Section:
New Results
Category-level object and scene recognition
Is object localization for free? – Weakly-supervised learning with convolutional neural networks
Participants :
Maxime Oquab, Leon Bottou [MSR New York] , Ivan Laptev, Josef Sivic.
Figure
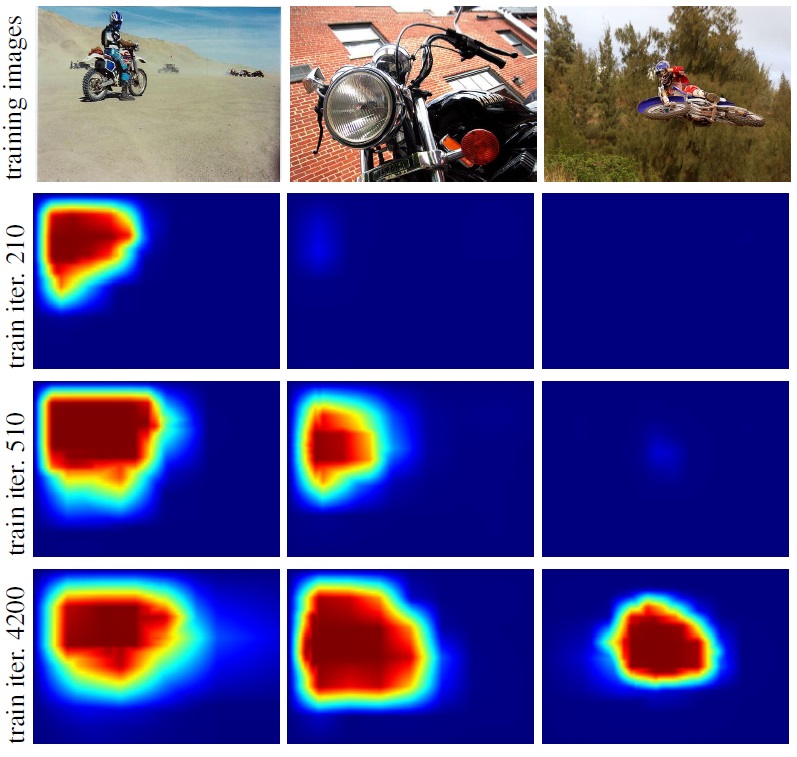
3. Evolution of localization score maps for the motorbike class over iterations of our weakly-supervised CNN training. Note that locations of objects with more usual appearance are discovered earlier during training.
|
|
Figure
4. Example location predictions for images from the Microsoft COCO validation set obtained by our weakly-supervised method. Note that our method does not use object locations at training time, yet can predict locations of objects in test images (yellow crosses). The method outputs the most confident location for most confident object classes.
|
|
Successful methods for visual object recognition typically rely on training datasets containing lots of richly annotated images. Detailed image annotation, e.g. by object bounding boxes, however, is both expensive and often subjective. We describe a weakly supervised convolutional neural network (CNN) for object classification that relies only on image-level labels, yet can learn from cluttered scenes containing multiple objects (see Figure 3 ). We quantify its object classification and object location prediction performance on the Pascal VOC 2012 (20 object classes) and the much larger Microsoft COCO (80 object classes) datasets. We find that the network (i) outputs accurate image-level labels, (ii) predicts approximate locations (but not extents) of objects, and (iii) performs comparably to its fully-supervised counterparts using object bounding box annotation for training. This work has been published at CVPR 2015 [14] . Illustration of localization results by our method in Microsoft COCO dataset is shown in Figure 4 .
Unsupervised Object Discovery and Localization in the Wild: Part-based Matching with Bottom-up Region Proposals
Participants :
Minsu Cho, Suha Kwak, Cordelia Schmid, Jean Ponce.
In [8] , we address unsupervised discovery and localization of
dominant objects from a noisy image collection of multiple object
classes. The setting of this problem is fully unsupervised (Fig. 5 ), without
even image-level annotations or any assumption of a single dominant
class. This is significantly more general than typical
colocalization, cosegmentation, or weakly-supervised localization tasks.
