

Section: New Results
Graphics with Uncertainty and Heterogeneous Content
Single-Image SVBRDF Capture with a Rendering-Aware Deep Network
Participants : Valentin Deschaintre, Aittala Miika, Frédéric Durand, George Drettakis, Adrien Bousseau.
Texture, highlights, and shading are some of many visual cues that allow humans to perceive material appearance in single pictures. Yet, recovering spatially-varying bi-directional reflectance distribution functions (SVBRDFs) from a single image based on such cues has challenged researchers in computer graphics for decades. We tackle lightweight appearance capture by training a deep neural network to automatically extract and make sense of these visual cues. Once trained, our network is capable of recovering per-pixel normal, diffuse albedo, specular albedo and specular roughness from a single picture of a flat surface lit by a hand-held flash. We achieve this goal by introducing several innovations on training data acquisition and network design. For training, we leverage a large dataset of artist-created, procedural SVBRDFs which we sample and render under multiple lighting directions. We further amplify the data by material mixing to cover a wide diversity of shading effects, which allows our network to work across many material classes. Motivated by the observation that distant regions of a material sample often offer complementary visual cues, we design a network that combines an encoder-decoder convolutional track for local feature extraction with a fully-connected track for global feature extraction and propagation. Many important material effects are view-dependent, and as such ambiguous when observed in a single image. We tackle this challenge by defining the loss as a differentiable SVBRDF similarity metric that compares the renderings of the predicted maps against renderings of the ground truth from several lighting and viewing directions. Combined together, these novel ingredients bring clear improvement over state of the art methods for single-shot capture of spatially varying BRDFs.
The work was published in ACM Transactions on Graphics and presented at SIGGRAPH 2018 [13], and was cited by several popular online ressources (https://venturebeat.com/2018/08/15/researchers-develop-ai-that-can-re-create-real-world-lighting-and-reflections/, https://www.youtube.com/watch?v=UkWnExEFADI).
|

Material Acquisition using an Arbitrary Number of Inputs
Participants : Valentin Deschaintre, Aittala Miika, Frédéric Durand, George Drettakis, Adrien Bousseau.
Single-image material acquisition methods try to solve the very ill-posed problem of appearance to parametric BRDF. We explore different acquisition configurations to solve the most important ambiguities while still focusing on convenience of acquisition. Our main exploration directions are multiple lights and view angles over multiple pictures. This is possible thanks to the use of deep learning and in-line input data rendering, allowing us to easily explore a wide variety of configurations simultaneously. We also specialize our network architecture to make the most of an arbitrary number of input, provided in any order.
Exploiting Repetitions for Image-Based Rendering of Facades
Participants : Simon Rodriguez, Adrien Bousseau, Frédéric Durand, George Drettakis.
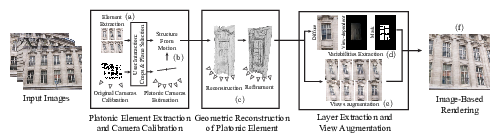
Street-level imagery is now abundant but does not have sufficient capture density to be usable for Image-Based Rendering (IBR) of facades. We presented a method that exploits repetitive elements in facades – such as windows – to perform data augmentation, in turn improving camera calibration, reconstructed geometry and overall rendering quality for IBR. The main intuition behind our approach is that a few views of several instances of an element provide similar information to many views of a single instance of that element. We first select similar instances of an element from 3-4 views of a facade and transform them into a common coordinate system (Fig. 7 (a)), creating a “platonic” element. We use this common space to refine the camera calibration of each view of each instance (Fig. 7 (b)) and to reconstruct a 3D mesh of the element with multi-view stereo, that we regularize to obtain a piecewise-planar mesh aligned with dominant image contours (Fig. 7 (c)). Observing the same element under multiple views also allows us to identify reflective areas – such as glass panels – (Fig. 7 (d)) which we use at rendering time to generate plausible reflections using an environment map. We also combine information from multiple viewpoints to augment our initial set of views of the elements (Fig. 7 (e)). Our detailed 3D mesh, augmented set of views, and reflection mask enable image-based rendering of much higher quality than results obtained using the input images directly(Fig. 7 (f)).
