

Section: New Results
Lifelong Robot Learning And Development Of Motor And Social Skills
Intrinsically Motivated Multitask Reinforcement Learning
Participants : Sébastien Forestier [correspondant] , Pierre-Yves Oudeyer, Fabien Benureau.
Intrinsically Motivated Exploration of Spaces of Parameterized Skills/Tasks and Application to Robot Tool Learning
A major challenge in robotics is to learn parametrized policies to solve multi-task reinforcement learning problems in high-dimensional continuous action and effect spaces. Of particular interest is the acquisition of inverse models which map a space of sensorimotor problems to a space of motor programs that solve them. For example, this could be a robot learning which movements of the arm and hand can push or throw an object in each of several target locations, or which arm movements allow to produce which displacements of several objects potentially interacting with each other, e.g. in the case of tool use. Specifically, acquiring such repertoires of skills through incremental exploration of the environment has been argued to be a key target for life-long developmental learning [109].
In this work we study algorithms used by a learner to explore high-dimensional structured sensorimotor spaces such as in tool use discovery. We consider goal babbling architectures that were designed to explore and learn solutions to fields of sensorimotor problems, i.e. to acquire inverse models mapping a space of parameterized sensorimotor problems/effects to a corresponding space of parameterized motor primitives. However, so far these architectures have not been used in high-dimensional spaces of effects. Here, we show the limits of existing goal babbling architectures for efficient exploration in such spaces, and introduce a novel exploration architecture called Model Babbling (MB). MB exploits efficiently a modular representation of the space of parameterized problems/effects. We also study an active version of Model Babbling (the MACOB architecture). We compared those architectures in a simulated experimental setup with an arm that can discover and learn how to move objects using two tools with different properties, embedding structured high-dimensional continuous motor and sensory spaces (See Fig. 14).
Transfer Learning through Measures of Behavioral Diversity Generation in Autonomous Exploration
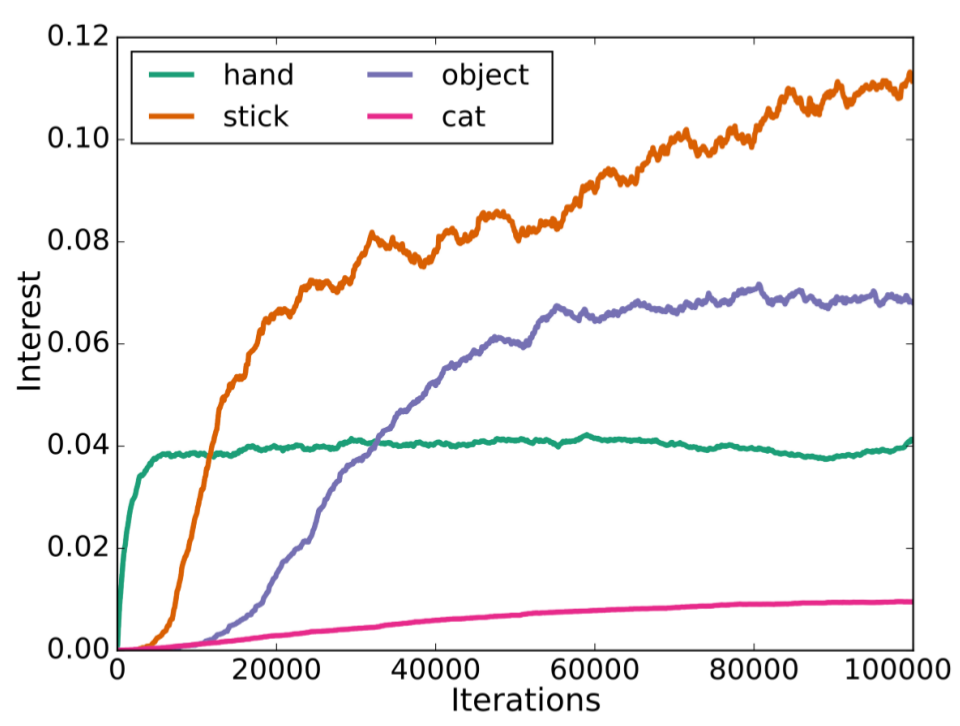
The production of behavioral diversity – producing a diversity of effects – is an essential strategy for robots exploring the world when facing situations where interaction possibilities are unknown or non-obvious. It allows to discover new aspects of the environment that cannot be inferred or deduced from available knowledge. However, creating behavioral diversity in situations where it is most crucial – new and unknown ones – is far from trivial. In particular in large and redundant sensorimotor spaces, only small areas are interesting to explore for any practical purpose. When the environment does not provide clues or gradient toward those areas, trying to discover those areas relies on chance. To address this problem, we introduce a method to create behavioral diversity in a new sensorimotor task by re-enacting actions that allowed to produce behavioral diversity in a previous task, along with a measure that quantifies this diversity. We have shownd that our method can learn how to interact with an object by reusing experience from another, that it adapts to instances of morphological changes and of dissimilarity between tasks, and how scaffolding behaviors can emerge by simply switching the attention of the robot to different parts of the environment. Finally, we show that the method can robustly use simulated experiences and crude cognitive models to generate behavioral diversity in real robots. This work was published in [62].
|
We presented the results at the IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Korea, October 9-14th [81].
