

Section: Application Domains
Inverse problems in Neuroimaging
Many problems in neuroimaging can be framed as forward and inverse problems. For instance, the neuroimaging inverse problem consists in predicting individual information (behavior, phenotype) from neuroimaging data, while an important the forward problem consists in fitting neuroimaging data with high-dimensional (e.g. genetic) variables. Solving these problems entails the definition of two terms: a loss that quantifies the goodness of fit of the solution (does the model explain the data reasonably well ?), and a regularization schemes that represents a prior on the expected solution of the problem. In particular some priors enforce some properties of the solutions, such as sparsity, smoothness or being piecewise constant.
Let us detail the model used in the inverse problem: Let be a neuroimaging dataset as an matrix, where and are the number of subjects under study, and the image size respectively, an array of values that represent characteristics of interest in the observed population, written as matrix, where is the number of characteristics that are tested, and an array of shape that represents a set of pattern-specific maps. In the first place, we may consider the columns of independently, yielding problems to be solved in parallel:
where the vector contains is the row of . As the problem is clearly ill-posed, it is naturally handled in a regularized regression framework:
where is an adequate penalization used to regularize the solution:
with . In general, only one or two of these constraints is considered (hence is enforced with a non-zero coefficient):
-
When only (LASSO), and to some extent, when only (elastic net), the optimal solution is (possibly very) sparse, but may not exhibit a proper image structure; it does not fit well with the intuitive concept of a brain map.
-
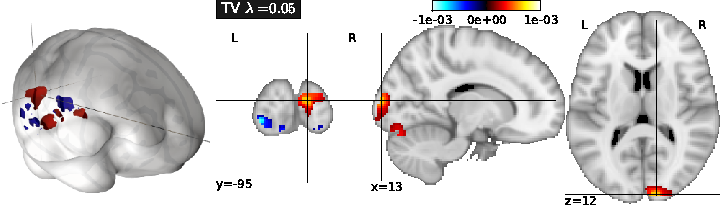
Total Variation regularization (see Fig. 1 ) is obtained for ( only), and typically yields a piecewise constant solution.
-
Smooth lasso is obtained with ( and only), and yields smooth, compactly supported spatial basis functions.
|
The performance of the predictive model can simply be evaluated as the amount of variance in fitted by the model, for each . This can be computed through cross-validation, by learning on some part of the dataset, and then estimating using the remainder of the dataset.
This framework is easily extended by considering
-
Grouped penalization, where the penalization explicitly includes a prior clustering of the features, i.e. voxel-related signals, into given groups. This is particularly important to include external anatomical priors on the relevant solution.
-
Combined penalizations, i.e. a mixture of simple and group-wise penalizations, that allow some variability to fit the data in different populations of subjects, while keeping some common constraints.
-
Logistic regression, where a logistic non-linearity is applied to the linear model so that it yields a probability of classification in a binary classification problem.
-
Robustness to between-subject variability is an important question, as it makes little sense that a learned model depends dramatically on the particular observations used for learning. This is an important issue, as this kind of robustness is somewhat opposite to sparsity requirements.
-
Multi-task learning: if several target variables are thought to be related, it might be useful to constrain the estimated parameter vector to have a shared support across all these variables.
For instance, when one of the variables is not well fitted by the model, the estimation of other variables may provide constraints on the support of and thus, improve the prediction of . Yet this does not impose constraints on the non-zero parameters of the parameters .