

Section: Software and Platforms
Learning algorithms
KidLearn
Participants : Manuel Lopes [correspondant] , Benjamin Clement, Pierre-Yves Oudeyer, Didier Roy.
The KidLearn software provides and Intelligent Tutoring System that optimizes teaching sequences based on the estimated level of each particular student [65] . We implemented a Game of Money that allows students, ages 7-8, to learn how to use money. It includes 3 main components: i) a webserver that handles the requests and stores the experiments in a databased; ii) a GUI that provides the interface for the game; and iii) the optimization software.
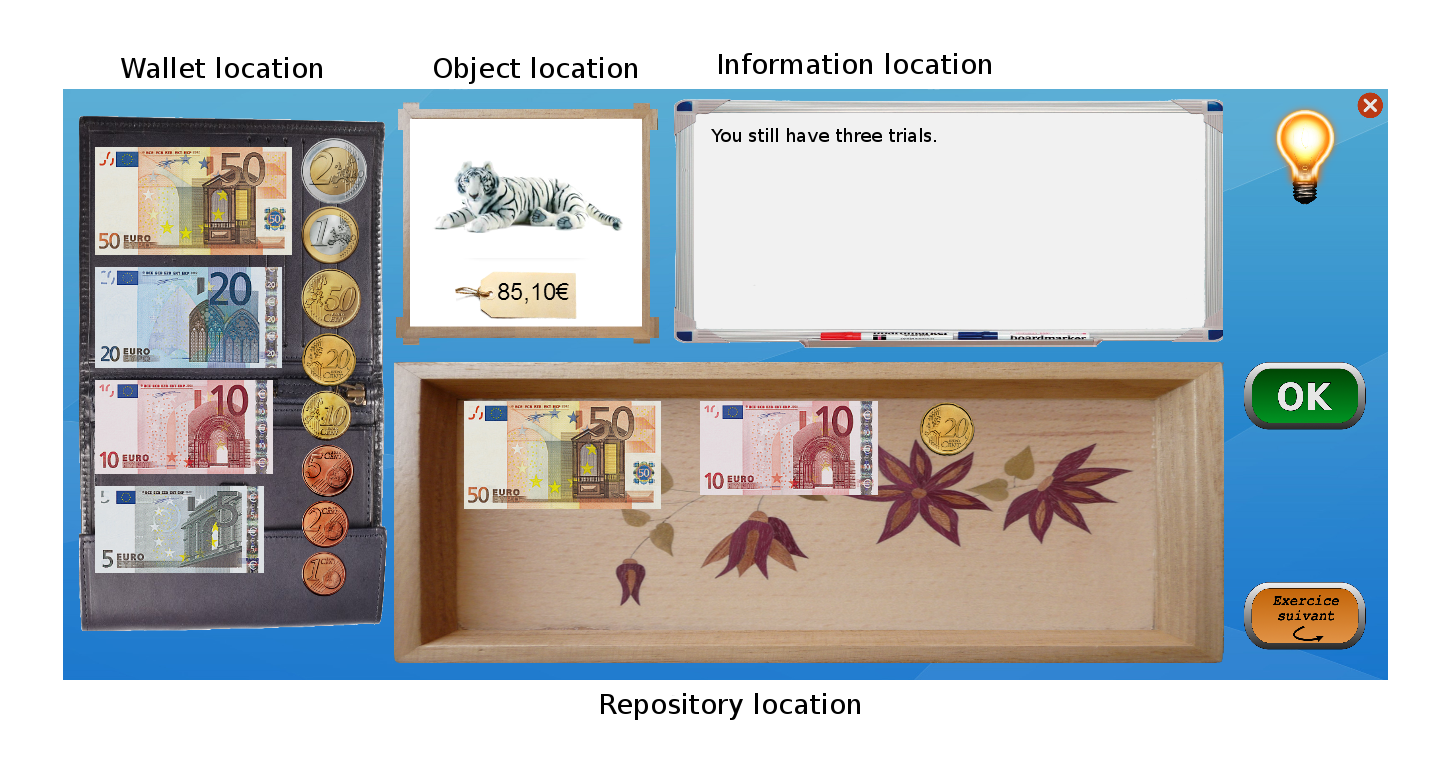
Graphical interfaces in ITS can have unwanted side effects. For this reason, the interface was entirely designed with the help of a didactician, with several specific design choices motivated by pedagogical, motivational and attention requirements. For example, the interface, shown in Figure 5 . is such that:
-
there is no chronometer, so that students are not put under time pressure;
-
coins and banknotes have realistic visual appearance, and their relative sizes are respected;
-
display of prices use visual encodings commonly used in shops;
-
the zone for receiving money is automatically cleared in case of error after the student submits it;
-
automatic snapping of money and tokens icons in the reception zone, and automatic visual arrangement;
Four principal regions are defined in the graphical interface, as shown in Figure 5 . The first is the wallet location where users can pick and drag the money to drop them on the repository location to make for the correct price. The object and the price are present in the object location, where the price can the written and/or spoken depending on the parameterization of the activity. The information location is using to display information for the learners such as extra clues when they make a mistake (for which they have to press the light bulb) and feedback. In order to improve the pedagogical success of the activity, the correct solution is presented automatically to the students if they fail to compose the correct price after 3 trials.
