
Keywords
Computer Science and Digital Science
- A3.1. Data
- A3.2. Knowledge
- A3.3.2. Data mining
- A3.3.3. Big data analysis
- A3.4. Machine learning and statistics
- A6.1. Methods in mathematical modeling
- A6.2. Scientific computing, Numerical Analysis & Optimization
- A8.2. Optimization
- A9.8. Reasoning
Other Research Topics and Application Domains
- B1.1.7. Bioinformatics
- B1.1.10. Systems and synthetic biology
- B3. Environment and planet
1 Team members, visitors, external collaborators
Research Scientists
- David Sherman [Team leader, INRIA, Senior Researcher, HDR]
- Alain Franc [INRAE, Emeritus, HDR]
- Clémence Frioux [INRIA, Researcher]
- Simon Labarthe [INRAE, Researcher]
Post-Doctoral Fellow
- Pablo Andres Ugalde Salas [INRIA]
PhD Students
- Mohamed Anwar Abouabdallah [INRIA]
- Chabname Ghassemi Nedjad [UNIV BORDEAUX, from Oct 2022]
- Maxime Lecomte [INRAE]
Technical Staff
- Ariane Badoual [INRIA, until May 2022]
- Jean-Marc Frigerio [INRAE, Engineer]
- Coralie Muller [INRIA, Engineer, from Feb 2022]
- Franck Salin [INRAE, Engineer]
Interns and Apprentices
- Leonard Brindel [INRIA, Apprentice, from Sep 2022]
- Quentin Chapuzet [INRIA, from Feb 2022 until Jul 2022]
- Chabname Ghassemi Nedjad [INRIA, from Feb 2022 until Jul 2022]
- Arie Wortsman Zurich [INRIA, from Apr 2022 until Jul 2022]
Administrative Assistant
- Catherine Cattaert Megrat [INRIA]
Visiting Scientist
- Sebastien Raguideau [EARLHAM INSTITUTE, from Nov 2022 until Nov 2022]
2 Overall objectives
The simplest ecosystem is a complex network of interactions between a diversity of organisms providing a diversity of functions. Each organism is the result of evolutionary processes driven by the creation then the selection of molecular diversity. Every function is a coordinated cascade of biochemical reactions, sensitive to substrate and environment, arising to adapt to the needs of the organism. Pleiade explores the diversity of organisms and the diversity of their functions and, as a fundamental challenge, seeks to formalize the links between them.
Pleiade measures the diversity of organisms by comparing DNA sequences and describes it using geometric methods. Amplicon sequences from metabarcoding are compared systematically to produce matrices of taxonomic distances. Mathematical analysis of these distance matrices, made possible by advances in dimension reduction, pattern recognition, and high-performance computing, reveals complex descriptions of the molecular diversity of the organisms in the sampled environment.
Pleiade examines the diversity of functions performed by these organisms by identifying the genes responsible for biochemical processes and grouping them into metabolic networks. Annotation of whole genome and metagenomic sequences allows us to delineate the functions provided by individual organisms and describe the interactions between them. Metabolic and process-based models are developed as compact descriptions of functional diversity. In addition to providing a means to simulate a system, a model is a syntactic object that symbolically represents a range of functional behaviors; patterns in the diversity of the encoded functions can be explored inferentially without exhaustively simulating the model to enumerate the set of behaviors it represents.
Comparison of annotated genomes and their associated metabolic networks reveals how functions arose over time: what functions, when they arose, and by which evolutionary mechanisms. Annotation is not performed on genomes individually, but comparatively, taking into account the similarities and differences between related species and strains.
A further challenge, developed recently, is considering the challenge of linking diversity and function in the particular context of microbial communities. We are developing a synergistic, iterative combination of a community-based strategy for deciphering the diversity in cultures and environmental samples, through metagenomic and metabolomic analysis of functional diversity and metabarcoding analysis of taxonomic diversity; and a function-based strategy for constructing digital twins of natural or designed communities through numerical models. The goal is a hybrid framework for studying systems dynamics using spatio-temporal models.
Shared methodologies needed to scale up to the complexity of biological systems, include high-performance computing (HPC); machine learning, including clustering, meta-modeling and classification for knowledge engineering; machine reasoning, specifically logical and rule-based methods used for model inference and network analysis. Logicial methods in particular promote explainable inference, since the rules are expressed in biological terms and are auditable by biologists, independently from the combinatorial and heuristic optimization techniques used to apply the rules.
Pleiade maintains strong collaborative relations with experimental biologists, and is committed to developing applications in ecology, evolution, biotechnology, and health. Team resources are dedicated to facilitating the adoption of our research by non specialist users, through development of reusable software, integration in HPC frameworks, improvement of web-based environments, and deployment of Jupyter, Galaxy, and Kubernetes interfaces.
3 Research program
Pleiade's mutually reinforcing strengths are a stable foundation of ecology and comparative genomics, and a novel synthesis of new methods extending our reach into microbial and planktonic communities and their dynamics. Our shared aim is to develop both: new challenges in microbial or planktonic communities leverage our solid expertise in foundational methods, and at the same time define new challenges for improving those foundations. We focus on reinforcing of a first set of disciplinary activities related to innovations in methods, be they in applied mathematics or in computer sciences, and a second set of interdisciplinary activities, to build advantageous assemblies of methods for understanding and managing biological systems of interest.
3.1 Research: A Geometric View of Diversity
Data analysis algorithms and tools must be revisited and scaled up. We mobilize both distributed algorithms and new algorithms, like random projection or column selection methods, to build point clouds in Euclidean spaces from massive data sets, and thus overcome the cubic complexity of computation of eigenvectors and eigenvalues of very large dense matrices. We also link distance geometry 56 with convex optimization procedures through matrix completion 40, 43.
Intercalibration: There is a considerable difference between supervised and unsupervised clustering: in supervised clustering, the result for an item is independent from the result for an item , whereas in unsupervised clustering, the result for an item (e.g. the cluster it belongs to, and its composition) depends on nearby items . Which means that the result may change if some items are added to or subtracted from the sample. This raises the more global problem of how to merge two studies to yield a more comprehensive view of biodiversity?
See 48 for some of our recent work linking the distance geometry problem, nonlinear mapping, and weighted least-squares scaling.
Project-team positioning
This research topic is about metabarcoding, i.e. producing inventories through classification, or producing OTUs with clustering, as elementary bricks for diversity, in a way analgous to the role that species play in morphological or molecular based taxonomy. The number of reads produced by NGS facilities is a challenge for bioinformatics and data analysis downstream into these directions: most algorithms scale with the square or the cube of the number of involved reads, which are counted in the millions. Most approaches look for heuristics permitting to produce result within a reasonable time (see e.g. UCLUST or USEARCH as wrappers for many solutions). The Pleiade team has explored another path: relying on HPC (the possibilities of which are underestimated in the community of diversity studies) to derive exact algorithms without heuristics, for computing distances between reads and to analyse distance matrices with dimension reduction.
This has been made possible due to an involvement in scientific computing, associating algorithms, their implemntation and optimisation. Such a bridge between scientific computing and characterisation of the biodiversity is original and still an exploratory field. It is develped in collaboration with project teams HiePACS, Storm and Tadaam in Inria Bordeaux, through two technology development actions: one, ADT Gordon, which is currently being valorized by the redaction of an article, and the second, Diodon, under development.
Collaborations
- In collaboration with the Pasteur Institute in Cayenne and the INRA MIA Research Team in Toulouse, Pleiade is developing a stochastic model for simulation of metacommunities, in the framework of patch occupancy models. The objective is a better understanding of zoonose propagation, namely rabies through bat hosts in connection with disturbances of pristine forests in French Guiana, which have an impact on the exposure of human populations to wildlife that act as reservoirs of zoonoses.
- We have co-supervised with Anne Lavergne (Institut Pasteur de Guyane) a PhD student at IPG and University of Cayenne (Sourakhata Tirera, defense on December 17, 2021) on the drivers of the diversity of viromes of rodents and birds. One part is about bioinformatics in order to select viral fragment, which are a minority in shotgun sequencing of viromes, and a second part is about disentangling the role of the habitat and of the phylogeny of the host in viral diversity. This has led to manuscript 64. A second one is in preparation to make available a new pipeline for dechimerisation of contings after shotgun sequencing and de nova assembly of reads into contigs (a process which is known to create many chimera).