We tackle the unsupervised discovery and localization problem using a
part-based region matching approach: We use off-the-shelf region
proposals to form a set of candidate bounding boxes for objects and
object parts. These regions are efficiently matched across images
using a probabilistic Hough transform that evaluates the confidence for
each candidate correspondence considering both appearance similarity and spatial
consistency.
Dominant objects are discovered and localized by comparing the scores of candidate regions
and selecting those that stand out over other regions containing them.
Extensive evaluations on standard benchmarks (e.g., Object Discovery and PASCAL VOC 2007 datasets)
demonstrate that the proposed approach significantly outperforms the current state of the art in
colocalization, and achieves robust object discovery even in a fully unsupervised setting. This work has been published in CVPR 2015 [8] as oral presentation.
Figure
5. Unsupervised object discovery in the wild. We tackle object localization in an unsupervised scenario without any type of annotations, where a given image collection may contain multiple dominant object classes and even outlier images. The proposed method discovers object instances (red bounding boxes) with their distinctive parts (smaller boxes).
|
|
Unsupervised Object Discovery and Tracking in Video Collections
Participants :
Suha Kwak, Minsu Cho, Ivan Laptev, Jean Ponce, Cordelia Schmid.
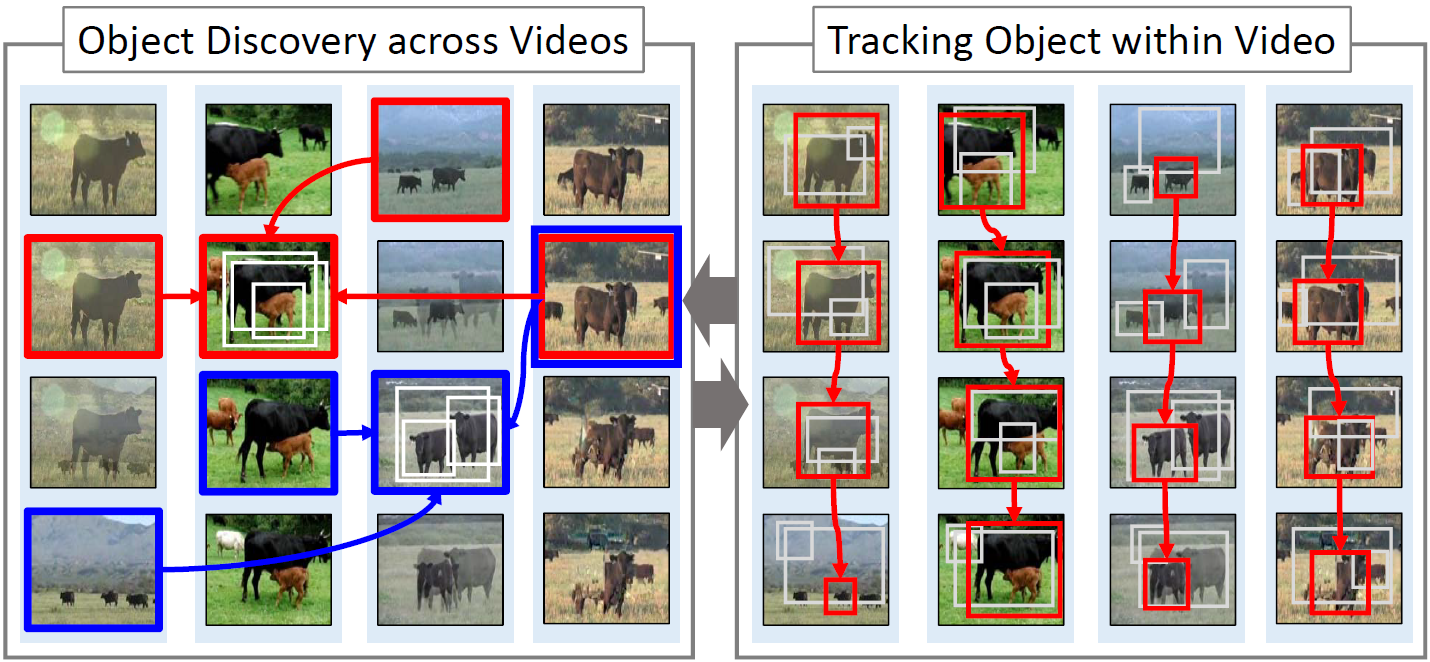
In [11] , we address the problem of automatically localizing dominant objects as spatio-temporal tubes in a noisy collection of videos with minimal or even no supervision. We formulate the problem as a combination of two complementary processes: discovery and tracking (Figure 6 ). The first one establishes correspondences bet ween prominent regions across videos, and the second one associates similar object regions within the same video. It is empirically demonstrated that our method can handle video collections featuring multiple object classes, and substantially outperforms the state of the art in colocalization, even though it tackles a broader problem with much less supervision. This work has been published in ICCV 2015.