|

RLPark - Reinforcement Learning Algorithms in JAVA
Participant : Thomas Degris [correspondant] .
RLPark is a reinforcement learning framework in Java. RLPark includes learning algorithms, state representations, reinforcement learning architectures, standard benchmark problems, communication interfaces for three robots, a framework for running experiments on clusters, and real-time visualization using Zephyr. More precisely, RLPark includes:
-
Online Learning Algorithms: Sarsa, Expected Sarsa, Q-Learning, On-policy and off-policy Actor-Critic with normal distribution (continuous actions) and Boltzmann distribution (discrete action), average reward actor-critic, TD, TD(), GTD(), GQ(), TDC
-
State Representations: tile coding (with no hashing, hashing and hashing with mumur2), Linear Threshold Unit, observation history, feature normalization, radial basis functions
-
Interface with Robots: the Critterbot, iRobot Create, Nao, Puppy, Dynamixel motors
-
Benchmark Problems: mountain car, swing-up pendulum, random walk, continuous grid world
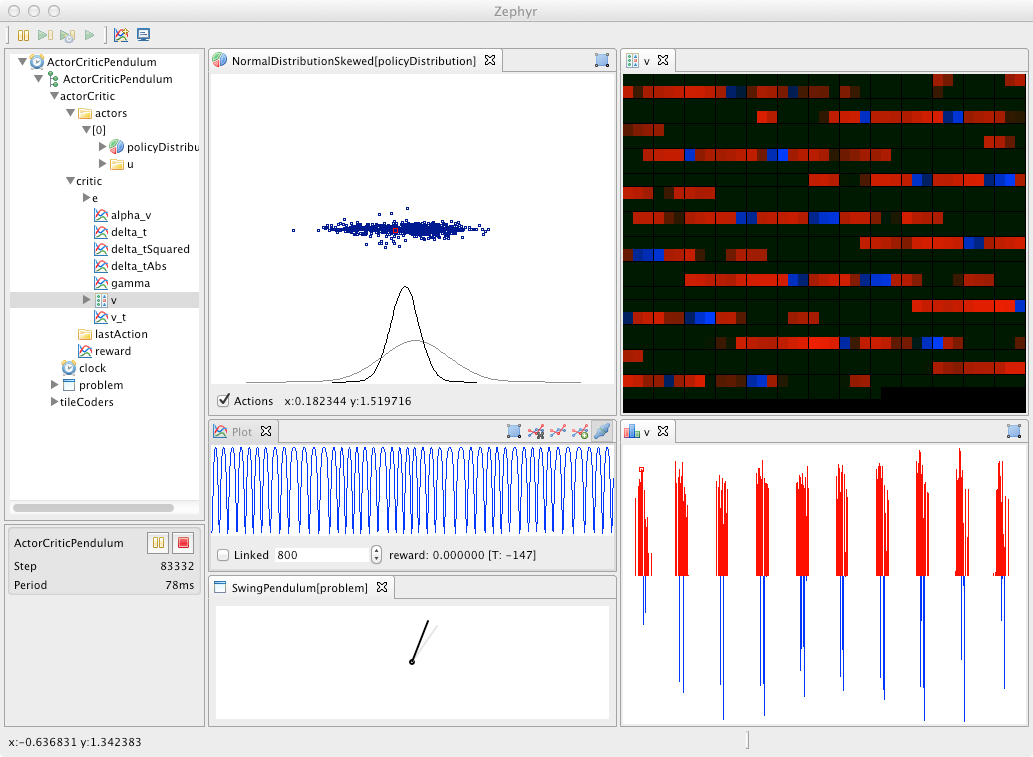
An example of RLpark running an online learning experiment on a reinforcement learning benchmark problem is shown in Figure 6 .