- The Laboratory of excellence (Labex) CEBA promotes innovation in research on tropical biodiversity. It brings together a network of internationally-recognized French research teams, contributes to university education, and encourages scientific collaboration with South American countries. Pleiade has participated in three current international projects funded by CEBA:
- MicroBIOMES: Microbial Biodiversities
- Neutrophyl: Inferring the drivers of Neotropical diversification
- Phyloguianas: Biogeography and pace of diversification in the Guiana Shield
- We collaborate with Institut Pasteur de Guyane at Cayenne for developing the domain of so-called Ecoviromics for some zoonoses in French Guiana. On top of co-supervizing a PhD student at IPG in Cayenne as mentioned above (deciphering the respective roles of host phylogeny and environmental variables in the virome of different hosts (bats, rodents, birds), this collaboration has led to a participation in a synthesis paper on Ecology, evolution, and epidemiology of zoonotic and vector-borne infectious diseases in French Guiana 63.
3.2 Research: Community-scale Metabolic and Omics-based Modeling
Metabolism can be abstracted into sets of metabolic reactions, associated to the genome through gene-protein relationships, and connecting substrates to products thereby forming metabolic networks. Genome-scale metabolic networks (GSMNs) contain all the reactions predicted to occur in a organism according to its genomic contents. Combined with additional knowledge on the system, possibly other –omics data and mathematical models, GSMNs are used to predict the behaviour of an organism or a community of organisms.
A widely-used mathematical formalism for modeling GSMNs is constraint-based modeling, among which flux balance analysis (FBA) is the main representative 58. Such methods permit a quantitative prediction of activity fluxes in metabolic networks while optimising an objective function and assuming steady-state of the system.
The emergent metabolism of microbial communities can also be qualitatively modeled using a boolean approximation of metabolic dynamics7. In this approach the behavior of the system is described by logical rules that activate a given reaction as soon as its substrates become available; numerical parameters such as stochiometry or enzyme kinetics are ignored in favor of graph topology and paths. The advantage is that such qualitative models, unlike quantitative methods such as FBA, do not require the assumption that the system is at steady-state and can model systems where cells are constantly growing or constantly reproducing.
Network expansion, introduced in 47 as a recursive traversal of the structure of a metabolic graph, lends itself to concise definition using answer set programming (ASP) 54 and thus to efficient implementation using SAT solvers 53. In practice, using ASP for metabolic modeling makes it possible to define both the activation of metabolic reactions in different conditions, and the constraints and optimizations needed to find solutions in a combinatorically large state space.
We focus in particular on the key question of determining minimal communities, subsets of the organisms present in an environment that are sufficient to reproduce a chosen behavior 50. The methodological goal here is to identify key species in a community through use of ASP to rapidly explore the search space and thus, through heuristic resolution of combinatorial problems, provide the guarantees an exhaustive search with a greatly reduced computational cost 4.
Functional and taxonomic diversities, beyond intrinsic specificities encoded in the genetic material, are also strongly shaped by their environment. Spatial nutritional niches, microbial interactions and abiotic constraints lead to complex spatial structures in the microbial community that impact its overall dynamics. PDE-based models of the microbiota in its environment allow including in the model these multiple mechanisms in order to decipher their influence on the community faith.
The main methodological developments in this area are related to mathematical modeling (in particular the correct level of simplification in the multi-physics description of the microbial environment), model simplification (asymptotic approximation), inference from multi-omics data (including dimension reduction, statistical learning) and numerical developments (in particular fast approximation of metabolic models with machine learning methods). Strong interactions with community-scale metabolic models are sought, specially for multi-omics inference and knowledge-based machine learning constraints.
The goal is to achieve accurate models of microbial communities that could be used as digital twins of controlled experiments in microbial ecology. Culturomic facilities allow for the acquisition of multi-omics time-series data in controlled conditions, which can be used to build and fit population dynamics models, and can be used in turn to explore numerically biological assumptions and to help in experimental planning and data analysis.
Project-team positioning
The team has expertise in the state of the art methods for metabolic modeling and in metabolic network reconstruction through earlier works 50, 51, 38, 59. The team also masters ODE or PDE microbial population dynamics models including their complex environment 42, 55 and parameter inference with experimental data 17. We work with international or national teams (see below) for combinatorial problem solving (University of Potsdam, Germany), computational biology for health (Quadram Institute Bioscience, UK) and biological applications (Roscoff Biological Station, INRAE teams).
Other international teams working on the subject of community metabolic modeling include but is not restricted to the research groups of: Ines Thiele (U. Galway, Ireland), Kiran Patil (U. Cambridge, UK), Karoline Faust (U. Leuven, Belgium), Daniel Machado (Norwegian University of Science and Technology).
Among Inria project-teams, Dyliss (Rennes) is the one with the closest research themes. Clémence Frioux did her PhD in this team (2015-2018) and stayed for an additional 6 months after the defense. As a result, the majority of her past contributions were done in collaboration with Dyliss members, and current collaborations persist through co-development and maintenance of software, applications etc.
Collaborations
- Quadram Institute Bioscience and Earlham Institute: meta-analyses of metagenomic cohorts for the human gut microbiota.
- University of Potsdam: answer set programming and combinatorial problem solving.
- Station Biologique de Roscoff: algae applications.
- INRAE BFP, STLO, MaIAGE, SAVE, Micalis, IEES: applications and methodological development in computational biology and mathematics.
- CEA. Bio-inspired digital sensors in the framework of the Pherosensor project.
- U. Besançon and U. Orléans. Modeling of the fluidic environment in the gut microbiota.
- U. Paris-Saclay/U.Evry. Machine learning with ANOVA-RKHS.
- Inria Bretagne Atlantique: systems biology and systems ecology.
- Ysopia Bioscience by means of an Inria Tech contract focused the analysis of metagenomic data and the connection to the metabolic screening provided by Metage2Metabo.
- Biomathematica through a CIFRE PhD hosted at MaIAGE (INRAe) co-supervised by Pleiade.
3.3 Research: Bioinformatics, Genomes, and Knowledge Management
The heterogenous data generated in computational molecular biology and ecology are distinguished not only by their volume, but by the richness of the many levels of interpretation that biologists create. The same nucleic acid sequence can be seen as a molecule with a structure, a sequence of base pairs, a collection of genes, an allele, or a molecular fingerprint. To extract the maximum benefit from this treasure trove we must organize the knowledge in ways that facilitate extraction, analysis, and inference. Our focus has been on the efficient representation of relations between biological objects and operations on those representations, in particular heuristic analyses and logical inference.
Pleiade developes applications in comparative genomics of related organisms, using novel mathematical tools for representing compactly, at different scales of difference, comparisons between related genomes. New methods based on distance geometry will refine these comparisons. Compact representations can be stored, exchanged, and combined. They form the basis of novel simultaneous genome annotation methods, that can be linked directly to abductive inference methods for building functional models of the organisms and their communities.
Since a goal of Pleiade is to integrate diversity throughout the analysis process, it is necessary to incorporate diversity as a form of knowledge that can be stored in a knowledge base. Diversity can be represented using various compact representations, such as trees and quotient graphs storing nested sets of relations. Extracting structured representations and logical relations from integrated knowledge bases requires domain-specific query methods that can express forms of diversity.
Project-team positioning
Historically, Pleiade members have been pioneers in the development of large-scale eukaryote comparative genomics. We were involved since the late 1990's in the first genome sequencing of eukaryote microorganisms, co-authored 8 articles in the 37 special issue presenting the first large-scale comparative genomics study, and were in the first authors of the landmark Nature article 46 comparing five complete annotated genomes. Our articles in comparative genomics, particularly of the hemiascomycetous yeasts of biotechnological interest, have achieved thousands of citations and continue to do so decades later. A principle that we fought for 45, 62, that comparative genomics must be based on a systematic and mathematical comparison of the genomes, rather than on an opportunistic one-against-all comparison to the model organism du jour, is now considered standard practice. We also originally set the standard for web-based tools for comparative genomics, organized around the principle of an interaction design based on the questions asked by by biological user, rather than based on the organization of the underlying database as seen by a computer scientist 61, 62. Pleiade capitalized on this experience in support of the research efforts describe above, and also through a wide network of collaborators in the biological sciences. Our current work applies the principles of comparative genomics to a series of smaller projects focused on collections of genomes of biotechnological or of health-related interest.
Collaborations
- Institut des Sciences du Vigne et du Vin (ISVV), U. Bordeaux
- Vitapalm (LEAP-Agri)
- Laboratoire de Microbiologie Fondamentale et Pathogénicité (LMFP), UMR 5234 CNRS U. Bordeaux
- Laboratory of Membrane Biology (LBM) UMR 5200 CNRS U. Bordeaux
4 Application domains
4.1 Molecular based systematics and taxonomy
Defining and recognizing the myriads of species occuring in the biosphere has been the focus of phenomenal energy over the past centuries and remains a major goal of Natural History. It is an iconic paradigm in pattern recognition (clustering has coevolved with numerical taxonomy many decades ago). Developments in evolution and molecular biology, as well as in data analysis, have over the past decades enabled a profound revolution, where species can be delimited and recognized by data analysis of sequences. We aim at proposing new tools, in the framework of E-science, which make possible () better exploration of the diversity in a given clade, and () assignment of a place in these patterns for new, unknown organisms, using information provided by sets of sequences. This will require investment in data analysis, machine learning, and pattern recognition to deal with the volumes of data and their complexity.
