Section: New Results
Visual recognition in images
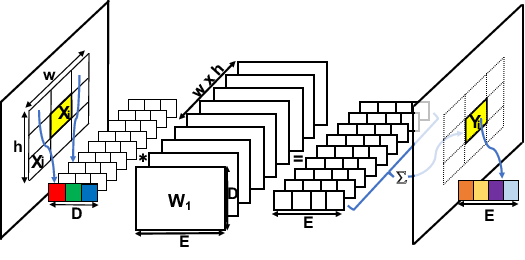
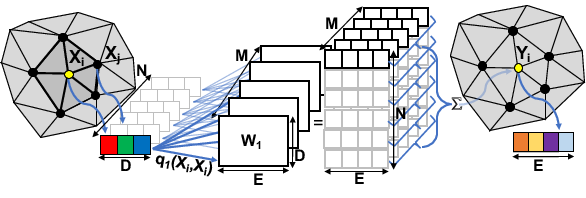
Dynamic Filters in Graph Convolutional Networks
Participants : Nitika Verma, Edmond Boyer [MORPHEO, Inria Grenoble] , Jakob Verbeek.
Convolutional neural networks (CNNs) have massively impacted visual recognition in 2D images, and are now ubiquitous in state-of-the-art approaches. While CNNs naturally extend to other domains, such as audio and video, where data is also organized in rectangular grids, they do not easily generalize to other types of data such as 3D shape meshes, social network graphs or molecular graphs. In our recent paper [39], we propose a novel graph-convolutional network architecture to handle such data. The architecture builds on a generic formulation that relaxes the 1-to-1 correspondence between filter weights and data elements around the center of the convolution, see Figure 1 for an illustration. The main novelty of our architecture is that the shape of the filter is a function of the features in the previous network layer, which is learned as an integral part of the neural network. Experimental evaluations on digit recognition, semi-supervised document classification, and 3D shape correspondence yield state-of-the-art results, significantly improving over previous work for shape correspondence.
|
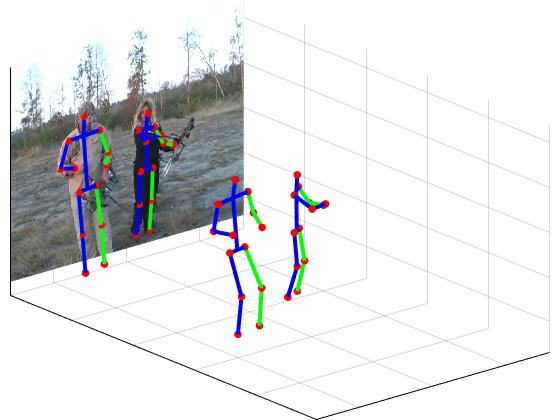
LCR-Net: Localization-Classification-Regression for Human Pose
Participants : Grégory Rogez, Philippe Weinzaepfel, Cordelia Schmid.
In this paper [24], we propose an end-to-end architecture for joint 2D and 3D human pose estimation in natural images. Key to our approach is the generation and scoring of a number of pose proposals per image, which allows us to predict 2D and 3D pose of multiple people simultaneously. See example in Figure 2. Hence, our approach does not require an approximate localization of the humans for initialization. Our architecture, named LCR-Net, contains 3 main components: 1) the pose proposal generator that suggests potential poses at different locations in the image; 2) a classifier that scores the different pose proposals ; and 3) a regressor that refines pose proposals both in 2D and 3D. All three stages share the convolutional feature layers and are trained jointly. The final pose estimation is obtained by integrating over neighboring pose hypotheses , which is shown to improve over a standard non maximum suppression algorithm. Our approach significantly outperforms the state of the art in 3D pose estimation on Human3.6M, a controlled environment. Moreover, it shows promising results on real images for both single and multi-person subsets of the MPII 2D pose benchmark.