RLPark was started in spring 2009 in the RLAI group at the university of Alberta (Canada) when Thomas Degris was a postdoc in this group. RLPark is still actively used by RLAI. Collaborators and users include Adam White, Joseph Modayil and Patrick Pilarski (testing) from the University of Alberta.
RLPark has been used by Richard Sutton, a professor and iCORE chair in the department of computing science at the University of Alberta, for a demo in his invited talk Learning About Sensorimotor Data at the Neural Information Processing Systems (NIPS) 2011 (http://webdocs.cs.ualberta.ca/~sutton/Talks/Talks.html#sensorimotor ). Patrick Pilarski used RLPark for live demos on television (Breakfast Television Edmonton, CityTV, June 5th, 2012) and at TEDx Edmonton on Intelligent Artificial Limbs(http://www.youtube.com/watch?v=YPc-Ae7zqSo ). So far, RLPark has been used in more than a dozens of publications (see http://rlpark.github.com/publications.html for a list).
RLPark has been ported to C++ by Saminda Abeyruwan, a student of the University of Miami (United States of America). The Horde architecture in RLPark has been optimized for GPU by Clément Gehring, a student of the McGill University in Montreal (Canada).
Future developments include the implementation of additional algorithms (the Dyna architecture, back propagation in neural networks, ...). A paper is under review for the JMLR Machine Learning Open Source Software. Documentation and tutorials are included on the RLPark web site (http://rlpark.github.com ). RLPark is licensed under the open source Eclipse Public License.
|
DMP-BBO Matlab library
Participant : Freek Stulp [correspondant] .
The dmp_bbo (Black-Box Optimization for Dynamic Movement Primitives) Matlab library is a direct consequence of the insight that black-box optimization outperforms reinforcement learning when using policies represented as Dynamic Movement Primitives. It implements several variants of the algorithm for direct policy search. It is currently being used and extended by several FLOWERS members (Manuel Lopes, Clément Moulin-Frier) and external collaborators (Jonas Buchli, Hwangbo Jemin of ETH Zurich). This code was used for the following publications: [130] , [127] , [128] .
Self-calibration BCI - Matlab library
Participants : Jonathan Grizou [correspondant] , Iñaki Iturrate, Luis Montesano, Manuel Lopes, Pierre-Yves Oudeyer.
The Matlab software implements the algorithms described in [45] . It allows a robot to be instructed a new task by a human using communicative signals initially totally unknown to the robot. It is currently extended and improved in the context of EEG-based brain-machine interfaces (BMIs) [44] .
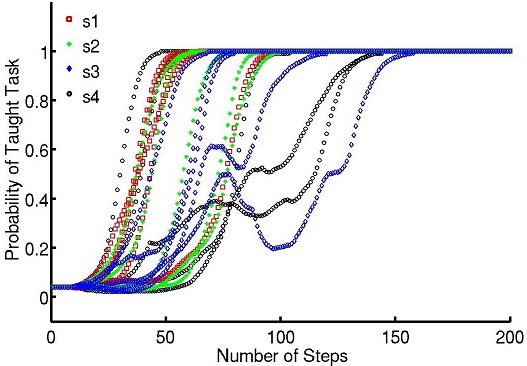
It results in a BCI based control of sequential tasks with feedback signals that do not require any calibration process. As a by-product, the method provides an unsupervised way to train a decoder with the same performance of state-of-the-art supervised classifiers, while keeping the system operational and solving, with a lower performance during the first steps, the unknown task. The algorithm has been tested with online experiments (fig. 7 ), showing that the users were able to guide from scratch an agent to a desired position.