The work was published in Computer Graphics Forum, presented at the Eurographics Symposium on Rendering 2018 [16].
Plane-Based Multi-View Inpainting for Image-Based Rendering in Large Scenes
Participants : Julien Philip, George Drettakis.
Image-Based Rendering (IBR) allows high-fidelity free-viewpoint navigation using only a set of photographs and 3D reconstruction as input. It is often necessary or convenient to remove objects from the captured scenes, allowing a form of scene editing for IBR. This requires multi-view inpainting of the input images. Previous methods suffer from several major limitations: they lack true multi-view coherence, resulting in artifacts such as blur, they do not preserve perspective during inpainting, provide inaccurate depth completion and can only handle scenes with a few tens of images. Our approach addresses these limitations by introducing a new multi-view method that performs inpainting in intermediate, locally common planes. Use of these planes results in correct perspective and multi-view coherence of inpainting results. For efficient treatment of large scenes, we present a fast planar region extraction method operating on small image clusters. We adapt the resolution of inpainting to that required in each input image of the multi-view dataset, and carefully handle image resampling between the input images and rectified planes. We show results on large indoors and outdoors environments.
The work was presented at the ACM SIGGRAPH I3D Symposium on Interactive Computer Graphics and Games [19].
|

Deep Blending for Free-Viewpoint Image-Based Rendering
Participants : Julien Philip, George Drettakis.
Free-viewpoint image-based rendering (IBR) is a standing challenge. IBR methods combine warped versions of input photos to synthesize a novel view. The image quality of this combination is directly affected by geometric inaccuracies of multi-view stereo (MVS) reconstruction and by view- and image-dependent effects that produce artifacts when contributions from different input views are blended. We present a new deep learning approach to blending for IBR, in which we use held-out real image data to learn blending weights to combine input photo contributions. Our Deep Blending method requires us to address several challenges to achieve our goal of interactive free-viewpoint IBR navigation. We first need to provide sufficiently accurate geometry so the Convolutional Neural Network (CNN) can succeed in finding correct blending weights. We do this by combining two different MVS reconstructions with complementary accuracy vs. completeness tradeoffs. To tightly integrate learning in an interactive IBR system, we need to adapt our rendering algorithm to produce a fixed number of input layers that can then be blended by the CNN. We generate training data with a variety of captured scenes, using each input photo as ground truth in a held-out approach. We also design the network architecture and the training loss to provide high quality novel view synthesis, while reducing temporal flickering artifacts. Our results demonstrate free-viewpoint IBR in a wide variety of scenes, clearly surpassing previous methods in visual quality, especially when moving far from the input cameras.
This work is a collaboration with Peter Hedman and Gabriel Brostow from University College London and True Price and Jan-Michael Frahm from University of North Carolina at Chapel Hill. It was published in ACM Transactions on Graphics and presented at SIGGRAPH Asia 2018 [14].

Thin Structures in Image Based Rendering
Participants : Theo Thonat, Abdelaziz Djelouah, Frédéric Durand, George Drettakis.
This work proposes a novel method to handle thin structures in Image-Based Rendering (IBR), and specifically structures supported by simple geometric shapes such as planes, cylinders, etc. These structures, e.g. railings, fences, oven grills etc, are present in many man-made environments and are extremely challenging for multi-view 3D reconstruction, representing a major limitation of existing IBR methods. Our key insight is to exploit multi-view information to compute multi-layer alpha mattes to extract the thin structures. We use two multi-view terms in a graph-cut segmentation, the first based on multi-view foreground color prediction and the second ensuring multi-view consistency of labels. Occlusion of the background can challenge reprojection error calculation and we use multi-view median images and variance, with multiple layers of thin structures. Our end-to-end solution uses the multi-layer segmentation to create per-view mattes and the median colors and variance to extract a clean background. We introduce a new multi-pass IBR algorithm based on depth-peeling to allow free-viewpoint navigation of multi-layer semi-transparent thin structures. Our results show significant improvement in rendering quality for thin structures compared to previous image-based rendering solutions.