One example of this project is about the diversity of trees in Amazonian forest, in collaboration with botanists in French Guiana. Protists (unicellular Eukaryots) are by far more diverse than plants, and far less known. Molecular exploration of Eukaryotes diversity is nowadays a standard in biodiversity studies. Data are available, through metagenomics, as an avalanche and make molecular diversity enter the domain of Big Data. Hence, an effort will be invested, in collaboration with other INRIA teams (GenScale, HiePACS) for porting to HPC algorithms of pattern recognition and machine learning, or distance geometry, for these tools to be available as well in metagenomics. This will be developed first on diatoms (unicellular algae) in collaboration with INRAE team at Thonon and University of Uppsala, on pathogens of tomato and grapewine, within an existing network, and on bacterial communities, in collaboration with University of Pau. For the latter, the studies will extend to correlations between molecular diversity and sets of traits and functions in the ecosystem.
4.2 Genome and transcriptome annotation
Sequencing genomes and transcriptomes provides a picture of how a biological system can function, or does function under a given physiological condition. Simultaneous sequencing of a group of related organisms is now a routine procedure in biological laboratories for studying a behavior of interest, and provides a marvelous opportunity for building a comprehensive knowledge base of the relations between genomes1, 11. Key elements in mining these relations are: classifying the genes in related organisms and the reactions in their metabolic networks, recognizing the patterns that describe shared features, and highlighting specific differences.
Pleiade develops applications in comparative genomics of related organisms, using new mathematical tools for representing compactly, at different scales of difference, comparisons between related genomes. New methods based on computational geometry refine these comparisons. Compact representations can be stored, exchanged, and combined. They will form the basis of new simultaneous genome annotation methods, linked directly to abductive inference methods for building functional models of the organisms and their communities.
Our ambition in biotechnology is to permit the design of synthetic or genetically selected organisms at an abstract level, and guide the modification or assembly of a new genome. Our effort is focused on two main applications: genetic engineering and synthetic biology of oil-producing organisms (biofuels in CAER, palm oils), and improving and selecting starter microorganisms used in winemaking (collaboration with the ISVV and the BioLaffort company).
4.3 Community ecology
Community assembly models how species can assemble or diassemble to build stable or metastable communities. It has grown out of inventories of countable organisms. Using metagenomics one can produce molecular based inventories at rates never reached before. Most communities can be understood as pathways of carbon exchange, mostly in the form of sugar, between species. Even a plant cannot exist without carbon exchange with its rhizosphere. Two main routes for carbon exchange have been recognized: predation and parasitism. In predation, interactions–even if sometimes dramatic–may be loose and infrequent, whereas parasitism requires what Claude Combes has called intimate and sustainable interactions 44. About one decade ago, some works 60 have proposed a comprehensive framework to link the studies of biodiversity with community assembly. This is still incipient research, connecting community ecology and biogeography.
We aim at developping graph-based models of co-occurence between species from NGS inventories in metagenomics, i.e. recognition of patterns in community assembly, and as a further layer to study links, if any, between diversity at different scales and community assemblies, starting from current, but oversimplified theories, where species assemble from a regional pool either randomly, as in neutral models, or by environmental filtering, as in niche modeling. We propose to study community assembly as a multiscale process between nested pools, both in tree communities in Amazonia, and diatom communities in freshwaters. This will be a step towards community genomics, which adds an ecological flavour to metagenomics.
Next-generation sequencing technologies are now an essential tool in population and community genomics, either for making evolutionary inferences or for developing SNPs for population genotyping analyses. Two problems are highlighted in the literature related to the use of those technologies for population genomics: variable sequence coverage and higher sequencing error in comparison to the Sanger sequencing technology. Methods are developed to develop unbiased estimates of key parameters, especially integrating sequencing errors 57. An additional problem can be created when sequences are mapped on a reference sequence, either the sequenced species or an heterologous one, since paralogous genes are then considered to be the same physical position, creating a false signal of diversity 52. Several approaches were proposed to correct for paralogy, either by working directly on the sequences issued from mapped reads 52 or by filtering detected SNPs. Finally, an increasingly popular method (RADseq) is used to develop SNP markers, but it was shown that using RADseq data to estimate diversity directly biases estimates 39. Workflows to implement statistical methods that correct for diversity biases estimates now need an implementation for biologists.
5 Social and environmental responsibility
5.1 Footprint of research activities
Pleiade's policy is to rely on shared computing platforms for computations that consume significant energy, for two reasons. First, those platforms have greater leverage over total energy consumption, and have the technical means to implement green computing on a useful scale. Second, those platforms have staff with the requisite skills to develop and implement policies as part of their service offer. Our partner platforms are mesocenters in Bordeaux and Grenoble, and national centers including the Idris and the CEA. Some of them charge back the cost of CO generation. The scientific committee of the Bordeaux mesocenter MCIA, which has a member from Pleiade, actively debates green computing implementation. Pursuant to our team policy, Pleiade does not use high-powered workstations on the desktop.
6 Highlights of the year
- First publications from the SLIMMEST exploratory action (§8.1) combining discrete reasoning models of metabolism with numerical metamodels and PDEs for the simulation of microbial communities in time and space 29, 35, 36.
- A new method for analyzing time-lapse confocal laser scanning images of bacterial swimmers in pathogenic exogeneous host biofilms, based on the inference of a kinetic model of swimmer populations including mechanistic interactions with the host biofilm 17.
- Definition and formal start of the flagship project MISTIC (§10.3.2), coordinated by Pleiade, in the Programme et équipements prioritaires de recherche (PEPR) Agroecology and ICT. MISTIC will elucidate the role of microbial community dynamics in the adaptation of crop plants to environmental stresses including climate change.
- Dissemination of two new monographs by Alain Franc : Linear Dimensionality Reduction, reviewing the broad domain of linear methods in multivariate data analysis, and showing how the diversity of methods and tools boil down to a single core method, PCA with SVD, on which efforts to optimize codes for analyzing massive data sets can focus 28; and Tensor Ranks for the Pedestrian, reviewing tensors and presenting in detail an integrated and progressive approach to approximate a given tensor by a tensor of lower rank 49.
7 New software and platforms
7.1 New software
7.1.1 Metage2Metabo
-
Keywords:
Metabolic networks, Microbiota, Metagenomics, Workflow
-
Scientific Description:
Flexible pipeline for the metabolic screening of large scale microbial communities described by reference genomes or metagenome-assembled genomes. The pipeline comprises several main steps. (1) Automatic and parallel reconstruction of metabolic networks. (2) Computation of individual metabolic potentials (3) Computation of collective metabolic potential (4) Calculation of the cooperation potential described as the set of metabolites producible by species only in a cooperative context (5) Computation of minimal-sized communities sastifying a metabolic objective (6) Extraction of key species (essential and alternative symbionts) associated to a metabolic function
-
Functional Description:
Metabolic networks are graphs which nodes are compounds and edges are biochemical reactions. To study the metabolic capabilities of microbiota, Metage2Metabo uses multiprocessing to reconstruct metabolic networks at large-scale. The individual and collective metabolic capabilities (number of compounds producible) are computed and compared. From these comparisons, a set of compounds only producible by the community is created. These newly producible compounds are used to find minimal communities that can produce them. From these communities, the keytstone species in the production of these compounds are identified.
-
News of the Year:
2022: (1) Fix the number of colors used to color the taxon in the powergraph.(2) Change the shapes of the nodes in the html output of m2m_analysis: circle for essential symbionts and square for alternative symbionts. (3) Release of version 1.5.3.
- URL:
- Publication:
-
Contact:
Clemence Frioux
-
Participants:
Clemence Frioux, Arnaud Belcour, Anne Siegel
7.1.2 MiSCoTo
-
Name:
Microbiota Screening and COmmunity Selection with TOpology
-
Keywords:
Metabolic networks, ASP - Answer Set Programming, Logic programming
-
Scientific Description:
MiSCoTo solves combinatorial problems using Answer Set Programming. It aims at minimizing either the number of selected species or both the number of selected species and the cost of the interaction between them, characterized by the number of metabolic exchanges. In the first case, the level of modeling is called lumped or mixed-bag, in the latter, it is compartmentalized.