|
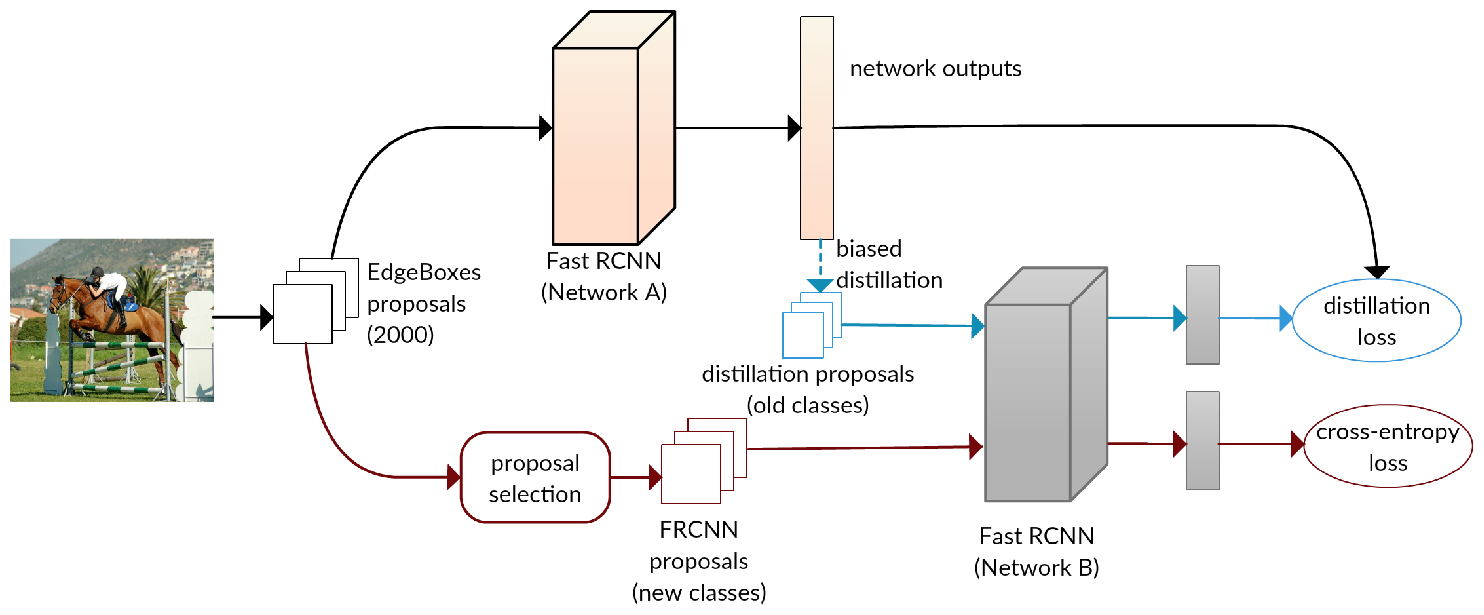
Incremental Learning of Object Detectors without Catastrophic Forgetting
Participants : Konstantin Shmelkov, Cordelia Schmid, Karteek Alahari.
In the paper [25] we introduce a framework for incremental learning of object detectors based on convolutional neural networks, i.e., adapting the original model trained on a set of classes to additionally detect objects of new classes, in the absence of the initial training data. They suffer from “catastrophic forgetting”—an abrupt degradation of performance on the original set of classes, when the training objective is adapted to the new classes. We present a method to address this issue, and learn object detectors incrementally, when neither the original training data nor annotations for the original classes in the new training set are available. The core of our proposed solution is a loss function to balance the interplay between predictions on the new classes and a new distillation loss which minimizes the discrepancy between responses for old classes from the original and the updated networks (see Figure 3). This incremental learning can be performed multiple times, for a new set of classes in each step, with a moderate drop in performance compared to the baseline network trained on the ensemble of data. We present object detection results on the PASCAL VOC 2007 and COCO datasets, along with a detailed empirical analysis of the approach.
