

Section: Overall Objectives
General Presentation
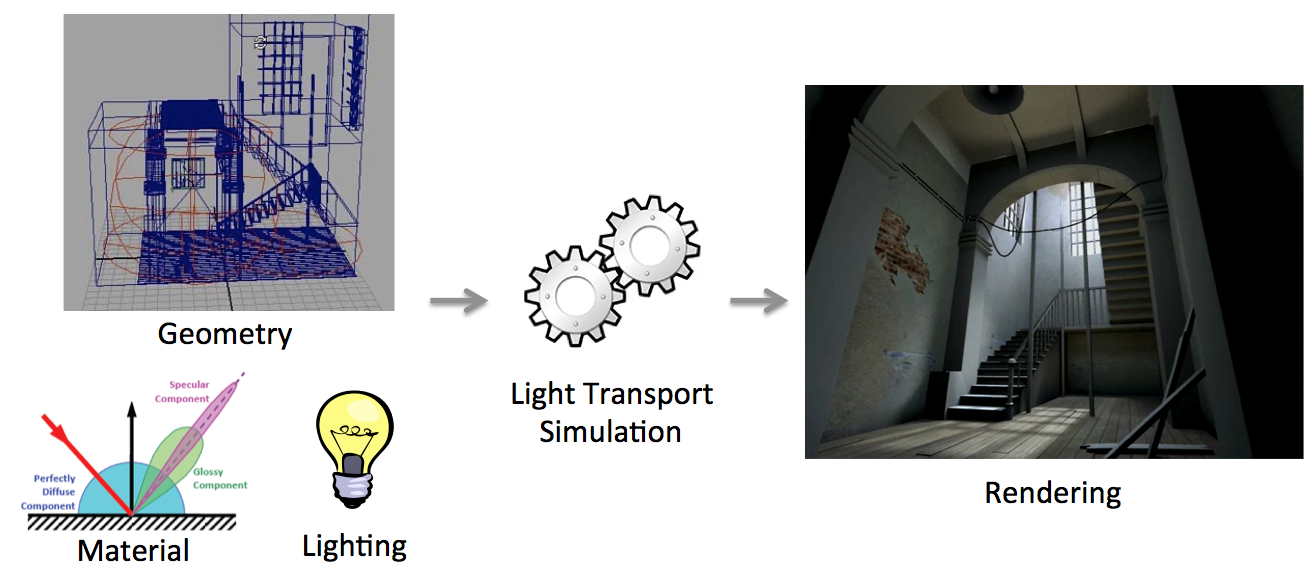
In traditional Computer Graphics (CG) input is accurately modeled by hand by artists. The artists first create the 3D geometry – i.e., the polygons and surfaces used to represent the 3D scene. They then need to assign colors, textures and more generally material properties to each piece of geometry in the scene. Finally they also define the position, type and intensity of the lights. This modeling process is illustrated schematically in Fig. 1(left)). Creating all this 3D content involves a high level of training and skills, and is reserved to a small minority of expert modelers. This tedious process is a significant distraction for creative exploration, during which artists and designers are primarily interested in obtaining compelling imagery and prototypes rather than in accurately specifying all the ingredients listed above. Designers also often want to explore many variations of a concept, which requires them to repeat the above steps multiple times.
Once the 3D elements are in place, a rendering algorithm is employed to generate a shaded, realistic image (Fig. 1(right)). Costly rendering algorithms are then required to simulate light transport (or global illumination) from the light sources to the camera, accounting for the complex interactions between light and materials and the visibility between objects. Such rendering algorithms only provide meaningful results if the input has been accurately modeled and is complete, which is prohibitive as discussed above.
A major recent development is that many alternative sources of 3D content are becoming available. Cheap depth sensors allow anyone to capture real objects but the resulting 3D models are often uncertain, since the reconstruction can be inaccurate and is most often incomplete. There have also been significant advances in casual content creation, e.g., sketch-based modeling tools. The resulting models are often approximate since people rarely draw accurate perspective and proportions. These models also often lack details, which can be seen as a form of uncertainty since a variety of refined models could correspond to the rough one. Finally, in recent years we have witnessed the emergence of new usage of 3D content for rapid prototyping, which aims at accelerating the transition from rough ideas to physical artifacts.
The inability to handle uncertainty in the data is a major shortcoming of CG today as it prevents the direct use of cheap and casual sources of 3D content for the design and rendering of high-quality images. The abundance and ease of access to inaccurate, incomplete and heterogeneous 3D content imposes the need to rethink the foundations of 3D computer graphics to allow uncertainty to be treated in inherent manner in Computer Graphics, from design all the way to rendering and prototyping.
The technological shifts we mention above, together with developments in computer vision, user-friendly sketch-based modeling, online tutorials, but also image, video and 3D model repositories and 3D printing represent a great opportunity for new imaging methods. There are several significant challenges to overcome before such visual content can become widely accessible.
In GraphDeco, we have identified two major scientific challenges of our field which we will address:
-
First, the design pipeline needs to be revisited to explicitly account for the variability and uncertainty of a concept and its representations, from early sketches to 3D models and prototypes. Professional practice also needs to be adapted and facilitated to be accessible to all.
-
Second, a new approach is required to develop computer graphics models and algorithms capable of handling uncertain and heterogeneous data as well as traditional synthetic content.
We next describe the context of our proposed research for these two challenges. Both directions address hetereogeneous and uncertain input and (in some cases) output, and build on a set of common methodological tools.