|
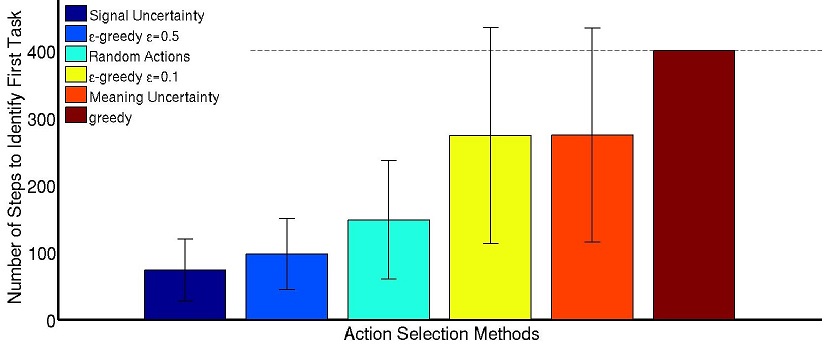
To improve the efficiency of the algorithm, we introduced a new planning method that uses the uncertainty in the signal-target estimation. This planner is inspired by exploration methods with exploration bonuses that allow guiding to reduce the uncertainty in an efficient way. We showed that trying to follow the best hypothesis does not explore the space significantly to reduce uncertainty and thus identify the correct task. Only through an approach that plans how to reduce the uncertainty multiple steps ahead are we sure that the agent will reach states that can only be explained by the correct hypothesis.
|
PROPRE: simulation of developmental concept formation using PYTHON
Participant : Alexander Gepperth [correspondant] .
This simulation software implements the algorithms described in [86] , [83] . It is available online under the URL www.gepperth.net/downloads.html. The simulation is implemented in PYTHON for easy use, yet the time-critical core functions are written in C.
pyStreamPlayer: synchronized replay of multiple sensor recordings and supplementary data
Participant : Alexander Gepperth [correspondant] .
This Python software is intended to facilitate the application of machine learning algorithms by avoiding to work directly with an embodied agent but instead with data recorded in such an agent. Assuming that non-synchronous data from multiple sensors (e.g., camera, Kinect, laser etc.) have been recorded according to a flexible format defined by the pyStreamPlayer architecture, pyStreamPlayer can replay these data while retaining the exact temporal relations between different sensor measurements. As long as the current task does not involve the generation of actions, this software allows to process sensor data as if it was coming from an agent which is usually considerably easier. At the same time, pyStreamPlayer allows to replay arbitrary supplementary information such as, e.g., object information, as if it was coming from a sensor. In this way, supervision information can be stored and accessed together with sensory measurements using an unified interface. pyStreamPlayer has been used to facilitate real-world object recognition tasks, and several of the major databases in this field (CalTech Pedestrian database, HRI RoadTraffic traffic objects database, CVC person database, KITTI traffic objects database) have been converted to the pyStreamPlaer format and now serve as a source of training and test data for learning algorithms.
pyStreamPlayer has been integrated into a ROS node as well, allowing th replay and transmission across networks of distributed processes.
Multimodal: framework around the NMF algorithm for multimodal learning
Participant : Olivier Mangin [correspondant] .
The pyhton code provides a minimum set of tools and associated libraries to reproduce the experiments on [53] , together with the choreography datasets. The code, publicly available at https://github.com/omangin/multimodal , under the new BSD license, is primarily intended for reproduction of the mulimodal learning experiment mentioned above. It is also expected that the public availability of the code encourages further experimentation by other scientists with data coming from other domains, thus increasing both the impact of the aforementioned publication and the knowledge on the algorithm behaviors. The nonnegative matrix factorization algorithm used in the experiments will also soon be included as a third party project to http://scikit-learn.org . Finally the code is currenlty being used by other members of the team and is expected to play an important role in further collaborations.
Tools for curiosity-driven learning on a robotic arm
Participants : Pierre Rouanet [correspondant] , Clément Moulin-Frier.
This library is intended to provide tools for experimenting how curiosity model can facilitate learning of complex tasks such as manipulating objects. First, it provides high-level access to a robotic arm made of dynamixel motors: forward and inverse kinematics, demonstrations recording. Then it wraps the IMLE [77] library which we used for incremental and online learning of the sensorimotor mappings of the robot. Finally, it implements curiosity-driven learning based on the maximization of the learning progress. This modelling is based on recent works by Moulin-Frier and Oudeyer [54] , [56] , [55] proposing a probabilistic algorithmic architecture unifying various principles of developmental robotics such as motor babbling, goal babbling and curiosity-driven exploration. This architecture has already been successfully applied to model infant speech acquisition in the previously cited papers.