|
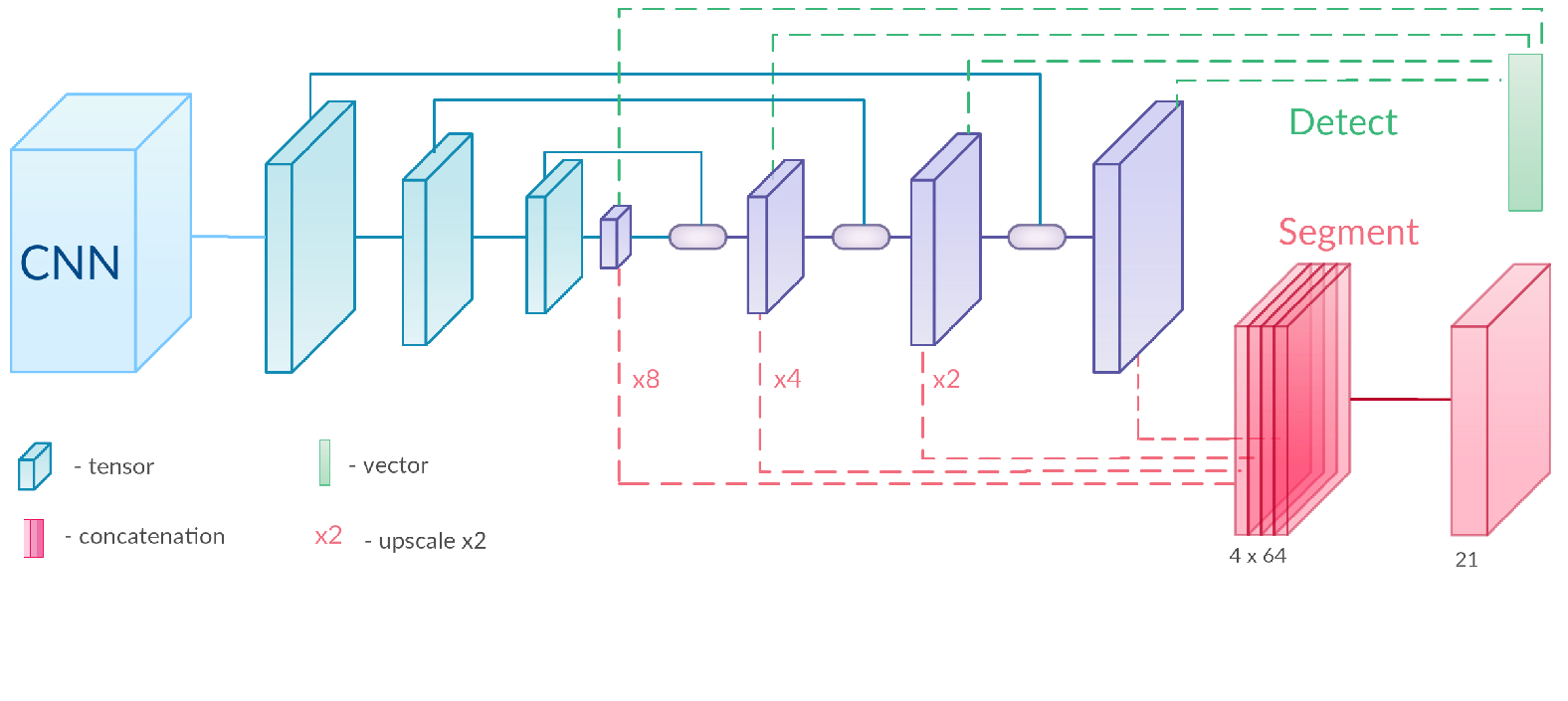
BlitzNet: A Real-Time Deep Network for Scene Understanding
Participants : Mikita Dvornik, Konstantin Shmelkov, Julien Mairal, Cordelia Schmid.
Real-time scene understanding has become crucial in many applications such as autonomous driving. In this work [16], we propose a deep architecture, called BlitzNet, that jointly performs object detection and semantic segmentation in one forward pass, allowing real-time computations. Besides the computational gain of having a single network to perform several tasks, we show that object detection and semantic segmentation benefit from each other in terms of accuracy. Experimental results for VOC and COCO datasets show state-of-the-art performance for object detection and segmentation among real time systems.
To achieve these goals we designed a novel architecture (see fig.4 that naturally suits well for each of the tasks by allowing embedding of precise local details and reach global semantical information in a single feature-space. This solution allows to better localize and segment small objects. The usage of common architecture for both tasks allows more efficient feature sharing and and a simple training procedure that introduces benefits for semantic segmentation by adding extra data with only bounding box annotations. To reduce the computational overhead introduced by the upscale stream we slightly modify the NMS procedure to speed up post-processing in test time without no effect on detection accuracy.