-
Functional Description:
Metabolic networks are composed of biochemical reactions and gather the expected metabolic capabilities of species. For organisms that live in interaction altogether (microbiotas), complementarity between these networks can be exploited to predict cooperation events. This software takes as inputs metabolic networks for various species (host, symbionts of the microbiota), components of the growth medium and a metabolic objective (metabolites to be produced), and aims at selecting a minimal set of symbionts to ensure the metabolic objective can be achieved. The software can use two types of modelings: a simplified one and another that takes into account the cost of metabolic exchanges and aims at minimizing it.
-
Release Contributions:
Memory usage optimization. Fix issues with input file formats.
-
News of the Year:
(1) Release of version 3.1.1 (2) New functionality: miscoto-focus determines the metabolic potential of symbionts of interest in the community
- URL:
- Publication:
-
Contact:
Clemence Frioux
-
Participants:
Clemence Frioux, Anne Siegel, Enora Fremy, Camille Trottier, Arnaud Belcour
7.1.3 MeneTools
-
Name:
Metabolic networks Topological tools
-
Keywords:
Metabolic networks, Graph, Topology, Bioinformatics, Systems Biology, ASP - Answer Set Programming
-
Scientific Description:
MeneTools are a set of tools for the exploration of the producibility potential in a metabolic network using the network expansion algorithm. The MeneTools can: - assess whether targets are producible starting from nutrients (Menecheck) - get all compounds that are producible starting from nutrients (Menescope) - get all reactions that are activable from nutrients (Meneacti) - get production paths of specific compounds (Menepath) - obtain compounds that if added to the nutrients, would ensure the producibility of targets (Menecof) - identify metabolic deadends, i.e. metabolites that act as reactants of reactions but never as products, or metabolites that act as products of reactions but never as reactants. This is a purely structural analysis. All MeneTools using modelling follow the producibility in metabolic networks as defined by the network expansion algorithm.
-
Functional Description:
MeneTools consists in four topological tool to analyze metabolic models in a graph-based perspective. Menecheck verifies the producibility of target compounds from available substrates (growth medium) of the metabolic network. Menescope gives the whole range of accessible compounds in the metabolic network starting from substrates. Menepath give the production paths of given compounds in the model. Menecof proposes compounds that need to be produced or added as substrate for ensuring the producibility of targets.
-
News of the Year:
(1) Release of version 3.2.0 (2) New functionality: mene-seed identifies external compounds from the topology of the network
- URL:
- Publications:
-
Contact:
Clemence Frioux
-
Participants:
Clemence Frioux, Anne Siegel, Arnaud Belcour
7.1.4 Fluto
-
Keywords:
ASP - Answer Set Programming, Answer Set Programming, Metabolic networks, Flux Balance Analysis, Linear programming
-
Scientific Description:
Fluto performs metabolic network completion with respect to topological and linear reaction rate constraints based on the stoichiometry of metabolic reactions.
-
Functional Description:
Fluto relies on Answer Set Programming (ASP) and a hybrid modelling that associates to ASP a Linear Programming (LP) constraint propagator. Models satisfying the qualitative constraints of network expansion are tested for satisfiability of flux constraints with the LP propagator. Resulting answer sets permit the completion of a metabolic network that ensures the metabolic reaction of interest is activated according to both formalisms.
-
News of the Year:
Reorganisation of the code. Implementation of continuous integration. Addition of the Sagot & Acuna formalism in the software.
- URL:
- Publications:
-
Contact:
Clemence Frioux
-
Participant:
Sven Thiele
-
Partners:
Max Planck Institute Magdeburg, University of Potsdam
7.1.5 Emapper2GBK
-
Keywords:
Bioinformatics, Metabolic networks, Functional annotation
-
Functional Description:
Starting from FASTA and Eggnog-mapper annotation files, Emapper2GBK builds a GBK file that is suitable for metabolic network reconstruction with Pathway Tools, and adds the GO terms and EC numbers annotations in the GenBank file.
-
News of the Year:
2022: Using gffutils region to speed up emapper2gbk. Supporting for gmove and eggnog GFF format. Adding gff-type option: add mRNA and gene parameters. Allowing the tool to use the IDs in "mRNA" or "gene" field in the gff to match the faa file IDs. Improving error messages and updating the readme.
- URL:
- Publication:
-
Contact:
Clemence Frioux
-
Participants:
Clemence Frioux, Arnaud Belcour, Anne Siegel
7.1.6 Biodiversiton
-
Name:
Biodiversiton
-
Keywords:
Biodiversity, Comparative metagenomics, Clustering, Dimensionality reduction, Masses of data
-
Functional Description:
Biodiversiton is a suite of tools for biodiversity composed by Rsyst, pairwise_dis, diagno_syst, and yapotu. The global project provides tutorials, datasets, and a readme for the whole suite.
- URL:
-
Authors:
Alain Franc, Jean-Marc Frigerio, Franck Salin
-
Contact:
Alain Franc
7.1.7 Yapotu
-
Name:
Yet Another Pipeline for OTU building
-
Keywords:
Metagenomics, Biodiversity, Dimensionality reduction, Masses of data
-
Functional Description:
The main functionalities are as follows: 1) building OTUs from a fasta file (swarm, vsearch, ..) or a distannce file (yapotu) for an environmenal sample 2) building a fasta file and a distance file per OTU 3) checking the consistency of the OTUs by displaying them as a graph (see OTU as a graph below) 4) displaying the shape of an OTU or of a set of OTUs by Multidimensional Scaling 5) implementing Hierachical Aggregative Clustering of an OTU or a set of OTUs with various aggregation methods
-
News of the Year:
Ugraded from an older version, fusion with declic now deprecated, new functionalities for working with massive data sets
- URL:
-
Authors:
Alain Franc, Jean-Marc Frigerio, Franck Salin
-
Contact:
Alain Franc
-
Partner:
INRAE
7.1.8 pydiodon
-
Name:
pydiodon
-
Keywords:
Dimensionality reduction, Data analysis
-
Functional Description:
Most of dimension reduction methods inherited from Multivariate Data Analysis, and currently implemented as element in statistical learning for handling very large datasets (the dimension of spaces is the number of features) rely on a chain of pretreatments, a core with a SVD for low rank approximation of a given matrix, and a post-treatment for interpreting results. The costly part in computations is the SVD, which is in cubic complexity. Diodon is a list of functions and drivers which implement (i) pre-treatments, SVD and post-treatments on a large diversity of methods, (ii) random projection methods for running the SVD which permits to bypass the time limit in computing the SVD, and (iii) an implementation in C++ of the SVD with random projection at prescribed rank or precision, connected to MDS.
-
Release Contributions:
- completed documentation with sphynx - library now public through Inria git - availability of a readme - making a few "toy" datasets available - delivering a few jupyter notebooks as tutorials
- URL:
-
Authors:
Alain Franc, Florent Pruvost, Romain Peressoni, Romain Peressoni
-
Contact:
Alain Franc
7.1.9 swim-infer
-
Keywords:
Bayesian estimation, Trajectory Modeling, Trajectory Generation
-
Scientific Description:
Bayesian inference of swimming trajectories described by population-wide movement conservation equations taking into account interaction terms with the host biofilm (speed and direction selection, stochastic term).
-
Functional Description:
Bayesian inference solver of swimming trajectories of microbial micro-swimmers in biofilms from confocal microscopy images. The specificity of the solver is to take into account the interactions of the micro-swimmers with the host biofilm.
-
News of the Year:
First release
- URL:
- Publication:
-
Contact:
Simon Labarthe
-
Participants:
Simon Labarthe, Guillaume Ravel
7.1.10 mpwt
-
Keywords:
Metabolic networks, Multi-processor
-
Functional Description:
mpwt is a Python package for running Pathway Tools on multiple genomes using multiprocessing. More precisely, it launches one PathoLogic process for each organism. This allows to increase the speed of draft metabolic network reconstruction when working on multiple organisms.
-
News of the Year:
2022: Changing mpwt to run the processes independently. Now it can take as input PathoLogic files without fasta. This should make mpwt compatible with PathoLogic files created by EsMeCaTa. Adding the -dump-flat-files-biopax option compatible with Pathway Tools 26.0.
- Publication:
-
Contact:
Anne Siegel
-
Participants:
Arnaud Belcour, Anne Siegel, Clemence Frioux, Meziane Aite
7.1.11 TANGO
-
Keywords:
Computational biology, Systems Biology, Metabolic networks, Bacterial strains
-
Functional Description:
The organoleptic properties that provide the added value of fermented dairy products result from specific metabolites that are produced by metabolic processes performed in concert by consortia of microbial species. TANGO enable a deeper understanding of the molecular and cooperative mechanisms underlying the production of organoleptic compounds. Tango uses a combination of whole-genome metabolic modeling and dynamic numerical simulation to assemble a complete, precise model of cheese production using lactic acid and propionic acid bacteria. The results of this modeling reveal interactions between the members of the bacterial community, follow dynamically organoleptic compounds and fit with experimental data.