The work was published in the journal Computer Graphics Forum, and was presented at the Eurographics Symposium on Rendering (EGSR) 2018 [17].
|

Multi-Scale Simulation of Nonlinear Thin-Shell Sound with Wave Turbulence
Participants : Gabriel Cirio, George Drettakis.
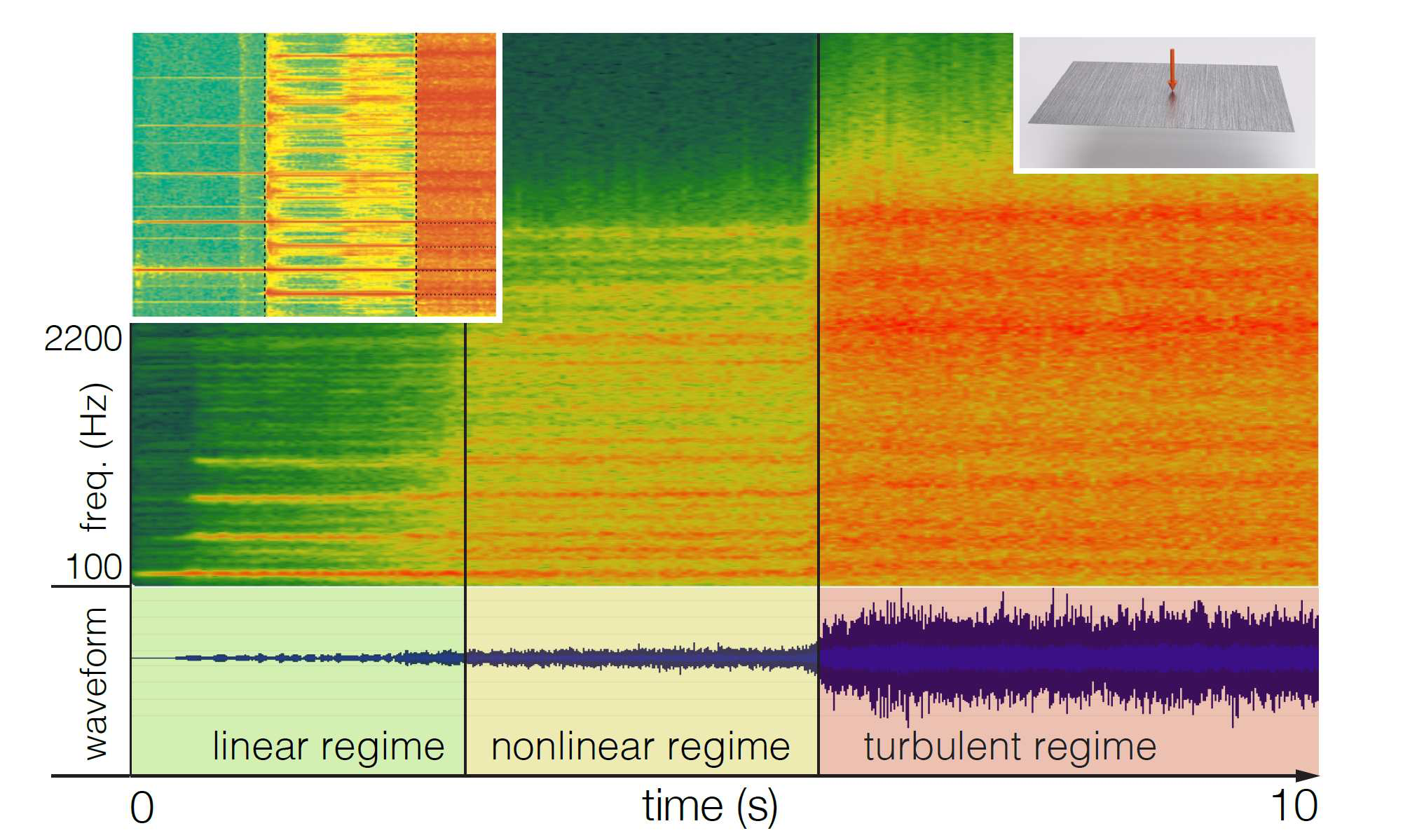
Thin shells – solids that are thin in one dimension compared to the other two – often emit rich nonlinear sounds when struck. Strong excitations can even cause chaotic thin-shell vibrations, producing sounds whose energy spectrum diffuses from low to high frequencies over time – a phenomenon known as wave turbulence. It is all these nonlinearities that grant shells such as cymbals and gongs their characteristic “glinting” sound. Yet, simulation models that efficiently capture these sound effects remain elusive. In this project, we proposed a physically based, multi-scale reduced simulation method to synthesize nonlinear thin-shell sounds. We first split nonlinear vibrations into two scales, with a small low-frequency part simulated in a fully nonlinear way, and a high-frequency part containing many more modes approximated through time-varying linearization. This allows us to capture interesting nonlinearities in the shells' deformation, tens of times faster than previous approaches. Furthermore, we propose a method that enriches simulated sounds with wave turbulent sound details through a phenomenological diffusion model in the frequency domain, and thereby sidestep the expensive simulation of chaotic high-frequency dynamics. We show several examples of our simulations, illustrating the efficiency and realism of our model, see Fig. 11.
This work is a collaboration with Ante Qu from Stanford, Eitan Grinspun and Changzi Zheng from Columbia. This work was published at ACM Transactions on Graphics, and presented at SIGGRAPH 2018 [11].
|
Learning to Relight Multi-View Photographs from Synthetic Data
Participants : Julien Philip, George Drettakis.
We introduce an image relighting method that allows users to alter the lighting in their photos given multiple views of the same scene. Our method uses a deep convolutional network trained on synthetic photorealistic images. The use of a 3D reconstruction of the surroundings allows to guide the relighting process.