|
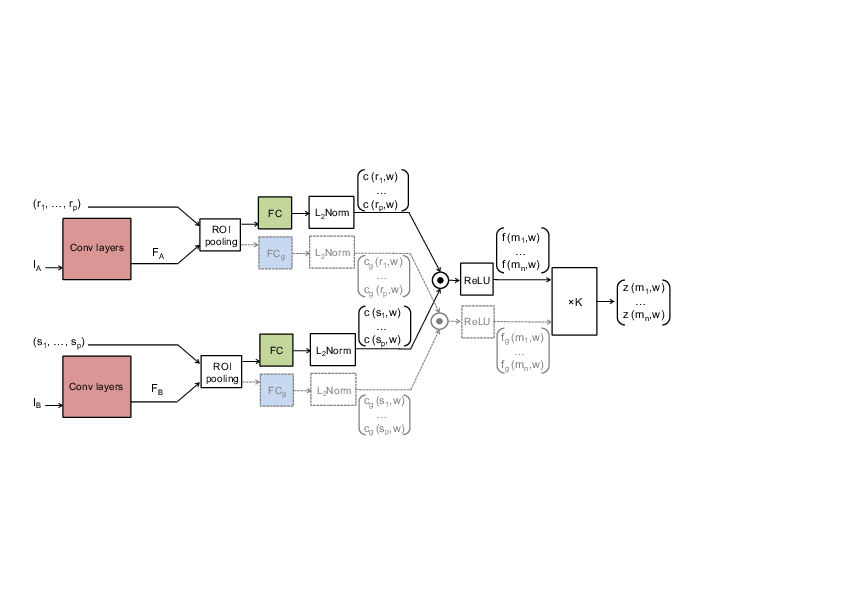
SCNet: Learning semantic correspondence
Participants : Kai Han, Rafael Rezende, Bumsub Ham, Kwan-Yee Wong, Minsu Cho, Cordelia Schmid, Jean Ponce.
In this work [17], we propose a convolutional neural network architecture, called SCNet, for learning a geometrically plausible model for establishing semantic correspondence between images depicting different instances of the same object or scene category. SCNet uses region proposals as matching primitives, and explicitly incorporates geometric consistency in its loss function. An overview of the architecture can by seen in Figure 5. It is trained on image pairs obtained from the PASCAL VOC 2007 keypoint dataset, and a comparative evaluation on several standard benchmarks demonstrates that the proposed approach substantially outperforms both recent deep learning architectures and previous methods based on hand-crafted features.
|
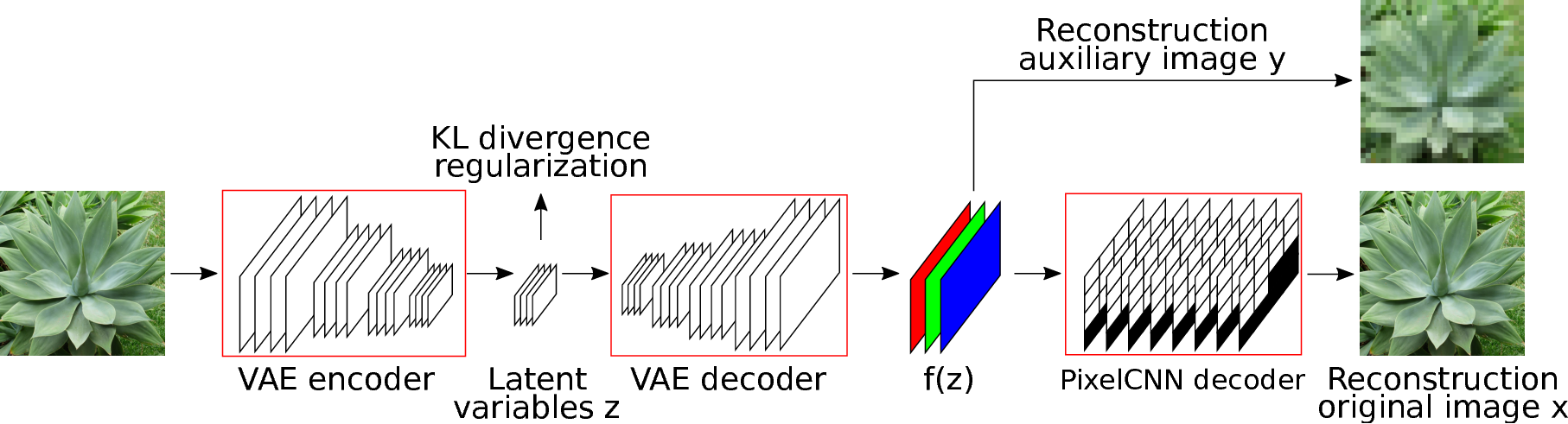
Auxiliary Guided Autoregressive Variational Autoencoders
Participants : Thomas Lucas, Jakob Verbeek.