-
Contact:
Maxime Lecomte
7.2 New platforms
Participants: David Sherman, Ariane Badoual.
As a founding principle, Pleiade supports reproducible scientific analyses and promotes a declarative approach using reusable software modules, rigorous documentation of data provenance, and systematic recording of workflows. The latter is a challenge when interactive interfaces are used, but can be addressed, to cite two examples, in Galaxy by extracting workflows, and in other systems by using Jupyter notebooks. Part of Pleiade's mission is to automate the deployment of environments that support these goals, for non-technical end users.
Pleiade relies on specific computing resources to support our work and that of our collaborators. There are four main use cases:
- Fast deployment of containerized user environments, combining biological data and databases, software modules specified by version, a CWL executor, and interactive tools including web front ends, notebooks, or Galaxy. A user environment will provide at least one specific HTTPS endpoint, created dynamically. A single researcher may deploy several different environments in the course of one day.
- Support for development and testing of workflows, as above but configured for team members who are developing software modules or interfaces, and who must often deploy several different environments simultaneously.
- Dynamically allocated containerized compute tasks, including both individual analysis steps in workflows and GitLab runner containers used for continuous integration. These tasks arrive in bursts that often cannot be planned in advance.
- Long-running stream preprocessing, a low-priority background task that watches external databases for changes, chooses pertinent data, precomputes representations and ingests them into local data bases.
We support community best practices for reproducible computing in bioinformatics, using biocontainers generated by bioconda, in CWL or Galaxy workflows. For internal use we provide TES endpoints and host JupyterHub environments.
Pleiade's environment is built on OKD 4, the community distribution of Kubernetes developed alongside of RedHat Openshift. OKD4 in particular uses the CRI-O runtime, not Docker, and containers run unprivileged. Software-defined storage and S3 endpoints are provided by Ceph.
8 New results
8.1 Modeling the metabolic of the gut microbiome in time and space
Participants: Pablo Ugalde-Salas, Simon Labarthe, Clémence Frioux, Coralie Muller, Arie Wortsman Zurich.
In 2021, an Inria Exploratory Action - SLIMMEST – carried out by Simon Labarthe and Clémence Frioux – was initiated. This project aims at combining discrete reasoning models of metabolism to numerical metamodels and PDEs for the simulation of microbial communities in time and space. The selected methodology is the coupling between PDE-based microbial population dynamics model with metamodels of complex optimizations predicting their metabolism. The main difficulty here is to ensure the scalability of the simulation and the selection of relevant metabolic functions and species to be tracked over time. The grant included the participation to the 2021 CEMRACS summer school with a research projet, a postdoc (Pablo Ugalde) and an engineer (Coralie Muller) position.
Metabolic models allow the prediction of the metabolic behaviour of microbial strains from the knowledge of their genomes. Quantitative methods such as Flux Balance Analysis provide a framework to compute metabolic fluxes (i.e. consumption and production rates of metabolites present in the environment of the microbe) and biomass growth at the cost of an optimization problem. When modeling the dynamics of microbial communities, a FBA model must be solved for each microbial strain of the community and at each time step of the dynamics, representing an important computational load.
The aim of the project is to articulate qualitative methods to analyse the functional potential of a microbial community by analysing and simplifying the community-wide metabolic capabilities, to surrogate models of the individual FBA models to provide fast and accurate simulations of the community dynamics. Qualitative methods include Answer Set Programming (ASP) to predict metabolic interactions in the community, metabolic exploration and simplifications. Surrogate models are obtained with a statistical method named ANOVA-RKHS that build a specific RKHS allowing for feature selection and promissing trade-off between speed and accuracy.
In 2022, the work achieved during the CEMRACS project has been accepted for publication in the CEMRACS proceedings 29. Figure 1 illustrates the use of surrogate metamodels learned by ANOVA-RKHS to speed up dynamic flux balance analysis. The team hosted Arie Worstman as intern to work on the project. The project results have been presented by Coralie Muller, Arie Worstman and Pablo Ugalde during several national (JOBIM, journées du GDR MathSav) 35 and international conferences (Newton Institute conference on microbial communities) 36.
In related work concerning gut microbiota, we constructed an individual-based model of epithelial cells interacting with the microbiota-derived chemicals diffusing in the crypt lumen, formalized as a piecewise deterministic Markov process 13. It accounts for local interactions due to cell contact, and for cell proliferation, differentiation and extrusion that are regulated spatially or by chemical concentrations. It also includes chemicals diffusing and reacting with cells. A deterministic approximated model is also introduced for a large population of small cells, expressed as a system of porous media type equations. Both models were extensively studied through numerical exploration.
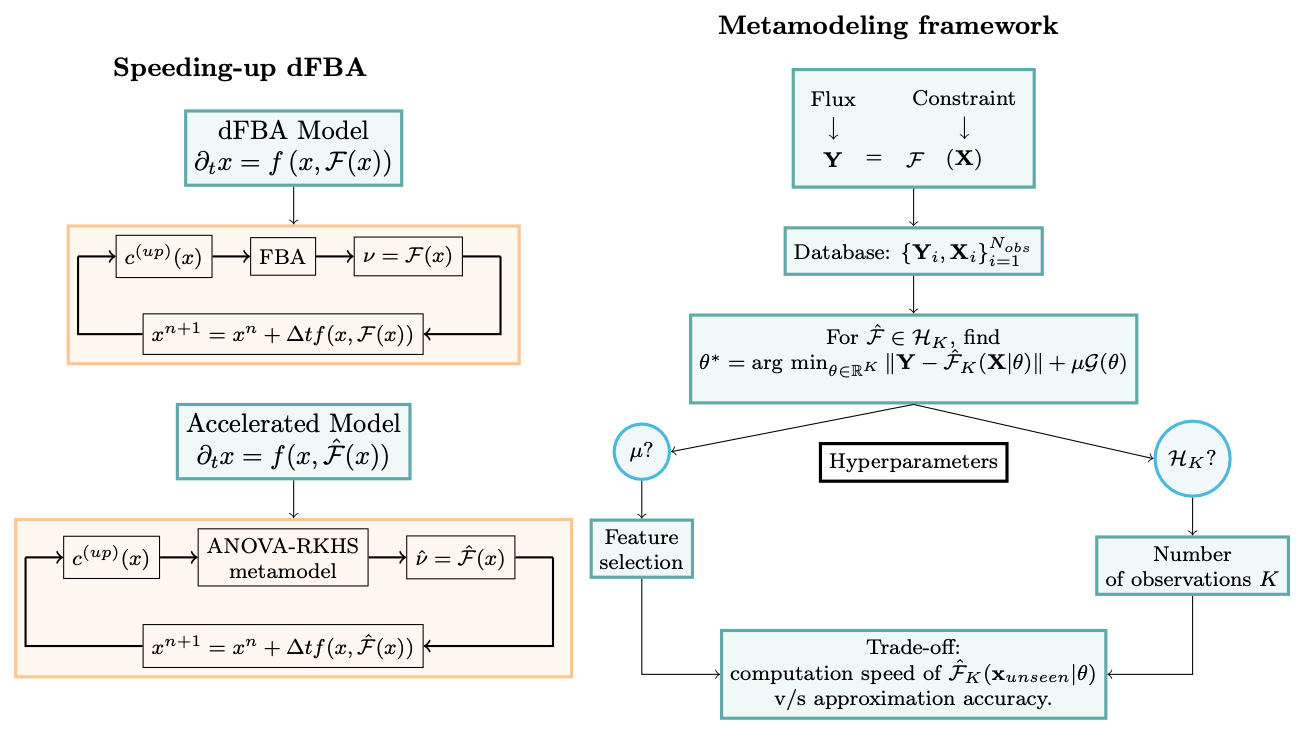
The figure contains two columns. On the left is a contrast of two iterative computations: one labeled “dFBA Model” with an FBA optimization step, one labeled “Accelerated Model” with a metamodel optimization step. On the right is a flowchart showing how hyperparameters are chosen, with a trade-off between computation speed and approximation accuracy.
8.2 Characterization of Molecular Biodiversity
Participants: Mohammed Anwar Abouabdallah, Romain Peressonni, Alain Franc.
In 2021, Pleiade continued the development and refinement of new methods for chacterizing molecular biodiversity. Two approaches are being pursued, each with a PhD student in their third year.
