

Section: New Results
Perception and autonomous navigation
Participants : Patrick Rives, Pascal Morin, Andrew Comport, Alexandre Chapoulie, Gabriela Gallegos, Cyril Joly, Maxime Meilland, Glauco Scandaroli.
Indoor SLAM: Self-calibration of the camera frame with respect to the odometry frame
Fusing visual data and odometry information is a standard technique to improve the robustness of the SLAM solution. Odometry data is considered as an input of the motion prediction equation while the visual data constitutes the filter observation. However, such method requires that the system is well calibrated: the pose of the camera frame with respect to the odometry frame has to be known. Usually, this pose is directly obtained by an hand made measurement yielding to incorrect values. We propose a new self calibration method to get these calibration parameters automatically. In practice, the state in the SLAM formulation is augmented with the unknown camera parameters (with respect to the odometry frame). This method requires to adapt a few Jacobians with respect to the original SLAM algorithm which assumes that these parameters are known. The accuracy and the stability of the estimation scheme clearly depends on the observability and the conditioning properties of the new system.
In 2010, we presented results in the case where the camera frame location has only 3 degrees of freedom (two translations and a rotation with respect to the vertical axis). This year, these results were extended to the full calibration problem. As in the previous case, we assume that the robot is moving on a horizontal ground and observes 3D landmarks from the images delivered by the on board camera. The five parameters introduced by the calibration problem - 2 translations and 3 rotations (only 2 translations since the component is not observable due to the planar motion of the robot) - are estimated simultaneously in addition to the "classical" SLAM parameters. The implementation of the algorithm is based on a Smoothing And Mapping (SAM) approach which computes a solution by considering the whole trajectory (instead of only the current pose as with the EKF approach).
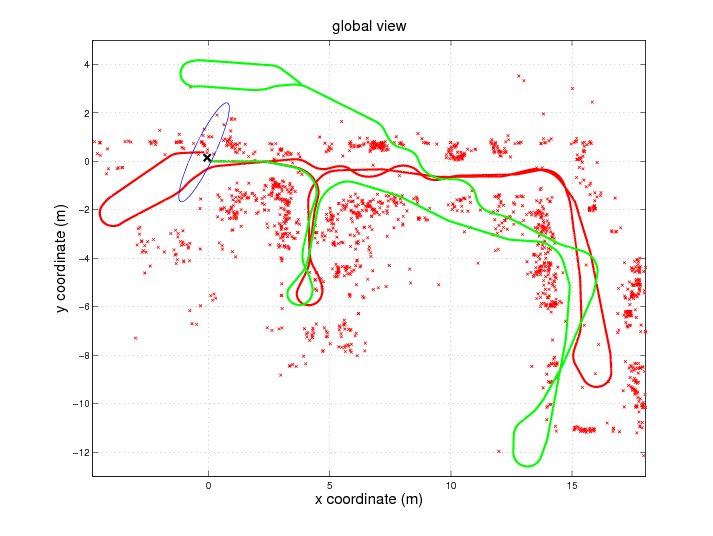
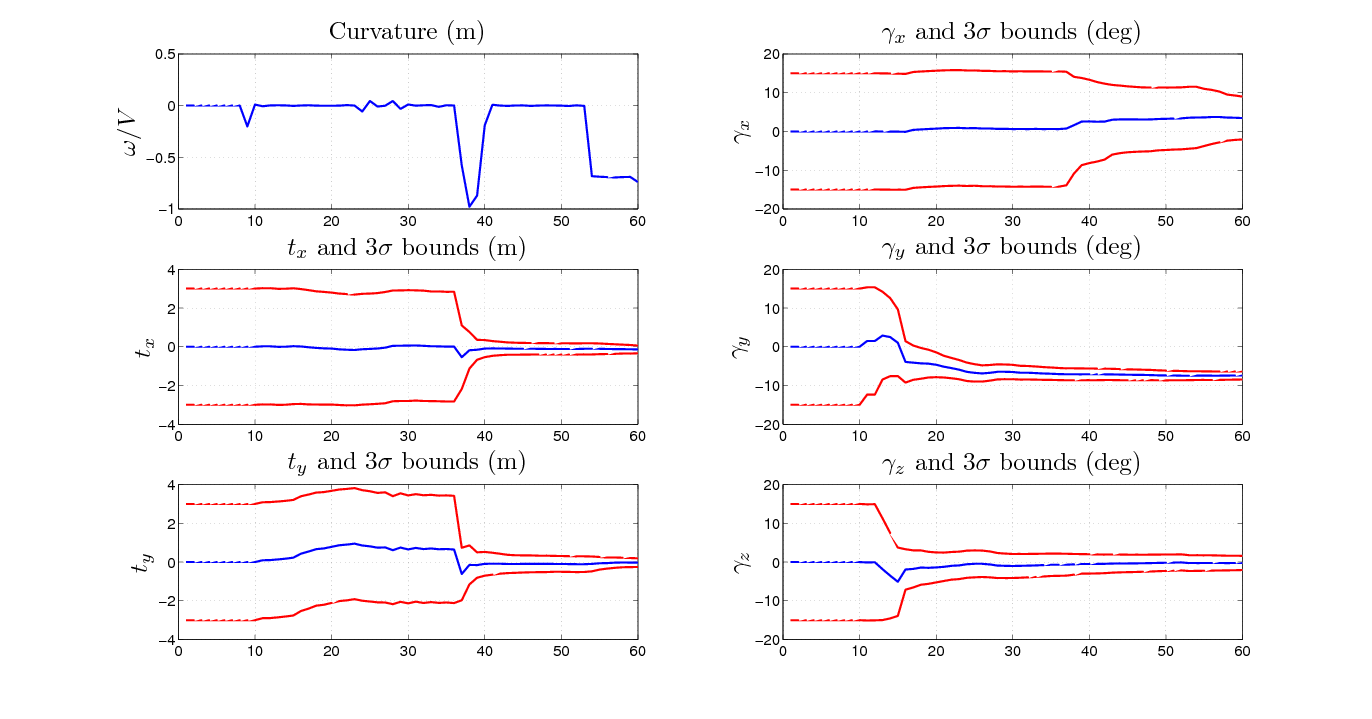
