

Section: New Results
Graphics with Uncertainty and Heterogeneous Content
Cotemporal Multi-View Video Segmentation
Participants : Abdelaziz Djelouah, George Drettakis.
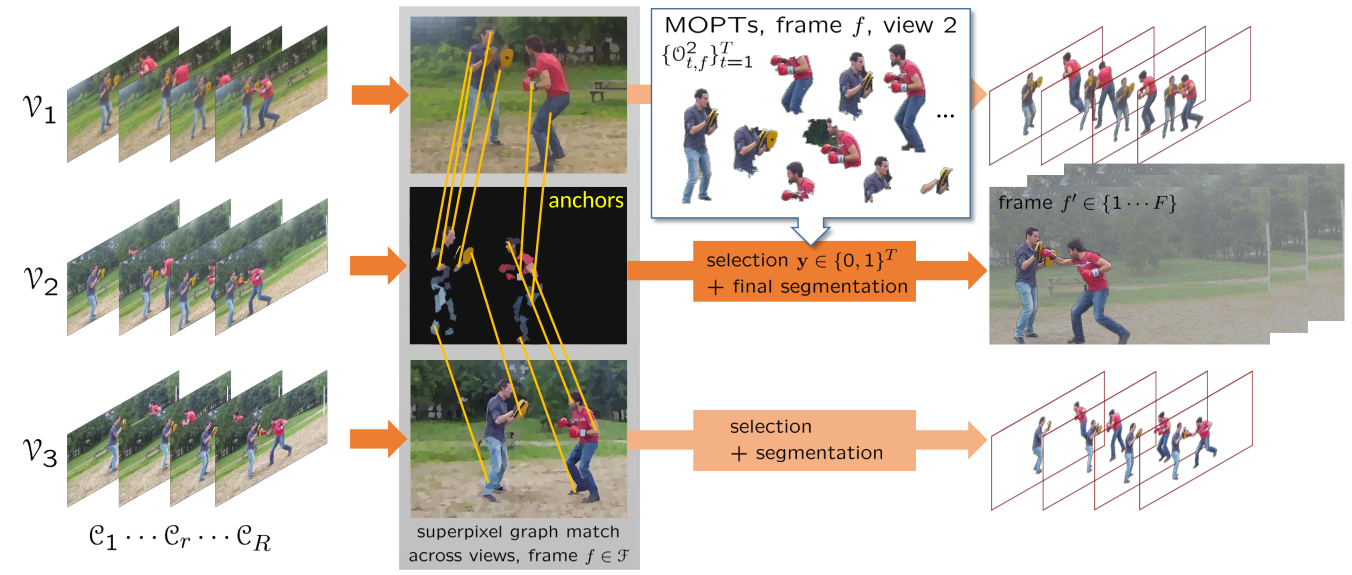
We address the problem of multi-view video segmentation of dynamic scenes in general and outdoor environments with possibly moving cameras. Multi-view methods for dynamic scenes usually rely on geometric calibration to impose spatial shape constraints between viewpoints. In this work, we show that the calibration constraint can be relaxed while still getting competitive segmentation results using multi-view constraints. We introduce new multi-view cotemporality constraints through motion correlation cues, in addition to common appearance features used by cosegmentation methods to identify co-instances of objects. We also take advantage of learning based segmentation strategies by casting the problem as the selection of monocular proposals that satisfy multi-view constraints. This yields a fully automated method that can segment subjects of interest without any particular pre-processing stage (see Fig. 9). Results on several challenging outdoor datasets demonstrate the feasibility and robustness of our approach.
This work is a collaboration with Jean-Sébastien Franco and Edmond Boyer from Morpheo team at Inria Grenoble, and Patrick Pérez from Technicolor. The work has been published in the International Conference on 3D Vision (3DV) - 2016 [10].
|
Automatic 3D Car Model Alignment for Mixed Image-Based Rendering
Participants : Rodrigo Ortiz Cayon, Abdelaziz Djelouah, George Drettakis.
