performance studies enabled by simulation. Being able to study these two fundamental aspects of distributed applications from the same tool constitute a major advantage. In the next evaluation period, we will further work on this convergence for the study of correctness and performance using the same tools. Ensuring that they become usable on real applications constitute another challenge that we will address.
Experimentation on experimental facilities
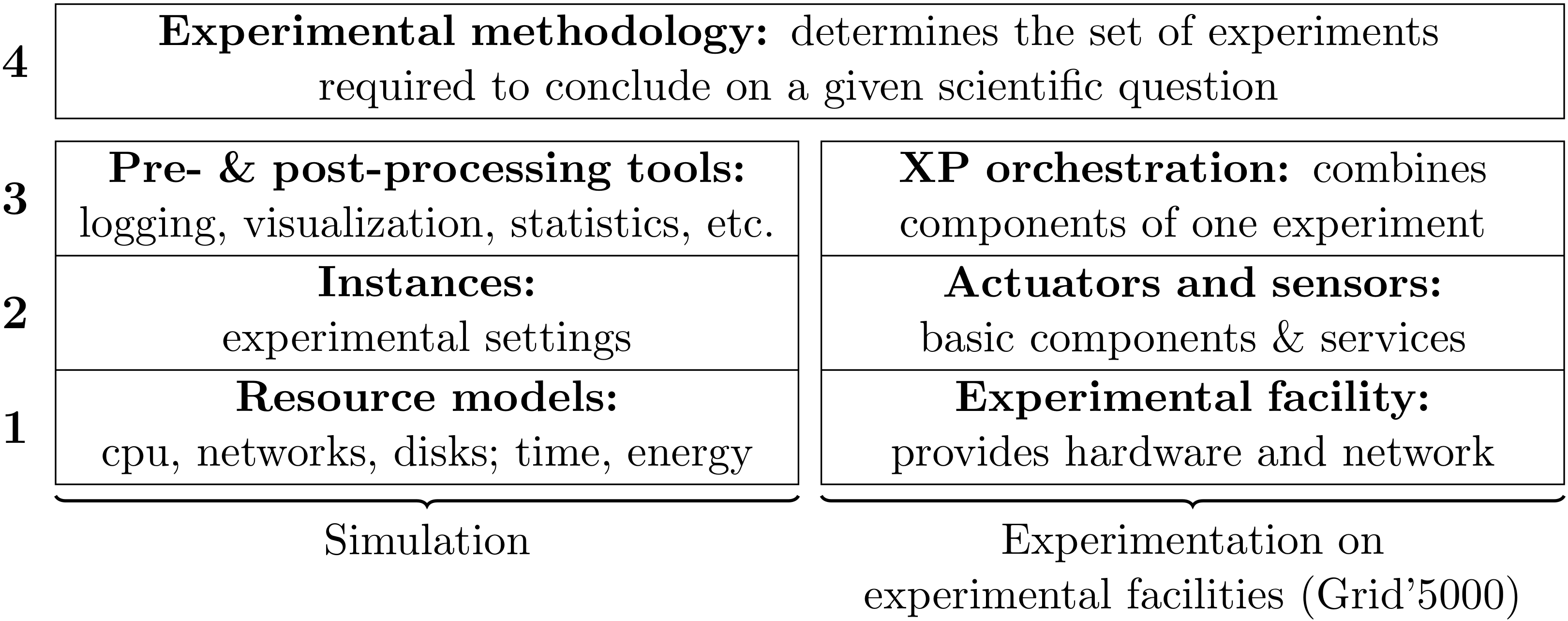
During the last years, we have played a key role in the design and development of Grid'5000 by taking part in technical and design discussions and by managing several engineers working on the platform. We will pursue our involvement in the design of the testbed with a focus on ensuring that the testbed provides all the features needed for high-quality experimentation.
We will also work on experiment-supporting software, such as Kadeploy (software used to deploy user environments on Grid'5000) in INRIA ADT Kadeploy (2011-2013) and basic services that are common to most experiments (control of a large number of nodes, data management, etc.) in INRIA ADT Solfege (2011-2013).
Specifically, we will pursue the development of our emulation framework, Distem (based on our previous emulation framework, Wrekavoc). We will address new challenges such as multi-core and heterogeneous systems, add load generation and fault injection features, and increase its usability, to get it widely accepted and used within the community.
Most experiments performed on Grid'5000 are still controlled manually or, in the best case, with quick and dirty scripts. This severely limits the quality of experimental results since it is hard to reproduce experiments many times to ensure statistical validity or to fully describe an experimental setup which was not created by an automated process. It also limits the scale and/or complexity of the possible experiments. Together with researchers from the field of Business Process Management (BPM), we will work on enabling the use of Workflow Management Systems to perform experiments on distributed systems.
Overall, we hope that our work in this research axis will bring major contributions to the industrialization of experimentation on parallel and distributed systems.