Figure
6. Dominant objects in a video collection are discovered by analyzing correspondences between prominent regions across videos (left). Within each video, object candidates, discovered by the former process, are temporally associated and a smooth spatio-temporal localization is estimated (right). These processes are alternated until convergence or up to a fixed number of iterations.
|
|
Linking Past to Present: Discovering Style in Two Centuries of Architecture
Participants :
Stefan Lee, Nicolas Maisonneuve, David Crandall, Alexei A. Efros, Josef Sivic.
With vast quantities of imagery now available online, researchers
have begun to explore whether visual patterns
can be discovered automatically. Here we consider the
particular domain of architecture, using huge collections
of street-level imagery to find visual patterns that correspond
to semantic-level architectural elements distinctive
to particular time periods. We use this analysis both to
date buildings, as well as to discover how functionally similar
architectural elements (e.g. windows, doors, balconies,
etc.) have changed over time due to evolving styles.
We validate the methods by combining a large dataset of
nearly 150,000 Google Street View images from Paris with
a cadastre map to infer approximate construction date for
each facade. Not only could our analysis be used for dating
or geo-localizing buildings based on architectural features,
but it also could give architects and historians new tools for
confirming known theories or even discovering new ones.
The work was published in [13] and the
results are illustrated in figure 7 .
Figure
7. Using thousands of Street View images aligned
to a cadastral map, we automatically find visual elements
distinctive to particular architectural periods. For example,
the patch in white above was found to be distinctive to the
Haussmann period (late 1800’s) in Paris, while the heat map
(inset) reveals that the ornate balcony supports are the most
distinctive features. We can also find functionally-similar
elements fromthe same and different time periods (bottom).
|
|
Proposal Flow
Participants :
Bumsub Ham, Minsu Cho, Cordelia Schmid, Jean Ponce.
Finding image correspondences remains a challenging problem in the presence of intra-class variations and large changes in scene layout, typical in scene flow computation. In [22] , we introduce a novel approach to this problem, dubbed proposal flow, that establishes reliable correspondences using object proposals. Unlike prevailing scene flow approaches that operate on pixels or regularly sampled local regions, proposal flow benefits from the characteristics of modern object proposals, that exhibit high repeatability at multiple scales, and can take advantage of both local and geometric consistency constraints among proposals. We also show that proposal flow can effectively be transformed into a conventional dense flow field. We introduce a new dataset that can be used to evaluate both general scene flow techniques and region-based approaches such as proposal flow. We use this benchmark to compare different matching algorithms, object proposals, and region features within proposal flow with the state of the art in scene flow. This comparison, along with experiments on standard datasets, demonstrates that proposal flow significantly outperforms existing scene flow methods in various settings. This work is under review. The proposed method and its qualitative result are illustrated in Figure 8 .
Figure
8. Proposal flow generates a reliable scene flow between similar images by establishing geometrically consistent correspondences between object proposals. (Left) Region-based scene flow by matching object proposals. (Right) Color-coded dense flow field generated from the region matches, and image warping using the flow.
|
|