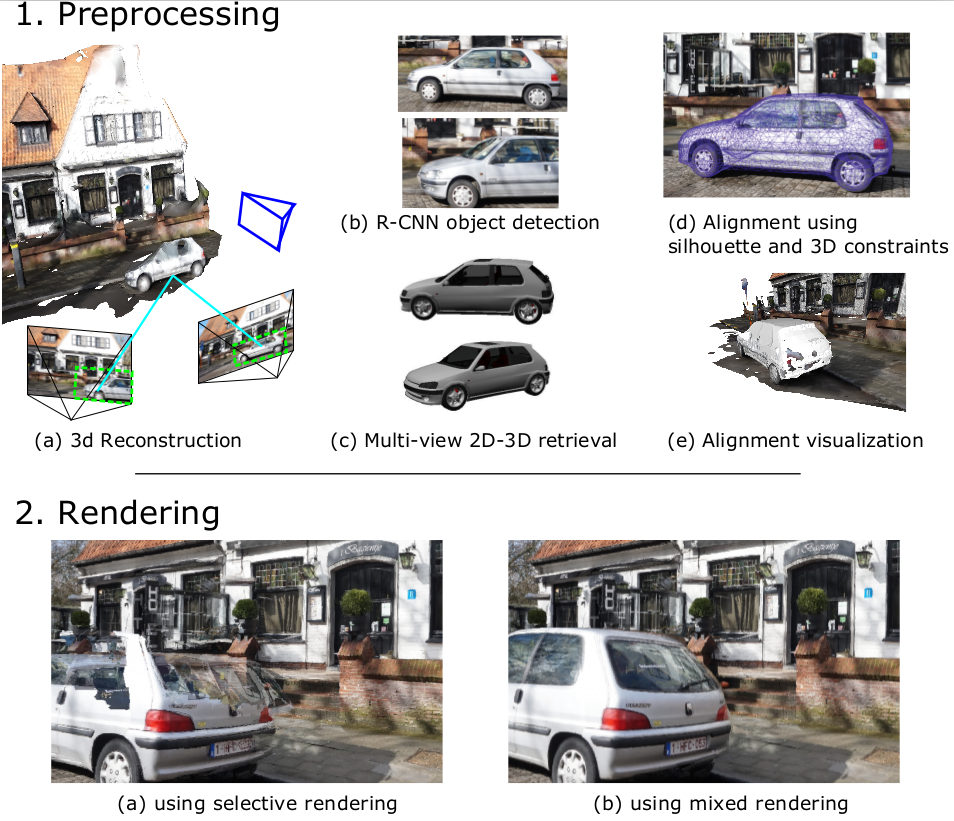
We present a method that improves quality of Image-Based Rendering of poorly reconstructed objects. We focus on the case of reflective objects which are hard to reconstruct, such as cars. The key insight is to replace these poorly reconstructed objects with models from existing rich 3D CAD databases, and subsequently align them to the input images. We use deep learning-based algorithms to obtain the 3D model present in the databases which is closest to the object seen in the images. We formulate two optimizations using all available information to finely position and orient the model and adapt it to image contours (see Fig. 10(1.)). Our method provides much higher quality rendering results of such objects compared to previous solutions as seen in Fig. 10(2.(b)).
This work is a collaboration with Francisco Massa and Mathieu Aubry from École des Ponts ParisTech. The work was published in the International Conference in 3D Vision (3DV) - 2016 [12].
Multi-View Inpainting for Image-Based Scene Editing and Rendering
Participants : Theo Thonat, George Drettakis.
We propose a method to remove objects such as people and cars from multi-view urban image datasets (Figure 11), enabling free-viewpoint Image-Based Rendering (IBR) in the edited scenes. Our method combines information from multi-view 3D reconstruction with image inpainting techniques, by formulating the problem as an optimization of a global patch-based objective function. We use IBR techniques to reproject information from neighboring views, and 3D multi-view stereo reconstruction to perform multi-view coherent initialization for inpainting of pixels not filled by reprojection. Our algorithm performs multi-view consistent inpainting for color and 3D by blending reprojections with patch-based image inpainting. We run our algorithm on casually captured datasets, and Google Street View data, removing objects such as cars, people and pillars, showing that our approach produces results of sufficient quality for free-viewpoint IBR on “cleaned up” scenes, as well as IBR scene editing, such as limited displacement of real objects.
This work is a collaboration with Eli Shechtman and Sylvain Paris from Adobe Research. It has been published in the International Conference on 3D Vision (3DV) - 2016 [13].
|

Gaze Prediction using Machine Learning for Dynamic Stereo Manipulation in Games
Participants : George Koulieris, George Drettakis.