Generative modeling of high-dimensional data is a key problem in machine learning. Successful approaches include latent variable models and autoregressive models. The complementary strengths of these approaches, to model global and local image statistics respectively, suggest hybrid models combining the strengths of both. Our contribution is to train such hybrid models using an auxiliary loss function that controls which information is captured by the latent variables and what is left to the autoregressive decoder, as illustrated in Figure 6 . In contrast, prior work on such hybrid models needed to limit the capacity of the autoregressive decoder to prevent degenerate models that ignore the latent variables and only rely on autoregressive modeling. Our approach results in models with meaningful latent variable representations, and which rely on powerful autoregressive decoders to model image details. Our model generates qualitatively convincing samples, and yields state-of-the-art quantitative results.
|
Areas of Attention for Image Captioning
Participants : Marco Pedersoli, Thomas Lucas, Jakob Verbeek.
We propose “Areas of Attention”, a novel attention-based model for automatic image captioning. Our approach models the dependencies between image regions, caption words, and the state of an RNN language model, using three pairwise interactions. In contrast to previous attention-based approaches that associate image regions only to the RNN state, our method allows a direct association between caption words and image regions. During training these associations are inferred from image-level captions, akin to weakly-supervised object detector training. These associations help to improve captioning by localizing the corresponding regions during testing. We also propose and compare different ways of generating attention areas: CNN activation grids, object proposals, and spatial transformers nets applied in a convolutional fashion, as illustrated in Figure 7. Spatial transformers give the best results. They allow for image specific attention areas, and can be trained jointly with the rest of the network. Our attention mechanism and spatial transformer attention areas together yield state-of-the-art results on the MSCOCO dataset.
|

Enhancing Energy Minimization Framework for Scene Text Recognition with Top-Down Cues
Participants : Anand Mishra, Karteek Alahari, C. v. Jawahar.
Color and strokes are the salient features of text regions in an image. In this work, presented in [10], we use both these features as cues, and introduce a novel energy function to formulate the text binarization problem. The minimum of this energy function corresponds to the optimal binarization. We minimize the energy function with an iterative graph cut based algorithm. Our model is robust to variations in foreground and background as we learn Gaussian mixture models for color and strokes in each iteration of the graph cut. We show results on word images from the challenging ICDAR 2003/2011, born-digital image and street view text datasets, as well as full scene images containing text from ICDAR 2013 datasets, such as the ones shown in Figure 8, and compare our performance with state-of-the-art methods. Our approach shows significant improvements in performance under a variety of performance measures commonly used to assess text binarization schemes. In addition, our method adapts to diverse document images, like text in videos, handwritten text images.
|

Learning deep face representations using small data
Participants : Guosheng Hu, Xiaojiang Peng [Hengyang Normal University, China] , Yongxin Yang [Queen Mary University of London, UK] , Timothy Hospedales [University of Edinburgh, UK] , Jakob Verbeek.
Deep convolutional neural networks have recently proven extremely effective for difficult face recognition problems in uncontrolled settings. To train such networks very large training sets are needed with millions of labeled images. For some applications, such as near-infrared (NIR) face recognition, such large training datasets are, however, not publicly available and very difficult to collect. In our recent paper [8] we propose a method to generate very large training datasets of synthetic images by compositing real face images in a given dataset. Our approach replaces facial parts (nose, mouth, eyes) from one face with those of another, see Figure 9 for several examples. We show that this method enables to learn models from as few as 10,000 training images, which perform on par with models trained from 500,000 images without using our data augmentation. Using our approach we also improve the state-of-the-art results on the CASIA NIR-VIS heterogeneous face recognition dataset.
|

Invariance and Stability of Deep Convolutional Representations
Participants : Alberto Bietti, Julien Mairal.
In [13] and [29], we study deep signal representations that are near-invariant to groups of transformations and stable to the action of diffeomorphisms without losing signal information. This is achieved by generalizing the multilayer kernel introduced in the context of convolutional kernel networks and by studying the geometry of the corresponding reproducing kernel Hilbert space. We show that the signal representation is stable, and that models from this functional space, such as a large class of convolutional neural networks, may enjoy the same stability.
Weakly-supervised learning of visual relations
Participants : Julia Peyre, Ivan Laptev, Cordelia Schmid, Josef Sivic.
