Section: New Results
Analysis
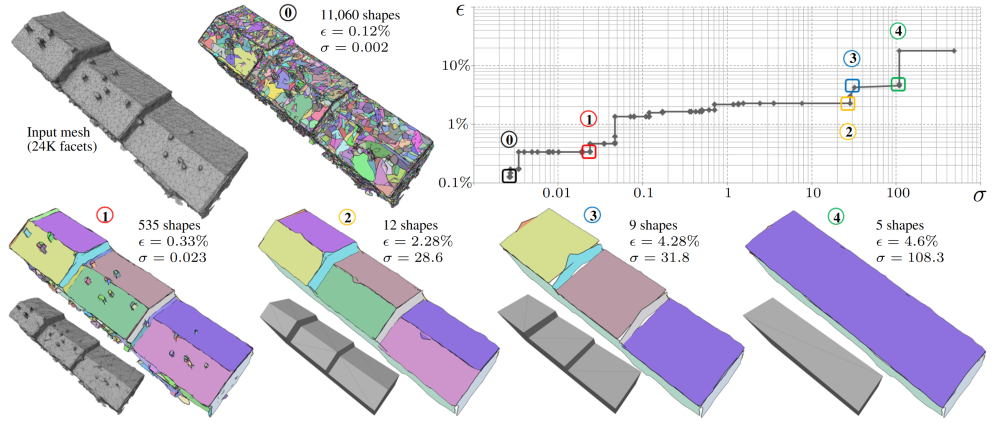
Planar Shape Detection at Structural Scales
Participants : Hao Fang, Mathieu Desbrun, Florent Lafarge [contact] .
Shape detection, abstraction, man-made objects, point clouds, surface reconstruction.
Interpreting 3D data such as point clouds or surface meshes depends heavily on the scale of observation. Yet, existing algorithms for shape detection rely on trial-and-error parameter tunings to output configurations representative of a structural scale. We present a framework to automatically extract a set of representations that capture the shape and structure of man-made objects at different key abstraction levels. A shape-collapsing process first generates a fine-to-coarse sequence of shape representations by exploiting local planarity. This sequence is then analyzed to identify significant geometric variations between successive representations through a supervised energy minimization. Our framework is flexible enough to learn how to detect both existing structural formalisms such as the CityGML Levels Of Details, and expert-specified levels of abstraction. Experiments on different input data and classes of man-made objects, as well as