Comfortable, high-quality 3D stereo viewing has become a requirement for interactive applications. Previous research shows that manipulating disparity can alleviate some of the discomfort caused by 3D stereo, but it is best to do this locally, around the object the user is gazing at. The main challenge is thus to develop a gaze predictor in the demanding context of real-time, heavily task-oriented applications such as games. Our key observation is that player actions are highly correlated with the present state of a game, encoded by game variables. Based on this, we trained a classifier to learn these correlations using an eye-tracker which provides the ground-truth object being looked at. The classifier is used at runtime to predict object category – and thus gaze – during game play, based on the current state of game variables. We used this prediction to propose a dynamic disparity manipulation method, which provided rich and comfortable depth. We evaluated the quality of our gaze predictor numerically and experimentally, showing that it predicts gaze more accurately than previous approaches. A subjective rating study demonstrates that our localized disparity manipulation is preferred over previous methods.
This work is a collaboration with Katerina Mania from the Technical University of Crete and Douglas Cunningham from the Technical University of Cottbus. The work was presented at the IEEE conference for Virtual Reality (IEEE VR) 2016 [14].
|

A Feasibility Study with Image-Based Rendered Virtual Reality in Patients with Mild Cognitive Impairment
Participant : George Drettakis.
Virtual Reality (VR) has emerged as a promising tool in many domains of therapy and rehabilitation, and has recently attracted the attention of researchers and clinicians working with elderly people with MCI, Alzheimer's disease and related disorders. In this study we tested the feasibility of using highly realistic image-based rendered VR with patients with MCI and dementia. We designed an attentional task to train selective and sustained attention, and we tested a VR and a paper version of this task (see Fig. 13) in a single-session within-subjects design. Results showed that participants with MCI and dementia reported to be highly satisfied and interested in the task, and they reported high feelings of security, low discomfort, anxiety and fatigue. In addition, participants reported a preference for the VR condition compared to the paper condition, even if the task was more difficult. Interestingly, apathetic participants showed a preference for the VR condition stronger than that of non-apathetic participants. These findings suggest that VR-based training can be considered as an interesting tool to improve adherence to cognitive training for elderly people with cognitive impairment.
This work was a collaboration with EA CoBTek/IA, CMRR (memory center) of the CHU (University Hospital) of Nice, Disney Research and Trinity College Dublin, as part of the (completed) VERVE EU project. The work was published in the PLoS ONE journal [7].

Scalable Inside-Out Image-Based Rendering
Participant : George Drettakis.
The goal of this project was to provide high-quality free-viewpoing rendering of indoors environments. captured with off-the-shelf equipment such as a high-quality color camera and a commodity depth sensor. Image-based Rendering (IBR) can provide the realistic imagery required at real-time speed. For indoor scenes however, two challenges are especially prominent. First, the reconstructed 3D geometry must be compact, but faithful enough to respect occlusion relationships when viewed up close. Second, man-made materials call for view-dependent texturing, but using too many input photographs reduces performance.
We customize a typical RGB-D 3D surface reconstruction pipeline to produce a coarse global 3D surface, and local, per-view geometry for each input image. Our tiled IBR preserves quality by economizing on the expected contributions that entire groups of input pixels make to a final image. The two components are designed to work together, giving real-time performance, while hardly sacrificing quality. Testing on a variety of challenging scenes shows that our inside-out IBR scales favorably with the number of input images.
This work was a collaboration with P. Hedman, G. Brostow and T. Ritschel at UCL, as part of the CR-PLAY project. It was published in ACM Transactions on Graphics (Proc. SIGGRAPH Asia) [6].
|

Measuring Accommodation and Comfort in Head-Mounted Displays
Participants : George Koulieris, George Drettakis.