- The central focus of Mohammed Anwar Abouabdallah's PhD is building OTUs from a pairwise distance matrix using Stochastic Block Models (SBM). Building OTUs is traditionally seen as a form of unsupervised clustering. This work is done in collaboration with the MIAT INRAE research unit in Toulouse and HiePACS. It represents a connection between metabarcoding and statistical modeling, a topic which deserves investigation. In 12, we studied whether morphological-based and molecular-based approaches are in agreement, and provided evidence that yes, automatic clustering and group identification can be done reliably using barcoding. Using Aggregative Hierarchical Clustering and Stochastic Block Models, we found that the agreement between morphological-based and molecular-based classifications ranges in most cases from good to very good at taxonomic levels above species (figure 2).
- A major goal of Pleiade is to develop a geometric view of biodiversity. The tool selected up to now is to associate a point cloud to a dataset (pairwise distances between sequences) and to study its shape. This approach has expanded and been developed in 2020 as a collaboration with HiePACS through the cosupervision of Romain Peressonni's PhD, which aims to provide new approaches and algorithms for computing distances between two point clouds.
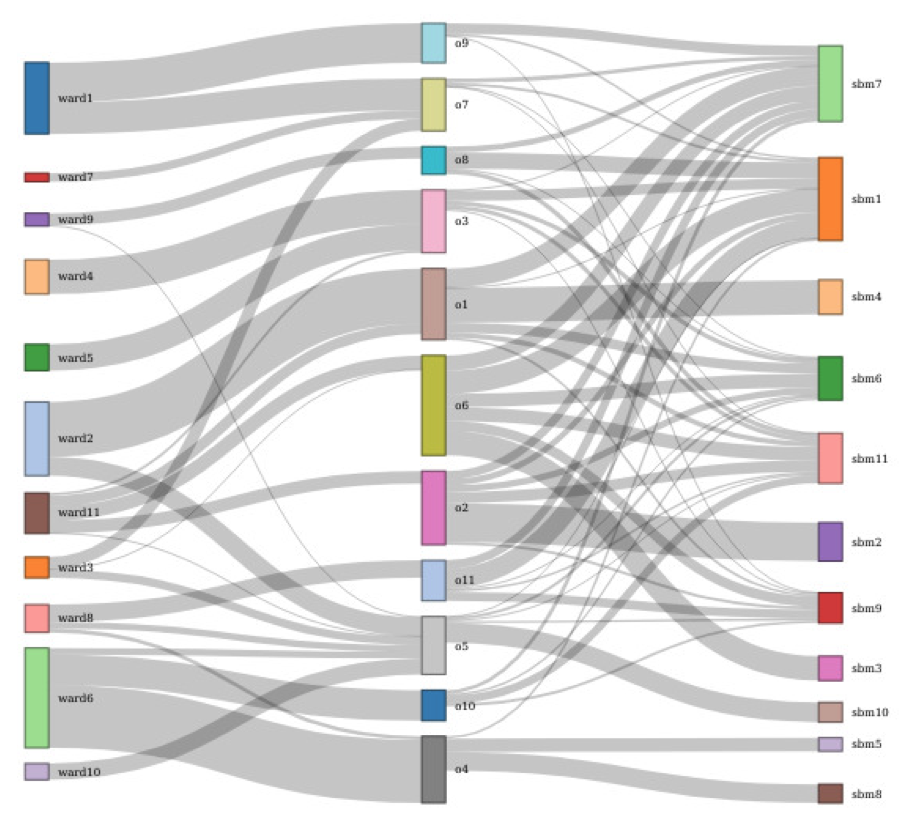
The figure contains three columns comprised of vertically-oriented rectangles of different sizes and colors. Vertical intervals of the colored rectangles in adjacent columns are linked by gray horizontal paths, curved so that the paths are perpendicular to the rectangles, but change vertical position to establish the correspondence between the intervals of the rectangles. A single rectangle may thus be linked to several rectangles in the adjacent column. Overall, the intervals cover most of the extent of the rectangles. To the left, most rectangles in the middle column map to just one, or to a small number, of rectangles in the left column. To the right, the relations are more complex: rectangles in the middle column often map to several rectangles in the right column, and, conversely, rectangles in the right column may map to several rectangles in the middle column.
8.3 Dimension Reduction
Participants: Alain Franc, Jean-Marc Frigerio.
Metabarcoding is a series of technical procedures to build molecular based inventories from large datasets of amplicons. The underlying information needs to be compacted without losing its information content before it can be further processed with domain-specific tools. This links metabarcoding tools to dimension reduction techniques, which is an important topic in Pleiade. This has been implemented through a participation in following research projects:
- Contribution to and finalization of the ADT Gordon project in Inria BSO. The objective of this project (partners: Tadaam (coordinator), Storm, HiePACS, Pleiade) is to integrate SVD as a tool available in Chameleon, starPU and new Madeleine. The contribution of Pleiade is to bring in metabarcoding as a use case, and random projection as a method for scaling Multidimensional Scaling (which requires an SVD) in collaboration with HiePACS with a template implemented in Diodon. A MDS on a 106 x 106 matrix has been succesfully run at the end of ADT Gordon, on Occigen, in 900 seconds including I/O.
- A consequence of this involvement is the ADT Diodon, for extending to a diversity of linear dimension reduction techniques what has been aquired in ADT Gordon for MDS, namely a significant progress in speed and memory management brought by random SVD, which can be integrated into a diversity of methods : PCA, CoA, etc.
- Pleiade is involved in the EU project EOSC-Pillar, in a task for better connecting data to calculation, currently data in Inrae Dataverse system connected to tools running on a INRAE local server or on PlaFRIM, on a testbed on biodiversity assessment with metabarcoding. This task in done in collaboration with INRAE DipSO (Direction Science Ouverte) and the Inria HiePACS project-team.
8.4 Reasoning-based Modeling of interactions and metabolic redundancy in microbial communities
Participants: Maxime Lecomte, David Sherman, Clémence Frioux, Chabname Ghassemi Nedjad.
Over the past few years, we demonstrated how reasoning approaches can prove helpful for the analysis of microbial community metabolism through the Modeling of complementarity accross metabolic networks that permit the selection of minimal communities 50 and more generally screening metabolic potential in microbiomes 41.
These previous works illustrated the need for scalable methods in order to tackle large collections of genome, an objective that is hardly reachable with numerical models. Our recent work focuses on going further in characterizing microbial communities and in particular the interactions that occur among species and with their environment. We take advantage again of the expressivity of the logic paradigm of Answer Set Programming as we provide a model of competitive and cooperative interactions among species in order to compare communities. As such, in the context of Maxime Lecomte's PhD, we developped scores assessing both competition and cooperation potentials based on the genome-scale metabolic networks of microbial species. This work was presented at the French national conference in bioinformatics (JOBIM) 33, and as seminars 23, 22.
A second axis of research relates to the follow up of the Metage2Metabo paper 41 in which we identified interesting patterns of associations in the minimal communities that we computed for groups of metabolic targets using genome-scale metabolic networks of cultivable species from the human gut microbiome. We observed that when compressing association graphs of the assemblies of minimal communities, groups of equivalent bacteria were highlighted, illustrating their similar roles in these communities. We therefore enquired the underlying mechanisms explaining the equivalency between bacteria, what role each group played in the community. To that end, we used Answer Set Programming to query the metabolic potential of each species, in relation to members of its equivalence group, members of other groups or species that were not selected in minimal communities in order to highlight the specific functions responsible for the assemblies. Preliminary results demonstrate that while the combinatorics of shared functions are high, we can suggest functional roles for most groups in microbial assemblies. These results were presented at the French national conference in bioinformatics (JOBIM) and as seminars 20, 31.
8.5 Metabolic Modeling of marine algae: methodological developments and applications
Participants: Clémence Frioux.
Brown algae, especially the species Ectocarpus siliculosus, are important models for deciphering the complex interactions within marine holobionts, with the goal of studying their metabolism together with the metabolism of the bacteria that inhabit their direct environment. Because performing wet lab experiments on such systems is technocally challenging, there is need for bioinformatic predictive methods for assessing the putative roles and interdependences between species. In parallel, addressing the difficulties brought by the study of these organisms is also a means to enhance and calibrate the tools devlopped in the team. Hence a fruitful collaboration for the past years has been developed with scientists from the Roscoff Biological station and the Inria project team Dyliss (Rennes).In 2022, we published a work investigating the potential for mutualistic and harmful host–microbe interactions affecting brown alga freshwater acclimation 15. This work combined wet lab experiments and computational models in order to establish how changes in the microbiome composition of the alga can impact the ability of the latter to grow in low-salinity environments.