Social Learning of Interactive Skills
Participants : Manuel Lopes [correspondant] , Thibaut Munzer, Marc Toussaint, Li Wang Wu, Yoan Mollard, Baptiste Busch, Jonathan Grizou, Marie Demangeat, Freek Stulp.
Relational Activity Processes for Modeling Concurrent Cooperation
In human-robot collaboration, multi-agent domains, or single-robot manipulation with multiple end-effectors, the activities of the involved parties are naturally concurrent. Such domains are also naturally relational as they involve objects, multiple agents, and models should generalize over objects and agents. We propose a novel formalization of relational concurrent activity processes that allows us to transfer methods from standard relational MDPs, such as MonteCarlo planning and learning from demonstration, to concurrent cooperation domains. We formally compare the formulation to previous propositional models of concurrent decision making and demonstrate planning and learning from demonstration methods on a real-world human-robot assembly task. A paper summarizing this research has been publish to the International Conference on Robotics and Automation (ICRA) 2016 [84].
Interactive Behavior Learning for Cooperative Tasks
This work goal is to propose a method to learn cooperative behavior to solve a task while performing the task with the user. The proposed approach reuses previous work on learning policy for RAP. The main differences are: i) formulate the problem as a cooperative process. In MDP and RAP, it is assumed that there is one central decision maker. However, in a cooperative both the robot and the operator are taking decisions. ii) estimating the confidence. A Query by Bagging approach has been used where many policies are learned from a subset of the data. Their potential disagreement allows quantifying the confidence. iii) Using the confidence for autonomous acting and for query making. Based on the confidence, the robot either act before acting or ask confirmation before acting.

Results show that using an interactive approach require less instruction from the user while producing a policy that makes fewer mistakes. We developed a robotic implementation 15 using a Baxter robot. A first article resulting from this work focusing on interactive preferences learning have been submitted to the International Conference on Robotics and Automation (ICRA) 2017 and a video demonstration can be view at : https://vimeo.com/182913540. A broader journal article is in preparation. We also conducted a user study to evaluate the impact of interactive learning on naïve users acceptation and performances.
Legible Motion
In a human-robot collaboration context, understanding and anticipating the robot intentions ease the completion of a joint-task. Whereas previous work has sought to explicitly optimize the legibility of behavior, we investigate legibility as a property that arises automatically from general requirements on the efficiency and robustness of joint human-robot task completion.
Following our previous work on legibility of robot motions [56], we have conducted several user experiments to analyze the effects of the policy representation on the universality of the legibility.
This work lead to a submission of a journal article to the International Journal of Social Robotics (IJSR) under the special issue: Towards a Framework for Joint Action. The article has been accepted with minor revisions and is currently in the final stage of the review process.
Postural optimization for a safe and comfortable human-robot interaction
When we, humans, accomplish a task our body posture is (partially) constrained. For example, acting on an object constrains the pose of the hand relatively to the object, and the head faces the object we are acting upon. But due to the large number of degrees of freedom (DOF) of the human body, other body parts are unconstrained and several body postures are viable with respect to the task. However, not all of them are viable in terms of ergonomics. Using a personalized human model, observational postural assessment techniques can be automatized. Optimizing the model body posture is then the logical next step to find an ergonomically correct posture for the worker to accomplish a specific task.
To optimize the subject's model to achieve a specific task, we define an objective function that minimizes the efforts of the whole body posture, based on the Rapid Entire Body Assessment (REBA) technique [135]. The objective function also account for visibility of the target object and worker's laterality. We have also implemented an automatic assessment of the worker's body posture based on the REBA method.
Using a spherical object, carried by a Baxter humanoid robot as illustrated in Fig. 16, we mimic an industrial scenario where the robot helps the worker by positioning and orienting an object in which the worker has to insert specific shapes. In a user-study with forty participants, we compare three different robot's behaviors, one of them being the result of the postural optimization of the subject's personalized model. By the mean of a survey session, and the online assessment of the subject's posture during the interaction, we prove that our method leads to a safer posture, and is perceived as more comfortable.
This work has been submitted to the IEEE Robotics and Automation Letters (RA-L) with the ICRA conference option and is currently under review.
|
