Section: Overall Objectives
General strategy
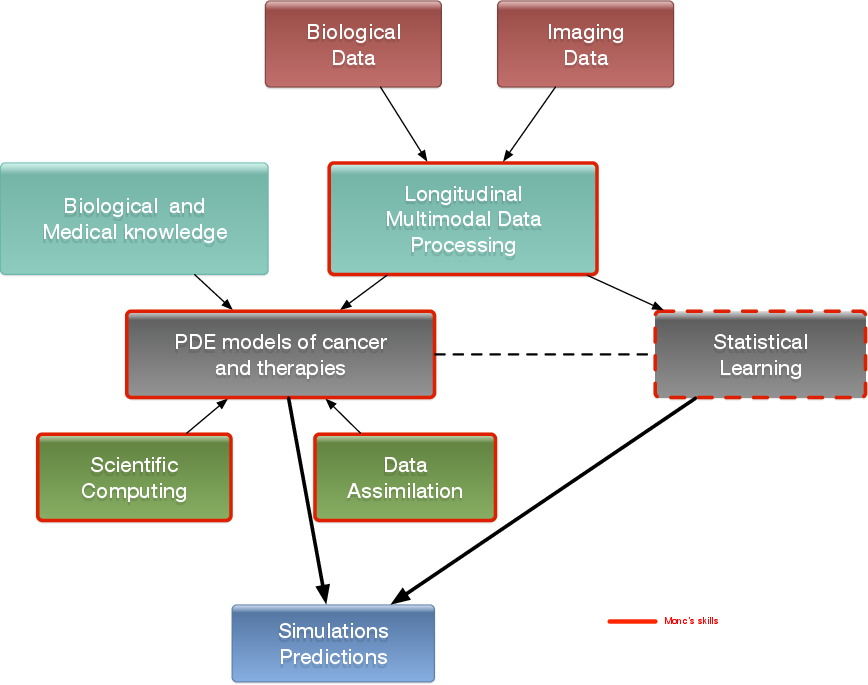
Our general strategy may be described with the following sequence:
-
Stage 1: Derivation of mechanistic models based on the biological knowledge and the available observations. The construction of such models relies on the up-to-date biological knowledge at the cellular level including description of the cell-cycle, interaction with the microenvironement (angiogenesis, interaction with the stroma). Such models also include a "macroscopic" description of specific molecular pathways that are known to have a critical role in carcinogenesis or that are targeted by new drugs. We emphasize that for this purpose, close interactions with biologists are crucial. Lots of works devoted to modeling at the cellular level are available in the literature. However, in order to be able to use these models in a clinical context, the tumor is also to be described at the tissue level. The in vitro mechanical characterization of tumor tissues has been widely studied. Yet no description that could be patient specific or even tumor specific is available. It is therefore necessary to build adapted phenomenological models, according to the biological and clinical reality.
-
Stage 2: Data collection. In the clinical context, data may come from medical imaging (MRI, CT-Scan, PET scan) at different time points. We need longitudinal data in time in order to be able to understand or describe the evolution of the disease. Data may also be obtained from analyses of blood samples, biopsies or other quantitative biomarkers. A close collaboration with clinicians is required for selecting the specific cases to focus on, the understanding of the key points and data, the classification of the grades of the tumors, the understanding of the treatment,...In the preclinical context, data may for instance be macroscopic measurements of the tumor volume for subcutaneous cases, green fluorescence protein (GFP) quantifications for total number of living cells, non-invasive bioluminescence signals or even imaging obtained with devices adapted to small animals.
-
Data processing: Besides selection of representative cases by our collaborators, most of the time, data has to be processed before being used in our models. We develop novel methods for semi-automatic (implemented in SegmentIt) as well as supervized approaches (machine learning or deep learning) for segmentation, non-rigid registration and extraction of image texture information (radiomics, deep learning).
-
-
Stage 3: Adaptation of the model to data. The model has to be adapted to data: it is useless to have a model considering many biological features of the disease if it cannot be reliably parameterized with available data. For example, very detailed descriptions of the angiogenesis process found in the literature cannot be used, as they have too much parameters to determine for the information available. A pragmatic approach has to be developed for this purpose. On the other hand, one has to try to model any element that can be useful to exploit the image. Parameterizing must be performed carefully in order to achieve an optimal trade-off between the accuracy of the model, its complexity, identifiability and predictive power. Parameter estimation is a critical issue in mathematical biology: if there are too many parameters, it will be impossible to estimate them but if the model is too simple, it will be too far from reality.
-
Stage 4: Data assimilation. Because of data complexity and scarcity - for example multimodal, longitudinal medical imaging - data assimilation is a major challenge. Such a process is a combination of methods for solving inverse problems and statistical methods including machine learning strategies.
-
Personalized models: Currently, most of the inverse problems developed in the team are solved using a gradient method coupled with some MCMC type algorithm. We are now trying to use more efficient methods as Kalman type filters or so-called Luenberger filter (nudging). Using sequential methods could also simplify Stage 3 because they can be used even with complex models. Of course, the strategy used by the team depends on the quantity and the quality of data. It is not the same if we have an homogeneous population of cases or if it is a very specific isolated case.
-
Statistical learning: In some clinical cases, there is no longitudinal data available to build a mathematical model describing the evolution of the disease. In these cases (e.g. in our collaboration with Humanitas Research Hospital on low grade gliomas or Institut Bergonié on soft-tissue sarcoma), we use machine learning techniques to correlate clinical and imaging features with clinical outcome of patients (radiomics). When longitudinal data and a sufficient number of patients are available, we combine this approach and mathematical modeling by adding the personalized model parameters for each patient as features in the statistical algorithm. Our goal is then to have a better description of the evolution of the disease over time (as compared to only taking temporal variations of features into account as in delta-radiomics approaches). We also plan to use statistical algorithms to build reduced-order models, more efficient to run or calibrate than the original models.
-
Data assimilation of gene expression. "Omics" data become more and more important in oncology and we aim at developing our models using this information as well. For example, in our work on GIST, we have taken the effect of a Ckit mutation on resistance to treatment into account. However, it is still not clear how to use in general gene expression data in our macroscopic models, and particularly how to connect the genotype to the phenotype and the macroscopic growth. We expect to use statistical learning techniques on populations of patients in order to move towards this direction, but we emphasize that this task is very prospective and is a scientific challenge in itself.
-
-
Stage 5: Patient-specific Simulation and prediction, Stratification. Once the mechanistic models have been parametrized, they can be used to run patient-specific simulations and predictions. The statistical models offer new stratifications of patients (i.t. an algorithm that tells from images and clinical information wheter a patient with soft-tissue sarcoma is more likely to be a good or bad responder to neoadjuvant chemotherapy). Building robust algorithms (e.g. that can be deployed over multiple clinical centers) also requires working on quantifying uncertainties.