More generally, the metabolism of algae themselves is challenging to decipher, as it is for most eukaryotic species. A bottleneck resides in the difficulty of annotating their genomes, leading to manual annotations being of importance for these species. However, when aiming at comparing the metabolism of several organisms, it is preferable to annotate all of their genomes homogeneously, usually automatically, in order to prevent the propagation of biases during metabolic reconstruction. This entails ignoring the manual curation work performed on the genomes. AuCoMe is a pipeline aiming at preserving and propagating manual annotations as it permits working with heterogeneously-annotated genomes and efficiently compare their metabolic contents 26. It was tested on several datasets of genomes, including algal ones, and demonstrated that it builds good quality metabolic networks as it corrects the inconsistencies brought by heterogenous annotation efforts.
8.6 Bacterial swimming in biofilms
Participants: Simon Labarthe.
Biofilms are spatially organized colonies on microorganisms, embedded in a self-produced matrix that confers on the community resistance to environmental stresses. Motile bacteria have been observed swimming in the matrix of pathogenic exogeneous host biofilms, suggesting a potential use of bacterial swimmers to increase biofilm vascularization, and thus enhance chemical treatment or biocontrol agent delivery. To study swimmer trajectories in biofilm matrices, we developed a new method for analyzing time-lapse confocal laser scanning images 17, based on the inference of a kinetic model of swimmer populations including mechanistic interactions with the host biofilm. The fitted model allowed us to stratify different swimmer populations by their swimming behavior and to provide insights into the adaptive mechanisms used by micro-swimmers.9 Bilateral contracts and grants with industry
9.1 Bilateral contracts with industry
Participants: Clémence Frioux, Éloïse Guillem.
An Inria tech contract was conducted with the biotech Ysopia Bioscience between mid 2021 and early 2022. This collaboration was carried out by Éloïse Guillem, engineer of the SED department, and Clémence Frioux.10 Partnerships and cooperations
10.1 International initiatives
10.1.1 Associate Teams in the framework of an Inria International Lab or in the framework of an Inria International Program
Clémence Frioux is the co-leader of the Inria associate team SymBioDiversity, co-led with Anne Siegel from Dyliss (Rennes, France) and associated to the Centre for Mathematical Modelling at the University de Chile (Santiago de Chile), the Mathomics team led by Alejandro Maass.
10.1.2 Participation in other International Programs
Internships Chile: visit of Arie Wortsman Zurich, for 3 months.
10.2 International research visitors
10.2.1 Visits of international scientists
Other international visits to the team
Sébastien Raguideau
-
Status:
Post-Doc
-
Institution of origin:
Earlham Institute
-
Country:
United Kingdom
-
Dates:
November 13th to November 16th
-
Context of the visit:
Scientific collaboration
-
Mobility program/type of mobility:
seminar
10.2.2 Visits to international teams
Research stays abroad
Clémence Frioux
-
Visited institution:
Centro de Modelamiento Matematico
-
Country:
Chile
-
Dates:
May 9th to May 21st 2022
-
Context of the visit:
Inria associated team
-
Mobility program/type of mobility:
conference, workshop and scientific collaboration
Clémence Frioux
-
Visited institution:
Quadram Institute Bioscience
-
Country:
United Kingdom
-
Dates:
October 15th to October 22nd 2022
-
Context of the visit:
scientific collaboration
Maxime Lecomte
-
Visited institution:
Centro de Modelamiento Matematico
-
Country:
Chile
-
Dates:
May 9th to May 22nd 2022
-
Context of the visit:
Inria associated team
-
Mobility program/type of mobility:
conference, workshop and scientific collaboration
10.3 National initiatives
10.3.1 Agence Française pour la Biodiversité
Participants: Alain Franc, Jean-Marc Frigerio.
The AFB is a public law agency of the French Ministry of Ecology that supports public policy in the domains of knowledge, preservation, management, and restoration of biodiversity in terrestrial, aquatic, and marine environments. Pleiade is a partner in two AFB projects developed with the former ONEMA: one funded by ONEMA, the second by labex COTE, where BioGeCo/Pleiade is responsible for data analysis, with implementaton of the tools recently developed for scaling MDS. Calculations have been made on CURTA at MCIA and PlaFRIM at INRIA.10.3.2 PEPR Agroecology and ICT
Participants: David Sherman, Clémence Frioux, Simon Labarthe, Alain Franc, Jean-Marc Frigerio.
MISTIC, Microbial communities and ICT, has been selected as a five-year flagship project in the PEPR Agroecology and ICT program of the French Government. MISTIC will develop methodological tools for defining spatio-temporal models of microbial community dynamics in the phyllosphere and rhizosphere of crop plants, with the goal of creating new understanding of the role of these communities in plant adaptation to environmental stresses, including climate change. MISTIC is a partnership between seven Inria and INRAE teams in Bordeaux, Rennes, and Sophia Antipolis. The project formally began in November 2022.10.4 Regional initiatives
10.4.1 Poppy Rosa ProtoImpact
Participants: David Sherman.
Poppy Rosa ProtoImpact is an educational robots project financed by the Conseil Régional de la Nouvelle Aquitaine and coordinated by the Ligue de l'Enseignement de la Gironde, with Poppy Station and Inria as partners. Poppy Rosa is prototyping a new way of teaching concepts of algorithmics and artificial intelligence to young students, with the goal of training tomorrow's citizens. Our deployment specifically targets rural schools across the Neo-Aquitaine region.11 Dissemination
11.1 Promoting scientific activities
11.1.1 Scientific events: organisation
Member of the organizing committees
- Co-organisation of a mini-symposium at JOBIM 2022, the French national conference of bioinformatics. [Clémence Frioux ]
11.1.2 Scientific events: selection
Member of the conference program committees
- 20th International Conference on Computational Methods in Systems Biology (CMSB 2022) [Clémence Frioux ]
- Journées GDR maths bio santé 2022 [Simon Labarthe ]
Reviewer
11.1.3 Journal
Member of the editorial boards
- BMC Evolutionary Biology [Alain Franc ]
Reviewer - reviewing activities
- Nature Communication [Clémence Frioux ]
- Microbiome [Clémence Frioux ]
- iScience [Clémence Frioux ]
- BMC Bioinformatics [Clémence Frioux ]
- mSystems [Simon Labarthe ]
11.1.4 Invited talks
- Workshop SymBioDiversity, CMM, U. de Chile (Santiago de Chile, May 2022) - Characterizing the human gut microbiome through the lens of metagenomics and metabolic models [Clémence Frioux ]
- Workshop SymBioDiversity, CMM, U. de Chile (Santiago de Chile, May 2022) - Characterizing microbial interactions in controlled and natural microbial communities [Maxime Lecomte ]
- Journées Scientifiques Inria Chile (Santiago de Chile, May 2022) - Symbiodiversity associated team [Clémence Frioux ]
- Bordeaux Bioinformatics Center (Bordeaux, France, January 2022) - Logic modelling of metabolism: from individual networks to communities [Clémence Frioux ]
- INRIA-DFKI Workshop on AI (Bordeaux, France, October 2022) – Opportunities for learning and explaining microbiomes in agroecology [David Sherman ]
- Journées Française de la nutrition (JFN, Toulouse, France, November 2022) - Omic-based model of fiber degradation. [Simon Labarthe ]
- Breizh CarnoTech (Rennes, France, November 2022) – MISTIC: Microbial communities and TIC [David Sherman ]
11.1.5 Leadership within the scientific community
- David Sherman is on the steering committee of Biosena, a regional research network of the New Aquitaine region dedicated to Biodiversity and Ecosystemic Services. Biosena associates actors from the academic and socio-economic sectors, with the goal of contributing to the understanding and preservation of biodiversity and to the improvement of ecosystemic services. Biosena contributes to this goal through research, knowledge dissemination, outreach, and skill transfer in the form of Research Action, in keeping with the recommendations of Ecobiose.
- David Sherman is member of the board (membre du Conseil d'administration) and secretary of the Mobsya Association, Lausanne. Mobsya develops and commercializes the Thymio educational robot, geared towards K-12.
- David Sherman is member of the board (membre du Conseil d'Administration) and lead advisor for software of the Poppy Station Association. Poppy Station develops open-hardware open-source humanoid robots for research and education.
11.1.6 Scientific expertise
Recruitment committees
- Junior researcher selection committee of the Inria Centre at the University of Bordeaux [Clémence Frioux ]
- Assistant professor selection committee Univ. Côte d'Azur [Clémence Frioux ]
11.1.7 Research administration
Local responsabilites
- Co-creation of and participation in a gender equality and diversity working group in the Inria Centre at the University of Bordeaux [Clémence Frioux ]
11.2 Teaching - Supervision - Juries
11.2.1 Teaching
- Master – ENSTBB Bordeaux INP - Bioinformatics [Clémence Frioux ]
- Master – ENSEIRB Bordeaux INP - Research algorithms [Clémence Frioux ]
- Graduate School – Doctoral School Computer Science, Mathematics, Univ. Bordeaux - Answer Set Programming [Clémence Frioux ]
11.2.2 Supervision
- PhD of Maxime Lecomte (2020-2023) - Approches hybrides en modélisation logique et numérique du métabolisme des écosystèmes microbiens - David Sherman (Director), Hélène Falentin (director, INRAE STLO), Clémence Frioux (advisor)
- PhD of Chabname Ghassemi Nedjad (2022-2025) - Combinatorial optimisation problems for reverse ecology - Clémence Frioux (co-director), Loïc Paulevé (CNRS, LaBRI, co-director).