As a theoretical result, we prove that this augmented system remains observable if and only if the curvature of the robot trajectory changes. This analysis was validated on real data with our indoor robot. Fig. 2 shows the mobile platform and the camera. It can be seen that an important rotational offset was added on the camera to test the capability to deal with large rotational values (the parameters are initialized with identity). Results are provided on Fig. 3 -4 and table 1 . They show that the trajectory and the map seem consistent; moreover, the algorithm was able to correct the odometry drift (green trajectory on Fig. 3 ). Then, the observability analysis was validated since the estimation of the camera frame parameters begins when there is a significant change in the radius of curvature of the trajectory (see the confidence bounds on Fig.4 ). Finally, the estimation of these parameters was consistent with the ground truth (table 1 ). These results were presented at IROS'11 conference [30] .
|


|
| Reference | Estimation | 3 bounds | ||
| (m) | -0.16 | -0.149 | ||
| Camera | (m) | -0.35 | -0.38 | |
| param. | (deg) | 6.05 | 6.609 | |
| (deg) | -7.34 | -7.714 | ||
| (deg) | 0 | 0.668 | ||
| Final | (m) | -0.06 | -0.11 | |
| Pose | (m) | 0.15 | 0.56 | |
| (deg) | 0 | -1.18 | ||
Outdoor Visual SLAM
Safe and autonomous navigation in complex outdoor urban-like environment requires a precise and real time localization of the robot. Standard methods, like odometry, typically performed by wheel encoders or inertial sensors, are prone to drift and not reliable for large displacements. Low cost GPS stations are inaccurate and satellite masking effect happens too frequently due to corridor-like configurations. We develop a real time and accurate localization method based on vision only without requiring any additional sensor.
Our approach relies on a monocular camera on board the vehicle and the use of a database of spherical images of the urban scene acquired during an offline phase. This geo-referenced database allows us to obtain a robust “drift free” localization. Basically, the database is constituted of spherical images augmented by depth which are positioned in a GIS (Geographic information system). This spherical robot centered representation accurately represents all necessary information for vision based navigation and mapping ([26] ). During the online navigation, the current vehicle position is computed by aligning the current vehicle camera view with the closest reference sphere extracted from the database.