Head-mounted displays (HMDs) are rapidly becoming the preferred display for stereo viewing in virtual environments, but they often cause discomfort and even sickness. Previous studies have shown that a major cause of these adverse symptoms is the vergence-accommodation (VA) conflict. Specifically, the eyes use the distance to the screen to accommodate, while they use the distance to the fixated virtual object to converge. The VA conflict is the difference between those distances. The magnitude of the conflict is well correlated with subjective reports of discomfort. Many methods have been proposed for reducing the VA conflict and thereby reducing discomfort by making accommodation more consistent with vergence. But no one has actually measured accommodation in HMDs to see how well a given method is able to drive it to the desired distance. We built the first device for measuring accommodation in an HMD, using a modular design with off-the-shelf components, focus-adjustable lenses, and an autorefractor. We conducted experiments using the device to determine how well accommodation is driven with various combinations of HMD properties and viewing conditions: focus-adjustable lenses, depth-of-field rendering, binocular viewing, and “monovision" (setting the two eyes' focal distances to quite different values). We found that focus-adjustable lenses drive accommodation appropriately across many conditions. The other techniques were much less effective in driving accommodation. We also investigated whether the ability to drive accommodation predicts viewer comfort. We did this by conducting a discomfort study with most of the conditions in the accommodation study. We found that the ability to drive accommodation did in fact predict the amount of discomfort. Specifically, the most comfortable conditions were the ones that generated accommodation consistent with vergence. Together, these results illustrate the potential benefit of focus-adjustable lenses: They enable stimulation of accommodation and thereby comfortable viewing. In contrast, monovision neither enable accurate accommodation nor comfortable viewing.
This work is an ongoing collaboration with Martin S. Banks from UC Berkeley, in the context of the CRISP Inria associate team.
Beyond Gaussian Noise-Based Texture Synthesis
Participants : Kenneth Vanhoey, Georgios Kopanas, George Drettakis.
Texture synthesis methods based on noise functions have many nice properties: they are continuous (thus resolution-independent), infinite (can be evaluated at any point) and compact (only functional parameters need to be stored). A good method is also non-repetitive and aperiodic. Current techniques, like Gabor Noise, fail to produce structured content. They are limited to so-called “Gaussian textures”, characterized by second-order statistics like mean and variance only. This is suitable for noise-like patterns (e.g., marble, wood veins, sand) but not for structured ones (e.g., brick wall, mountain rocks, woven yarn). Other techniques, like Local Random-Phase noise, leverage some structure but as a trade-off with repetitiveness and periodicity.
In this project, we model higher-order statistics produced by noise functions in a parametric model. Then we define an algorithm for sampling of the noise functions' parameters so as to produce a texture that meets prescribed statistics. This sampling ensures both the reproduction of higher-order visual features with high probability, like edges and ridges, and non-repetitiveness plus aperiodicity thanks to the stochastic sampling method. Moreover a (deep) learning algorithm has been established to infer the prescribed statistics from an input examplar image.
This project is a collaboration with Ian H. Jermyn (Durham University, UK, former Inria) and Mathieu Aubry (ENPC, France).
Fences in Image Based Rendering
Participants : Abdelaziz Djelouah, Frederic Durand, George Drettakis.
One of the key problem in Image Based Rendering (IBR) methods is the rendering of regions with incorrect 3D reconstruction. Some methods try to overcome the issue in the case of reflections and transparencies trough the estimation of two planes or the usage of 3D stock models. Fences with their thin repetitive structures are another important common source of 3D reconstruction errors but have received very little attention in the context of image based rendering. They are present in most urban pictures and represent a standard failure case for reconstruction algorithms, and state of the art rendering methods exhibit strong artifacts.
In this project, we propose to detect and segment fences in urban pictures for IBR applications. Similarly to related methods in image de-fencing, we use the assumptions that fences are thin repetitive structures lying on a 3D plane. To address this problem we consider the following steps: First we propose a multi-view approach to estimate the plane supporting the fences using repetition candidates. Second, we estimate image matting taking advantage of the multi-view constraints and the repetitive patterns. Finally, the estimated 3D plane and matting masks are used in a new rendering algorithm.
Handling reflections in Image-Based Rendering
Participants : Theo Thonat, Frederic Durand, George Drettakis.
In order to render new viewpoints, current Image Based Rendering techniques (IBR) use an approximate geometry to warp and blend photographs from close viewpoints. They assume the scene materials are diffuse, so geometry colors are independent of the viewpoint, an assumption that fails in the case of specular surfaces such as windows. Dealing with reflections in an IBR context first requires identifying what are the diffuse and the specular color layers in the input images. The challenge is then to correctly warp the specular layers since their associated geometry is not available and since the normals of the reflective surfaces might be not reliable.