- PhD of Mohamed Anwar Abouabdallah (2020-2023) - Approche Tenseur-Train pour l'inférence dans les modèles à blocs stochastiques, application à la caractérisation de la biodiversité - Alain Franc , Olivier Coulaud and Nathalie Peyrard
- Master's internship of Arie Wortsman Zurich - Metamodelling of genome-scale metabolic networks. 3 months – co-supervised by Simon Labarthe and Clémence Frioux
- Master's internship of Quentin Chapuzet - Temporal logic in Answer Set Programming for the modelling of microbial communities. 6 months – co-supervised by Maxime Lecomte and David Sherman
- Master's internship of Chabname Ghassemi Nedjad - Explainable models of minimal microbial community assembly. 6 months – supervised by Clémence Frioux
- Apprenticeship of Léonard Brindel - Platform for metagenome assembly – co-supervised by Clémence Frioux and Franck Salin
11.2.3 Juries
PhD defense juries
- Antoine Régimbeau - Univ. Nantes [Clémence Friouxexaminer]
- Déborah Boyenval - Univ. Côte d'Azur - [Clémence Friouxexaminer]
PhD thesis committee
- Mathieu Bolteau - Univ. Nantes [Clémence Frioux ]
- Coralie Rousseau - Sorbonne Univ. [Clémence Frioux ]
- Maxime Mahout - Univ. Paris-Saclay [Clémence Frioux ]
11.3 Popularization
11.3.1 Education
- Hosting of 5 students in the troisième grade for a week of observation
11.3.2 Interventions
- Chiche ! Un ou une scientifique, une classe – 5 classes de seconde, 4 classes de troisième. [Clémence Frioux ]
- Cordées de la réussite 1 scientifique, 1 classe : Chiche! [Clémence Frioux ]
- Cordées de la réussite Qui se ressemble s'assemble [David Sherman ]
- Fête de la Science : Circuit Scientifique Bordelais – cinq ateliers Qui se ressemble s'assemble [David Sherman ]
12 Scientific production
12.1 Major publications
- 1 articleA Gondwanan imprint on global diversity and domestication of wine and cider yeast Saccharomyces uvarum..Nature Communications52014, 4044
- 2 articleModeling acclimatization by hybrid systems: Condition changes alter biological system behavior models.BioSystems121June 2014, 43-53
- 3 articleMetagenomic assessment of the global distribution of bacteria and fungi.Environmental MicrobiologyNovember 2020
- 4 articleMetage2Metabo, microbiota-scale metabolic complementarity for the identification of key species.eLife9December 2020
- 5 articleMetabolic Complementarity Between a Brown Alga and Associated Cultivable Bacteria Provide Indications of Beneficial Interactions.Frontiers in Marine Science7February 2020, 1-11
- 6 articleThe genome of Ectocarpus subulatus – A highly stress-tolerant brown alga.Marine Genomics52January 2020, 100740
- 7 articleUsing automated reasoning to explore the metabolism of unconventional organisms: a first step to explore host–microbial interactions.Biochemical Society Transactions483May 2020, 901-913
- 8 articleFrom bag-of-genes to bag-of-genomes: metabolic modelling of communities in the era of metagenome-assembled genomes.Computational and Structural Biotechnology JournalJune 2020
- 9 incollectionWhy We Need Sustainable Networks Bridging Countries, Disciplines, Cultures and Generations for Aquatic Biomonitoring 2.0: A Perspective Derived From the DNAqua-Net COST Action.Next Generation Biomonitoring: Part 158Elsevier2018, 63-99
- 10 articleExact or approximate inference in graphical models: why the choice is dictated by the treewidth, and how variable elimination can be exploited.Australian and New Zealand Journal of Statistics612to appearJune 2019, 89-133
- 11 articleGenolevures: protein families and synteny among complete hemiascomycetous yeast proteomes and genomes..Nucleic Acids Research372009, D550-D554
12.2 Publications of the year
International journals
Conferences without proceedings
Scientific book chapters
Reports & preprints
Other scientific publications
12.3 Cited publications
- 37 articleGénolevures – a novel approach to ‘evolutionary genomics’.FEBS Letters (complete issue)48712000, URL: https://febs.onlinelibrary.wiley.com/toc/18733468/2000/487/1
- 38 articleTraceability, reproducibility and wiki-exploration for “à-la-carte” reconstructions of genome-scale metabolic models.PLOS Computational Biology1452018, e1006146
- 39 articleRADseq underestimates diversity and introduces genealogical biases due to nonrandom haplotype sampling.Mol. Ecol.22112013, 3179--90
- 40 articleThe Euclidean Distance Matrix Completion Problem.SIAM J. Matrix Anal. App.1621995, 646-654
- 41 articleMetage2Metabo, microbiota-scale metabolic complementarity for the identication of key species.eLife92020, e61968
- 42 articleExploring the Bacterial Impact on Cholesterol Cycle: A Numerical Study.Frontiers in Microbiology112020, 1121
- 43 articleExact Matrix Completion via Convex Optimization.Found. Comput. Math.92009, 717-772
- 44 bookParasitism: The Ecology and Evolution of Intimate Interactions.University of Chicago Press2001
- 45 articleComparative genomics of protoploid Saccharomycetaceae.Genome Research192009, 1696-1709URL: http://hal.inria.fr/inria-00407511/en/
- 46 articleGenome evolution in yeasts.Nature4302004, 35-44URL: http://www.nature.com/nature/journal/v430/n6995/abs/nature02579.html
- 47 articleStructural analysis of expanding metabolic networks..Genome informatics. International Conference on Genome Informatics1512004, 35--45
- 48 articleNonlinear mapping and distance geometry.Optimization Letters142May 2019, 453-467
- 49 techreportTensor Ranks for the Pedestrian for Dimension Reduction and Disentangling Interactions.RR-9445Inrae - BioGeCo ; Inria Bordeaux Sud-OuestDecember 2021
- 50 articleScalable and exhaustive screening of metabolic functions carried out by microbial consortia.Bioinformatics34172018, i934--i943
- 51 articleHybrid metabolic network completion.Theory and Practice of Logic Programming1912019, 83--108
- 52 articleReference-free population genomics from next-generation transcriptome data and the vertebrate-invertebrate gap.PLoS Genetic94e10034572013
- 53 articleClingo = ASP + Control: Preliminary Report.CoRRabs/1405.36942014
- 54 inproceedingsAdvances in gringo Series 3.LPNMR6645Lecture Notes in Computer ScienceSpringer2011, 345---351
- 55 articleA mathematical model to investigate the key drivers of the biogeography of the colon microbiota..Journal of Theoretical Biology46272019, 552-581
- 56 articleEuclidean Distance Geometry and Applications.SIAM review56(1)2014, 3-69
- 57 articleEstimation of Nucleotide Diversity, Disequilibrium Coefficients, and Mutation Rates from High-Coverage Genome-Sequencing Projects.Mol. Biol. Evol.25112008, 2409--19
- 58 articleWhat is flux balance analysis?Nature Biotechnology2832010, 245--248
- 59 articleMeneco, a Topology-Based Gap-Filling Tool Applicable to Degraded Genome-Wide Metabolic Networks.PLOS Computational Biology1312017, e1005276
- 60 articleA comprehensive framework for global patterns in biodiversity.Ecology Letters712004, 1--15URL: http://dx.doi.org/10.1046/j.1461-0248.2003.00554.x
- 61 articleGenolevures complete genomes provide data and tools for comparative genomics of hemiascomycetous yeasts..Nucleic Acids Research34Database issueJanuary 2006, D432-5
- 62 articleGénolevures: protein families and synteny among complete hemiascomycetous yeast proteomes and genomes.Nucleic Acids Research37suppl 12009, D550-D554URL: http://nar.oxfordjournals.org/content/37/suppl_1/D550.abstract
- 63 articleEcology, evolution, and epidemiology of zoonotic and vector-borne infectious diseases in French Guiana: Transdisciplinarity does matter to tackle new emerging threats.Infection, Genetics and Evolution93September 2021, 104916
- 64 articleThe influence of habitat on viral diversity in neotropical rodent hosts.Viruses139August 2021, 1-29