comparisons with existing shape detection methods, illustrate the strengths of our approach in terms of efficiency and flexibility. Figure 1 illustrates the goal of our method. This work has been published in the proceedings of CVPR [16].
|
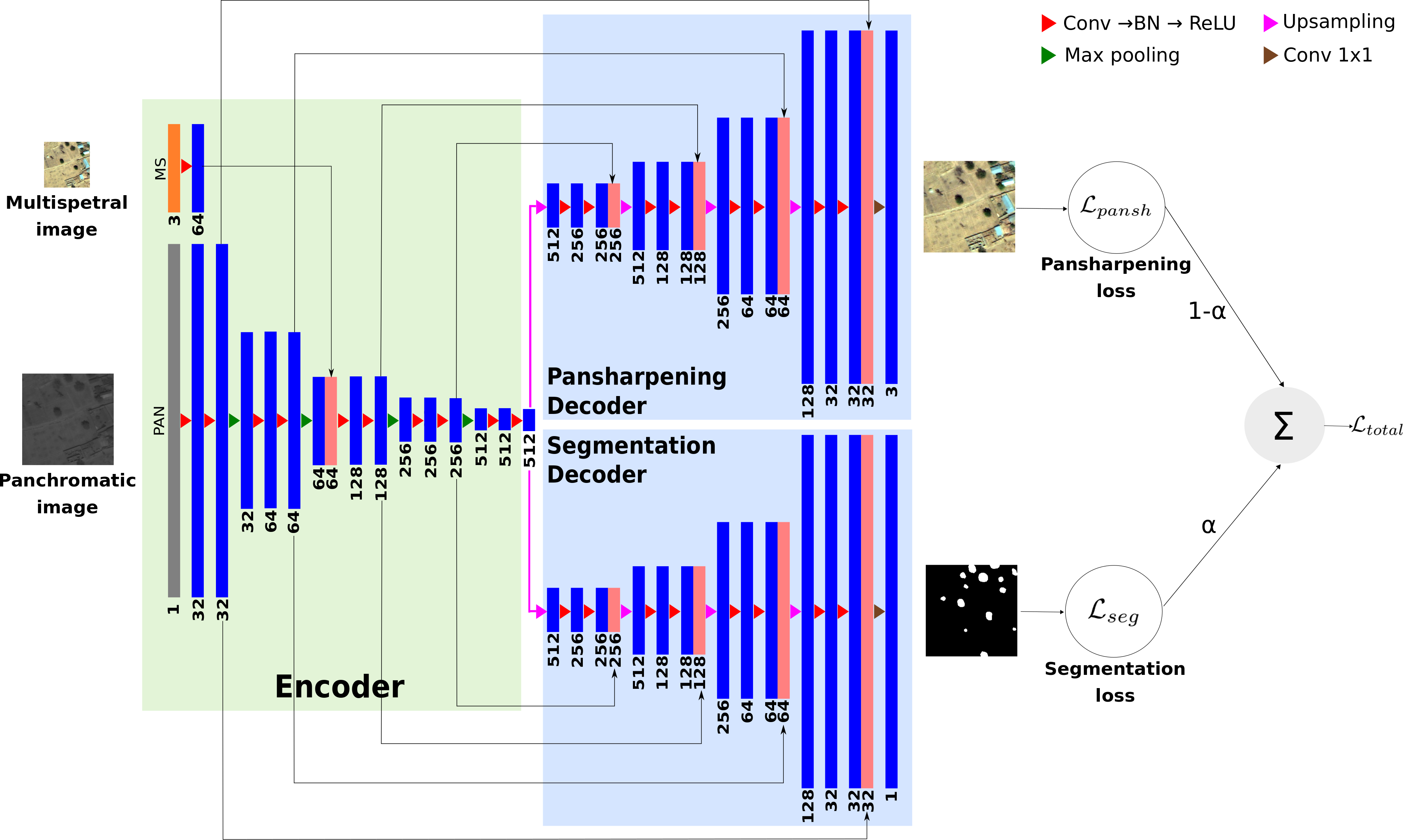
Multi-task Deep Learning for Satellite Image Pansharpening and Segmentation
Participants : Andrew Khalel, Onur Tasar, Yuliya Tarabalka [contact] .
This work has been done in collaboration with Dr. Guillaume Charpiat (TAU team, Inria Saclay).
Segmentation, pansharpening, multi-task, joint learning
We proposed a novel multi-task framework to learn satellite image pansharpening and segmentation jointly. Our framework is based on encoder-decoder architecture, where both tasks share the same encoder but each one has its own decoder (see Fig. 2). We compare our framework against single-task models with different architectures. Results show that our framework outperforms all other approaches in both tasks.
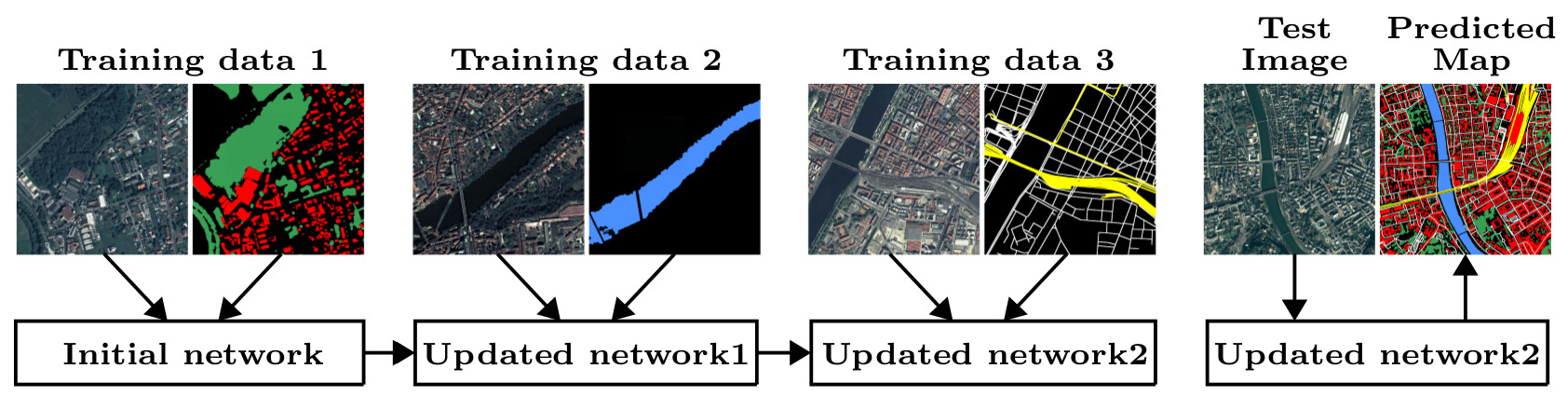
Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data
Participants : Onur Tasar, Pierre Alliez, Yuliya Tarabalka [contact] .
This work has been done in collaboration with CNES and ACRI-ST.
