

Section: New Results
Rendering, inpainting and super-resolution
image-based rendering, inpainting, view synthesis, super-resolution
Transformation of the Beta distribution for color transfer
Participants : Hristina Hristova, Olivier Le Meur.
After having investigated the use of multivariate generalized Gaussian distribution in color transfer, we propose a novel transformation between two Beta distributions. The key point is that performing a Gaussian-based transformation between bounded distributions may result in out-of-range values. Furthermore, as a symmetrical distribution, the Gaussian distribution cannot model asymmetric distributions. This reveals important limitations of the Gaussian model when applied to image processing tasks and, in particular, to color transfer. To tackle these limitations of the Gaussian-based transformations, we investigate the use of bounded distributions, and more specifically, the Beta distribution. The Beta distribution is a bounded two-parameter dependent distribution, which can admit different shapes and thus, fit various data, bounded in a discrete interval. Adopting the Beta distribution to model color and light distributions of images is our key idea and motivation. The proposed transformation progressively and accurately reshapes an input Beta distribution into a target Beta distribution using four intermediate statistical transformations. Experiments have shown that the proposed method obtains more natural and less saturated results than results of recent state-of-the-art color transfer methods. Moreover, the results portray better both the target color palette and the target contrast.
Light field inpainting and edit propagation
Participants : Oriel Frigo, Christine Guillemot, Mikael Le Pendu.
With the increasing popularity of computational photography brought by light field, simple and intuitive editing of light field images is becoming a feature of high interest for users. Light field editing can be combined with the traditional refocusing feature, allowing a user to include or remove objects from the scene, change its color, its contrast or other features.
A simple approach for editing a light field image can be obtained with an edit propagation, where first a particular subaperture view is edited (most likely the center one) and then a coherent propagation of this edit is performed through the other views. This problem is particularly challenging for the task of inpainting, as the disparity field is unknown under the occludding mask.
We have developed two methods which exploit two different light field priors, namely a low rank prior and a smoothness prior in epipolar plane images (EPI) to propagate a central view inpainting or edit to all the other views. In the first method, a set of warped versions of the inpainted central view with random homographies are vectorized and concatenated columnwise into a matrix together with the views of the light field to be inpainted. Because of the redundancy between the views, the matrix satisfies a low rank assumption enabling us to fill the region to inpaint with low rank matrix completion. To this end, a new matrix completion algorithm, better suited to the inpainting application than existing methods, has also been developed. In its simple form, our method does not require any depth prior, unlike most existing light field inpainting algorithms. The method has then been extended to better handle the case where the area to inpaint contains depth discontinuities.
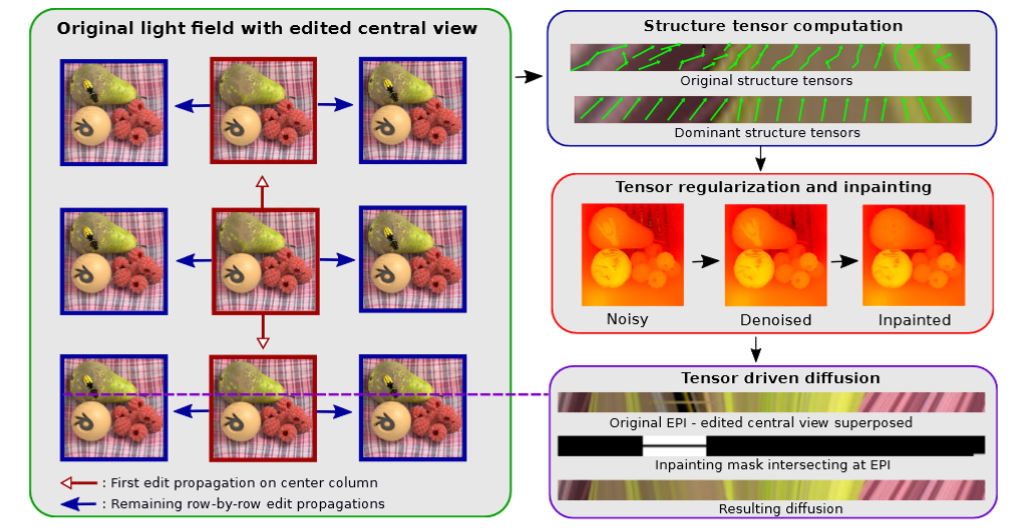
In the second approach, the problem of propagating an edit from a single view to the remaining light field is solved by a structure tensor driven diffusion on the epipolar plane images [29]. Since EPIs are piecewise smooth and have no complex texture content, tensor driven diffusion is naturally suited for inpainting the EPIs as an efficient technique to obtain a coherent edit propagation. The proposed method has been shown to be useful for two applications: light field inpainting and recolorization. While the light field recolorization is obtained with a straightforward diffusion, the inpainting application is particularly challenging, as the structure tensors accounting for disparities are unknown under the occluding mask. This issue has been addressed with a disparity inpainting by means of an interpolation constrained by superpixel boundaries.
|
Light fields super-resolution
Participants : Christine Guillemot, Lara Younes.
Capturing high spatial resolution light fields remains technologically challenging, and the images rendered from real light fields have today a significantly lower spatial resolution compared to traditional 2D cameras. In collaboration with the University of Malta (Prof. Reuben Farrugia), we have developed an example-based super-resolution algorithm for light fields, which allows the increase of the spatial resolution of the different views in a consistent manner across all sub-aperture images of the light field [12]. To maintain consistency across all sub-aperture images of the light field, the algorithm operates on 3D stacks (called patch-volumes) of 2D-patches, extracted from the different sub-aperture images. The patches forming the 3D stack are best matches across subaperture images. A dictionary of examples is first constructed by extracting, from a training set of high- and low- resolution light fields, pairs of high- and low-resolution patch-volumes. These patch-volumes are of very high dimension. Nevertheless, they contain a lot of redundant information, hence actually lie on subspaces of lower dimension. The low- and high-resolution patch-volumes of each pair can therefore be projected on their respective low and high-resolution subspaces using e.g. Principal Component Analysis (PCA). The dictionary of pairs of projected patch-volumes (the examples) map locally the relation between the high-resolution patch volumes and their low-resolution (LR) counterparts. A linear mapping function is then learned, using Multivariate Ridge Regression (RR), between the subspaces of the low- and high- resolution patch-volumes. Each overlapping patch-volume of the low-resolution light field can then be super-resolved by a straight application of the learned mapping function (some results in Fig.6).
|

This work is currently being extended on one hand by exploring how deep learning techniques can further benefit the scheme, and on the other hand by considering a hybrid system in which a 2D high resolution image, a priori not aligned with the light field views, can guide the light field super-resolution process.