A spherical augmented acquisition system has been developed and tested on our Cycab vehicle. This system is composed of six wide angle stereo cameras in overlap, which permits to extract depth information by dense correspondence. Since the depth is available, we are able to construct 360 degrees spherical images with a unique center of projection. Those 3D spheres are then used in an image-based spherical odometry algorithm to obtain the trajectory of the vehicle ([31] ), fuse the spheres and construct the database.
During the online navigation, we consider a vehicle equipped with a simple camera (perspective, omnidirectional...). Here the aim is to register the current view on the closest sphere stored in the database. To achieve this we have developed a spherical image-based registration which allows efficient and accurate localization. But since the database of augmented visual spheres can be acquired under different illumination conditions than the online camera is experiencing, a robust algorithm combining model based localization and online visual odometry has been developed [32] . This method performs in real-time (45 Hz), and allows to handle large illumination changes and outliers rejection (see figure 5 ).
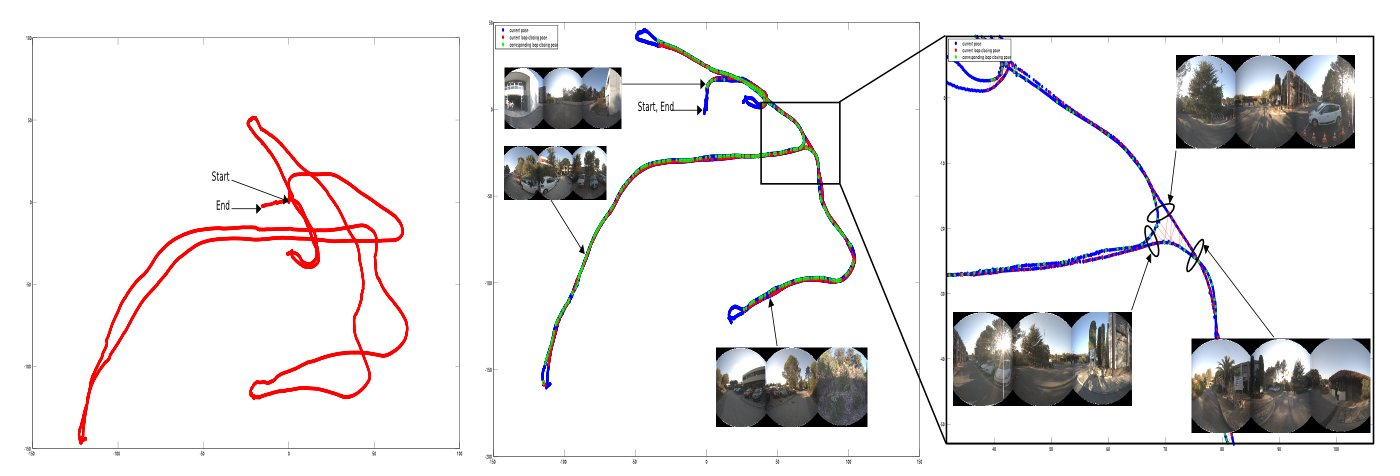
As a part of the ANR CityVIP project, the localization and mapping system has been successfully tested in Clermont Ferrand (France). A database of augmented images has been built along a learning trajectory. The aim was to automatically “replay” the learning trajectory using the database and a monocular camera. To avoid collisions and pedestrians, a laser was mounted on the front of the Cycab. The system was able to autonomously follow large scale trajectories (over 400 meters), in crowded urban environments (see figure 6 ).

Loop closure detection for spherical view based SLAM
Although more precise than the odometry computed from the wheels encoders, the visual odometry also suffers from the problem of drift when large displacements are performed. It is possible to correct this drift if the robot is capable to determine if the the place it is visiting has already been visited. re-observes a scene previously observed. This is often referred as the loop closure detection problem and several methods exist in the literature using perspective cameras. We develop new methods more reliable by exploiting the peculiar properties of spherical cameras.
Standard perspective cameras have a limited field of view leading to an incapability to encompass all the surrounding environment. This limitation of the field of view drastically limits the performances of visual loop closure algorithms. We propose to use spheres of vision computed by mosaicing images from 6 wide angle cameras mounted on a ring. Such a representation offers a full 360 °field of view and keeps the spherical image invariant to the changes in orientations (Figure 7 ).


