

Section: Overall Objectives
Presentation
The technologies necessary for the development of pervasive applications are now widely available and accessible for many uses: short/long-range and low energy communications, a broad variety of visible (smart objects) or invisible (sensors and actuators) objects, as well as the democratization of the Internet of Things (IoT). Large areas of our living spaces are now instrumented. The concept of Smart Spaces is about to emerge, based upon both massive and apposite interactions between individuals and their everyday working and living environments: residential housing, public buildings, transportation, etc. The possibilities of new applications are boundless. Many scenarios have been studied in laboratories for many years and, today, a real ability to adapt the environment to the behaviors and needs of users can be demonstrated. However mainstream pervasive applications are barely existent, at the notable exception of the ubiquitous GPS-based navigators. The opportunity of using vast amount of data collected from the physical environments for several application domains is still largely untapped. The applications that interact with users and act according to their environment with a large autonomy are still very specialized. They can only be used in the environment they had especially been developed for (for example "classical" home automation tasks: comfort, entertainment, surveillance). They are difficult to adapt to increasingly complex situations, even though the environments in which they evolve are more open, or change over time (new sensors added, failures, mobility etc.).
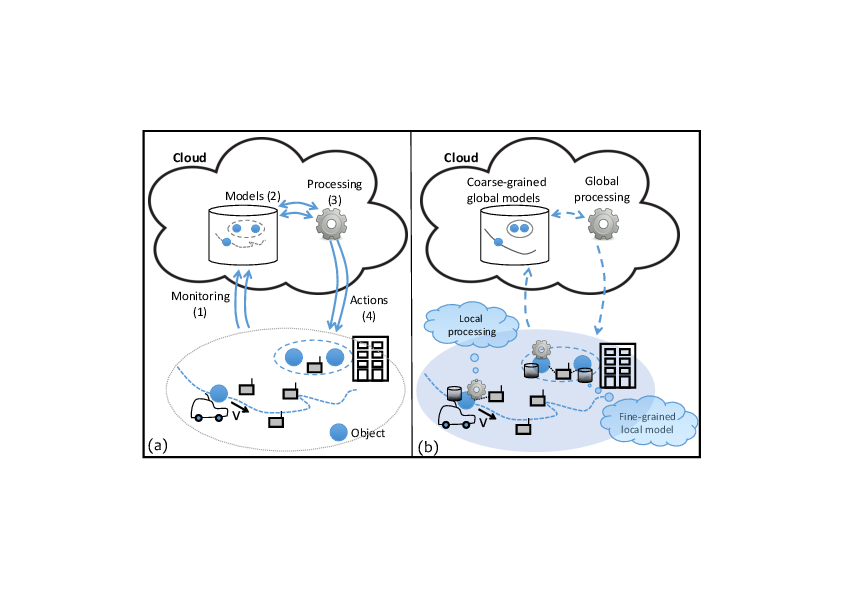
Developing applications and services that are ready to deploy and evolve in different environments should involve significant cost reduction. Unfortunately, designing, testing and ensuring the maintenance as well as the evolution of a pervasive application remain very complex. In our view, the lack of resources by which properties of the real environment are made available to application developers is a major concern. Building a pervasive application involves implementing one or more logical control loops which include four stages (see figure 1-a): (1) data collection in the real environment, (2) the (re)construction of information that is meaningful for the application and (3) for decision making, and finally, (4) action within the environment. While many decision-algorithms have been proposed, the collection and construction of a reliable and relevant perception of the environment and, in return, action mechanisms within the environment still pose major challenges that the Tacoma/Ease project is prepared to deal with.
Most current solutions are based on a massive collection of raw data from the environment, stored on remote servers. Figure 1-a illustrates this type of approach. Exposure of raw sensor values to the decision-making process does not allow to build relevant contexts that a pervasive application actually needs in order to shrewdly act/react to changes in the environment. So, the following is left up to the developer:
-
To characterize more finely raw data beyond its simple value, for example, the acquisition date, the nature of network links crossed to access the sensor, the durability and accuracy of value reading, etc.
-
To exploit this raw data to calculate a relevant abstraction for the application, such as, whether the room is occupied, or whether two objects are in the same physical vicinity.
Traditional software architectures isolate the developer from the real environment that he oftentimes has to depict according to complex, heavy and expensive processes. However, objects and infrastructure integrated into user environments could provide a more suitable support to pervasive applications: description of the actual system's state can be richer, more accurate, and, meanwhile, easier to handle; the applications' structure can be distributed by being built directly into the environment, facilitating scalability and resilience by the processing autonomy; finally, moving processing closer to the edge of the network avoids major problems of data sovereignty and privacy encountered in infrastructures very dependent on the cloud. We strongly believe in the advantages of specific approaches to the fields of edge computing and fog computing, which will reveal themselves with the development of Smart Spaces and an expansive growth of the number of connected objects. Indeed, ensuring the availability and reliability of systems that remain frugal in terms of resources will become in the end a major challenge to be faced in order to allow proximity between processing and end-users. Figure 1-b displays the principle of "using data at the best place for processing". Fine decisions can be made closer to the objects producing and acting on the data, local data characterization and local processing de-emphasize the computing and storage resources of the cloud (which can be used for example to store selected/transformed data for global historical analysis or optimization).
Ease aims at developing a comprehensive set of new interaction models and system architectures to considerably help pervasive application designers in the development phase with the side effect to ease the life cycle management. We follow two main principles:
-
Leveraging local properties and direct interactions between objects, we would be able to enrich and to manage locally data produced in the environment. The application would then be able to build their knowledge about their environment (perception) in order to adjust their behavior (eg. level of automation) to the actual situation.
-
Pervasive applications should be able to describe requirements they have on the quality of their environment perception. We would be able to achieve the minimum quality level adapting the diversity of the sources (data fusion/aggregation), the network mechanisms used to collect the data (network/link level) and the production of the raw data (sensors).