This work [23] introduces a novel approach for modeling visual relations between pairs of objects. We call relation a triplet of the form where the predicate is typically a preposition (eg. 'under', 'in front of') or a verb ('hold', 'ride') that links a pair of objects . Learning such relations is challenging as the objects have different spatial configurations and appearances depending on the relation in which they occur. Another major challenge comes from the difficulty to get annotations, especially at box-level, for all possible triplets, which makes both learning and evaluation difficult. The contributions of this paper are threefold. First, we design strong yet flexible visual features that encode the appearance and spatial configuration for pairs of objects. Second, we propose a weakly-supervised discriminative clustering model to learn relations from image-level labels only. Third we introduce a new challenging dataset of unusual relations (UnRel) together with an exhaustive annotation, that enables accurate evaluation of visual relation retrieval. We show experimentally that our model results in state-of-the-art results on the visual relationship dataset significantly improving performance on previously unseen relations (zero-shot learning), and confirm this observation on our newly introduced UnRel dataset. Example results are shown in Figure 10.
|

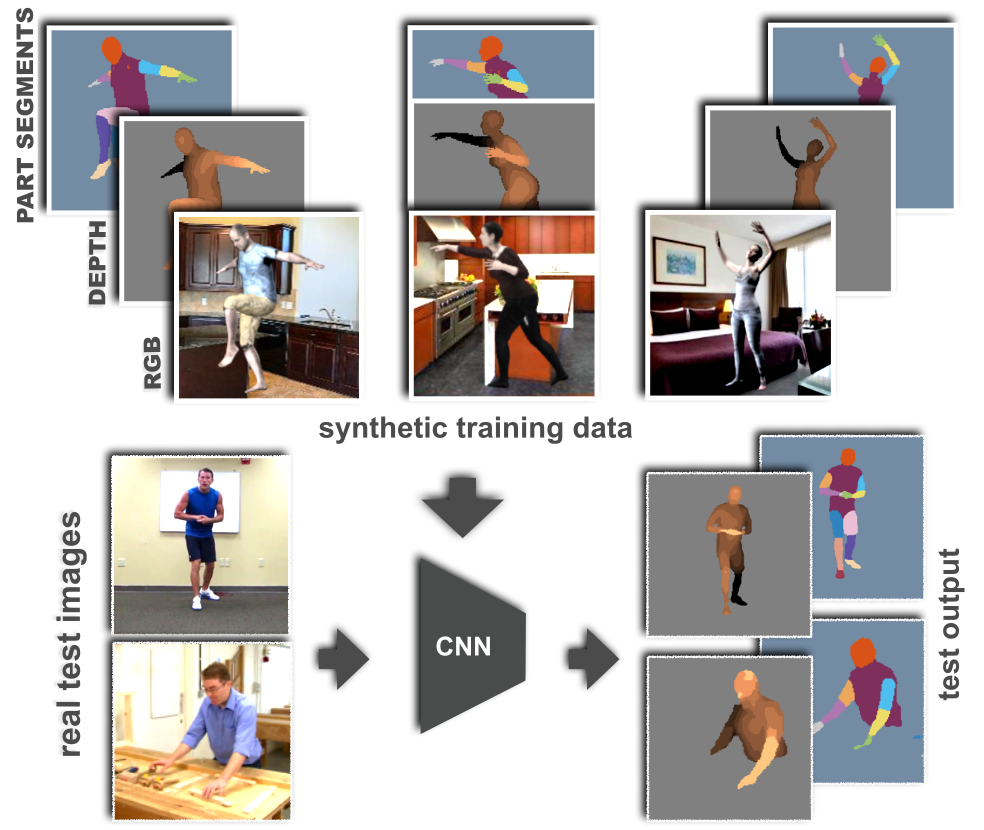
Learning from Synthetic Humans
Participants : Gül Varol, Javier Romero, Xavier Martin, Naureen Mahmood, Michael Black, Ivan Laptev, Cordelia Schmid.
Estimating human pose, shape, and motion from images and video are fundamental challenges with many applications. Recent advances in 2D human pose estimation use large amounts of manually-labeled training data for learning convolutional neural networks (CNNs). Such data is time consuming to acquire and difficult to extend. Moreover, manual labeling of 3D pose, depth and motion is impractical. In [28], we present SURREAL: a new large-scale dataset with synthetically-generated but realistic images of people rendered from 3D sequences of human motion capture data. We generate more than 6 million frames together with ground truth pose, depth maps, and segmentation masks. We show that CNNs trained on our synthetic dataset allow for accurate human depth estimation and human part segmentation in real RGB images, see Figure 11. Our results and the new dataset open up new possibilities for advancing person analysis using cheap and large-scale synthetic data. This work has been published at CVPR 2017 [28].
|