Loop closure detection can be exploited in a SLAM context at two levels: firstly, in the metric representation to retro-propagate along the robot's trajectory the cumulative errors due to the drift, secondly, in the topological representation, to fusion in the graph representation the nodes corresponding to a same place.
Existing algorithms are not point of view independent: loop closures are detected uniquely when a place is revisited by the robot coming from the same direction but if the robot comes back in a different direction, the algorithms fail. Our solution relies on the presented spherical view and an efficient way of information extraction from it. We extract local information describing the points of interest of the scene. We enhance this local information with a global descriptor characteristic of the distribution of the points of interest over the sphere thereby describing the environment structure. These informations are used to retrieve the already visited places. Our algorithm performs well and is robust to the point of view variation [27] . This has led to an accepted paper at OMNIVIS 2011.
The figure 8 below presents obtained results. The trajectory is corrected (drift reduction) using the loop closure constraint. Red and green dots represent the loop closing places, they are linked by a red line.
Context-based segmentation of scenes
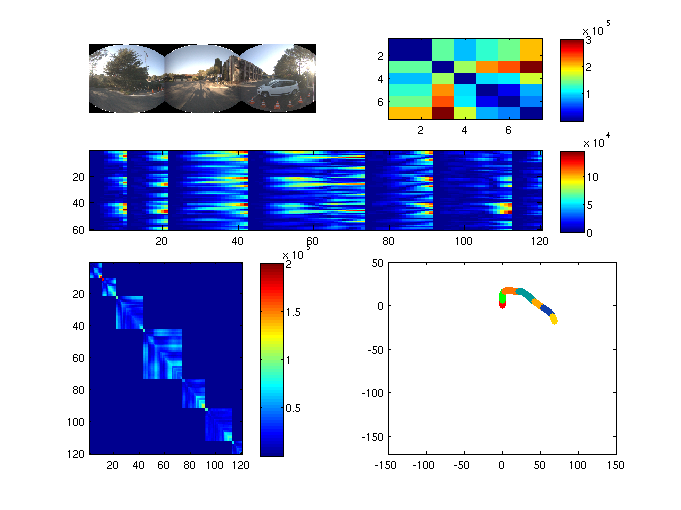
In a topological SLAM framework based on vision, the places are often represented by images gathered at regular time/distance intervals. It is nevertheless a meaningless representation in the context of topology. We would prefer a definition like "in front of a building" or "entrance of the campus" instead of "image number ". Places are thus a set of images we need to group. This is what we call context based segmentation. In order to achieve this segmentation a criterion for "changing place" is needed, we propose to evaluate the environment structure using a global spatial descriptor (computed on the spherical view) called GIST. The algorithm relies on a statistical process control monitoring for an out-of-control signal involving a changing place event. The algorithm still needs to be improved for better robustness on the localization of the changing place events when we come back on previous visited paths.
The figure 9 presents the preliminary results. On the bottom left is the similarity matrix of the images GIST while on the bottom right is the segmented trajectory followed by our robot.
Nonlinear observers for visual-inertial fusion with IMU-bias and camera-to-IMU rotation estimation
This work concerns the fusion of visual and inertial measurements in order to obtain high-frequency and accurate pose estimates of a visual-inertial sensor. While cameras can provide fairly accurate pose (position and orientation) estimates, the data acquisition frequency and signal processing complexity limit the capacities of such sensors in the case of highly dynamic motions. An IMU (Inertial Measurement Unit) can efficiently complement the visual sensor due to its high frequency acquisition, large bandwidth, and easy-to-process signals. IMU biases and calibration errors of the displacement between the camera frame and the IMU frame, however, can severely impair the fusion of visual and inertial data. Identification of these biases and calibration of this displacement can be achieved with dedicated measurement tools, but this requires expensive equipment and it is time consuming. We propose instead to address these issues via the design of observers. Last year, we had proposed a nonlinear observer to fuse pose and IMU measurements while identifying additive IMU biases on both gyrometers and accelerometers. We have extended this work to the self-calibration of the rotation between the pose sensor frame (camera) and the IMU frame. Simulation and experimental results have confirmed that this calibration significantly improves the final pose estimation and allows to process motions with faster dynamics. This work has been presented at the IROS conference in october [35] . It is a joint work with G. Silveira from CTI in Brazil. We are currently extending this result to include the self-calibration of the translation displacement between both sensors.