Incremental learning, catastrophic forgetting, semantic segmentation, convolutional neural networks
In spite of remarkable success of the convolutional neural networks on semantic segmentation, they suffer from catastrophic forgetting: a significant performance drop for the already learned classes when new classes are added on the data, having no annotations for the old classes. We propose an incremental learning methodology, enabling to learn segmenting new classes without hindering dense labeling abilities for the previous classes, although the entire previous data are not accessible. The key points of the proposed approach are adapting the network to learn new as well as old classes on the new training data, and allowing it to remember the previously learned information for the old classes. For adaptation, we keep a frozen copy of the previously trained network, which is used as a memory for the updated network in absence of annotations for the former classes. The updated network minimizes a loss function, which balances the discrepancy between outputs for the previous classes from the memory and updated networks, and the mis-classification rate between outputs for the new classes from the updated network and the new ground-truth. For remembering, we either regularly feed samples from the stored, little fraction of the previous data or use the memory network, depending on whether the new dat (see Fig. 3)a are collected from completely different geographic areas or from the same city. Our experimental results prove that it is possible to add new classes to the network, while maintaining its performance for the previous classes, despite the whole previous training data are not available. This work was submitted to IEEE Transactions on Geoscience and Remote Sensing (TGRS) and is currently on arXiV [25].
|
Multimodal Image Alignment through a Multiscale Chain of Neural Networks with Application to Remote Sensing
Participants : Nicolas Girard, Yuliya Tarabalka [contact] .
This work has been done in collaboration with Armand Zampieri and Dr. Guillaume Charpiat (TAO team, Inria Saclay).
Multimodal, Alignment, Registration, Remote sensing
We tackle here the problem of multimodal image non-rigid registration, which is of prime importance in remote sensing and medical imaging. The difficulties encountered by classical registration approaches include feature design and slow optimization by gradient descent. By analyzing these methods, we note the significance of the notion of scale. We design easy-to-train, fully-convolutional neural networks able to learn scale-specific features. Once chained appropriately, they perform global registration in linear time, getting rid of gradient descent schemes by predicting directly the deformation.
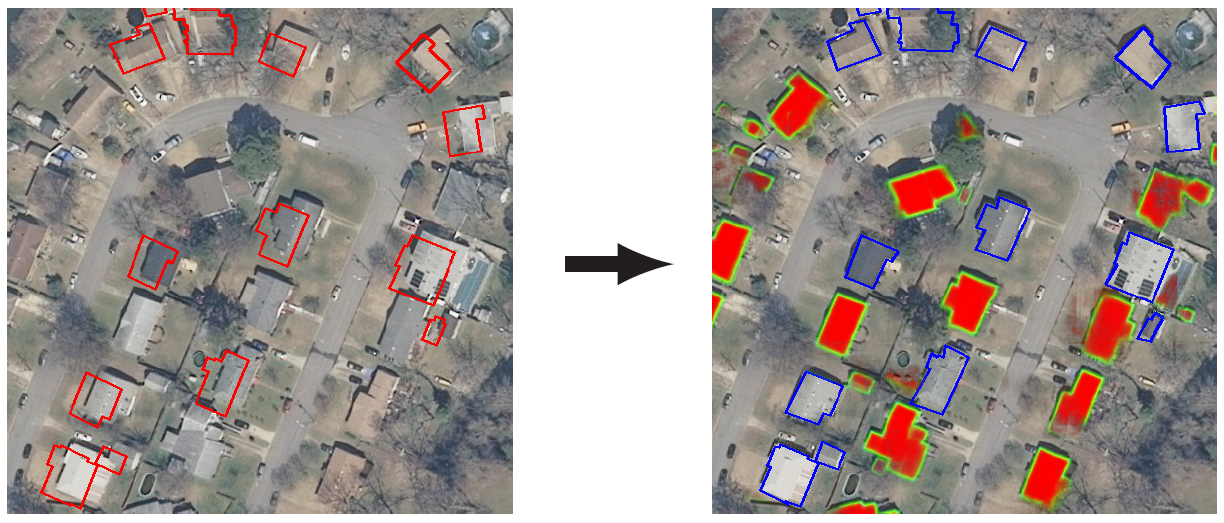
We show their performance in terms of quality and speed through various tasks of remote sensing multimodal image alignment. In particular, we are able to register correctly cadastral maps of buildings as well as road polylines onto RGB images, and outperform current keypoint matching methods (see Fig. 4). This work has been published in the proceedings of ECCV [20].