This ongoing project is a collaboration with Tinghui Zhou and Alexei A. Efros from UC Berkeley, and Michael Gharbi from Adobe research.
Exploiting Semantic Information for Street-level Image-Based Rendering
Participants : Simon Rodriguez, George Drettakis.
Following our work on facade rendering (Sec. 6.2.3), this ongoing project explores the use of semantic segmentation to inform Image-Based Rendering algorithms. In particular, we plan to devise algorithms that adapt to different types of objects in the scene (cars, buildings, trees).
Casual Video Based Rendering of Stochastic Phenomena
Participants : Theo Thonat, Miika Aittala, Frédéric Durand, George Drettakis.
The goal of this work is to extend traditional Image Based Rendering to capture subtle motions in real scenes. We want to allow free-viewpoint navigation with casual capture, such as a user taking photos and videos with a single smartphone or DSLR camera, and a tripod. We focus on stochastic time-dependent textures such as leaves in the wind, water or fire, to cope with the challenge of using unsynchronized videos.
This ongoing work is a collaboration with Sylvain Paris from Adobe Research.
Cutting-Edge VR/AR Display Technologies
Participant : Koulieris Georgios.
Near-eye (VR/AR) displays suffer from technical, interaction as well as visual quality issues which hinder their commercial potential. We presented a tutorial that delivered an overview of cutting-edge VR/AR display technologies, focusing on technical, interaction and perceptual issues which, if solved, will drive the next generation of display technologies. The most recent advancements in near-eye displays were presented providing (i) correct accommodation cues, (ii) near-eye varifocal AR, (iii) high dynamic range rendition, (iv) gaze-aware capabilities, either predictive or based on eye-tracking as well as (v) motion-awareness (Fig. 12). Future avenues for academic and industrial research related to the next generation of AR/VR display technologies were analyzed.
This work is a collaboration with Kaan Akşit (NVIDIA), Christian Richardt (University of Bath), Rafal Mantiuk (University of Cambridge) and Katerina Mania (Technical University of Crete). The work was presented at IEEE VR 2018, 18-22 March, Reutlingen, Germany [18].