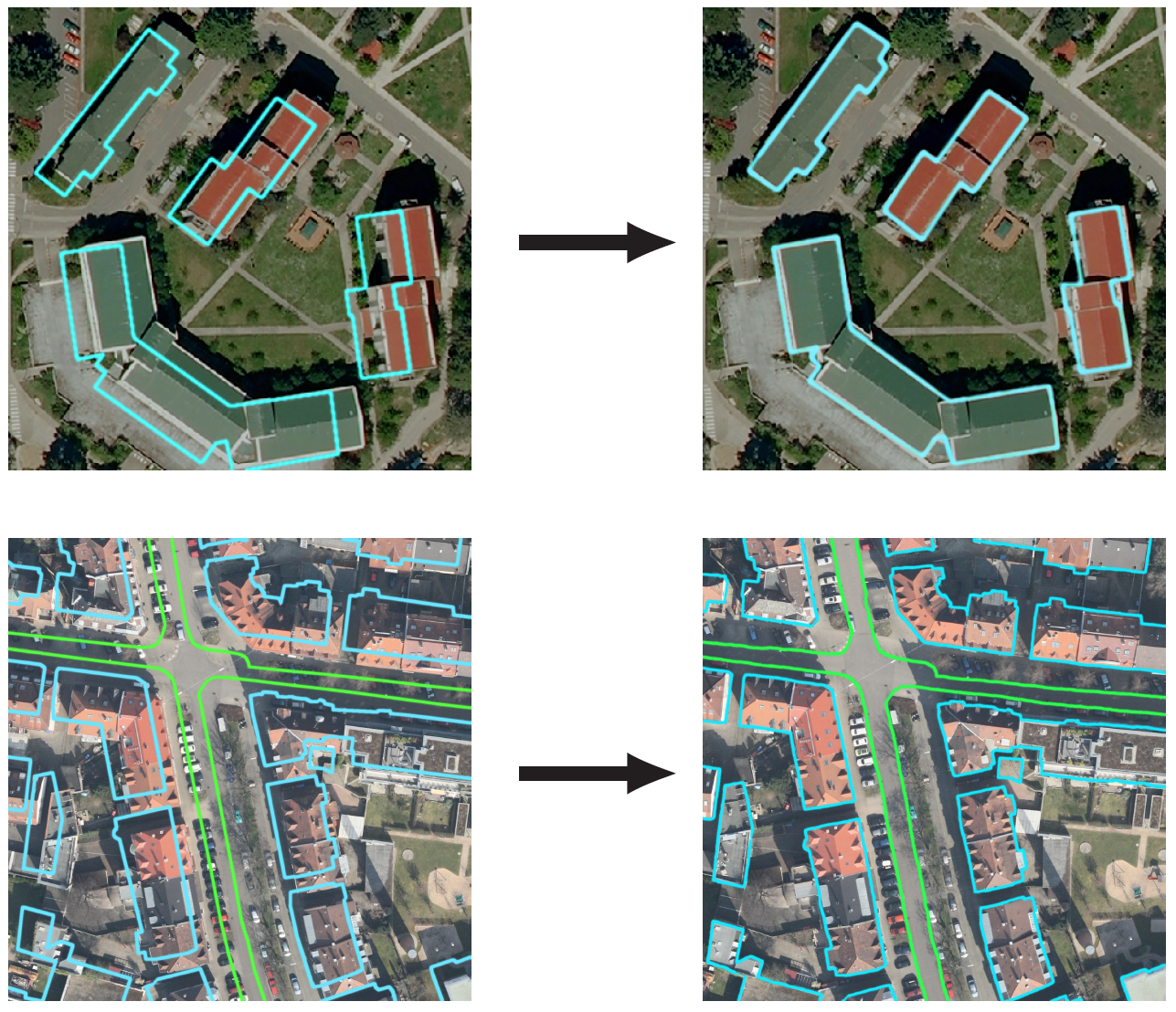
Aligning and Updating Cadaster Maps with Aerial Images by Multi-Task, Multi-Resolution Deep Learning
Participants : Nicolas Girard, Yuliya Tarabalka [contact] .
This work has been done in collaboration with Dr. Guillaume Charpiat (TAO team, Inria Saclay).
Alignment, Registration, Multi-task, Multi-resolution
A large part of the world is already covered by maps of buildings, through projects such as OpenStreetMap. However when a new image of an already covered area is captured, it does not align perfectly with the buildings of the already existing map, due to a change of capture angle, atmospheric perturbations, human error when annotating buildings or lack of precision of the map data. Some of those deformations can be partially corrected, but not perfectly, which leads to misalignments. Additionally, new buildings can appear in the image. Leveraging multi-task learning, our deep learning model aligns the existing building polygons to the new image through a displacement output, and also detects new buildings that do not appear in the cadaster through a segmentation output (see Fig. 5). It uses multiple neural networks at successive resolutions to output a displacement field and a pixel-wise segmentation of the new buildings from coarser to finer scales. We also apply our method to buildings height estimation, by aligning cadaster data to the rooftops of stereo images.