

Section: New Software and Platforms
Learning algorithms
KidLearn
Participants : Manuel Lopes [correspondant] , Benjamin Clement, Pierre-Yves Oudeyer, Didier Roy.
The KidLearn software provides an Intelligent Tutoring System that optimizes teaching sequences based on the estimated level of each particular student. Two algorithms, RiARiT and ZPDES have been developped and are described in [37] , [39] and [38] . We updated the Game of Money that we developped last year wich allows students between 7-8 years to learn how to use money. It still includes 3 main components: i) a webserver that handles the requests and stores the experiments in a databased; ii) a GUI that provides the interface for the game; and iii) the optimization software.
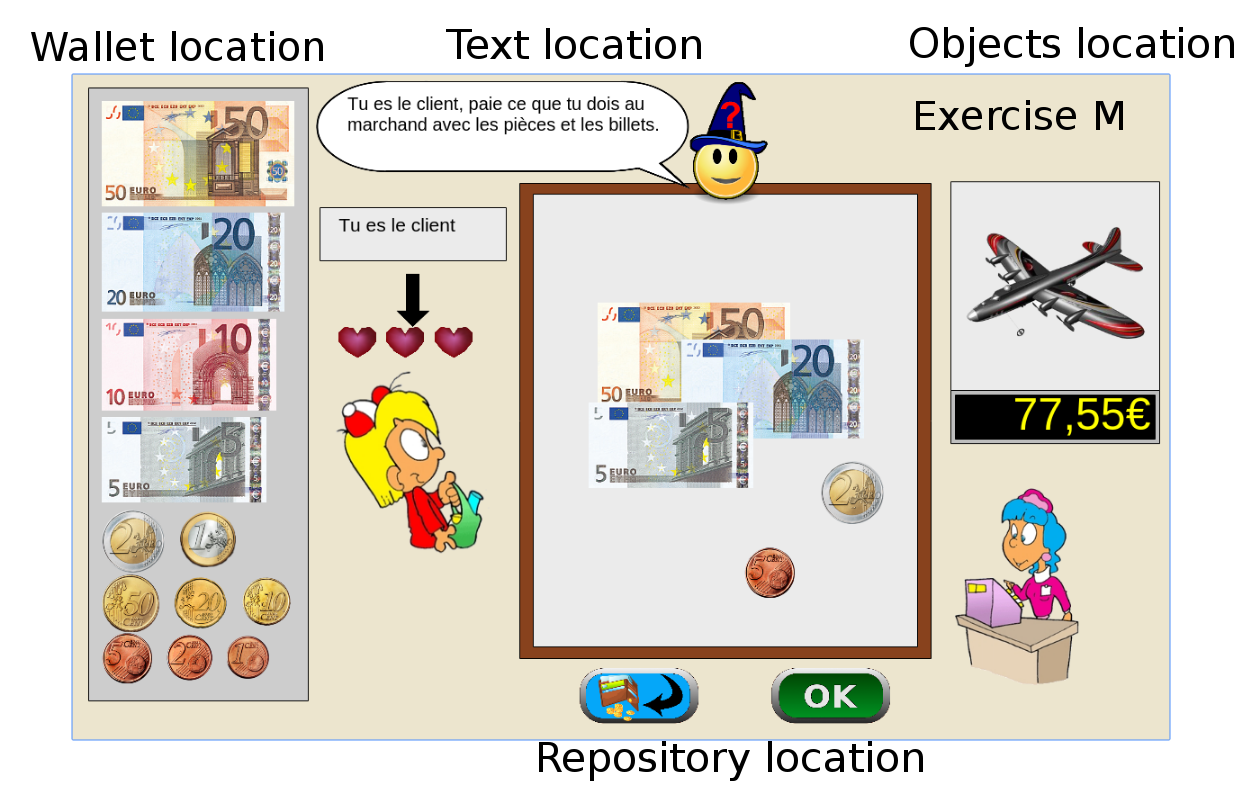
Graphical interfaces in ITS can have unwanted side effects. For this reason, the interface was entirely designed with the help of a didactician, with several specific design choices motivated by pedagogical, motivational and attention requirements. For example, the interface, shown in Figure 1 . is such that:
-
there is no chronometer, so that students are not put under time pressure;
-
coins and banknotes have realistic visual appearance, and their relative sizes are respected;
-
costumer and merchant are represented to indicate clearly the role of the student;
Four principal regions are defined in the graphical interface, as shown in Figure 1 , on the left picture. The first is the wallet location where users can pick and drag the money items and drop them on the repository location to compose the correct price. The object and the price are present in the object location.
|
We performed a more developed and complete user study than last year, considering 5 different schools in the Bordeaux metropolitan area. We had a total of 400 students between 7 and 8 years old. We divided them into 4 groups, with one control group where student does not use the software and 3 groups where exercises are proposed using : a) a predefined sequence; b) ZPDES; c) RiARiT. To measure student learning, students pass pre-test few days before using the interface, and a post test fews days after using the interface. The control group pass the pre and post test at the same time that others but without using the interface between. The results of this study have been presented in [69] .
DMP-BBO Matlab library
Participant : Freek Stulp [correspondant] .
The dmp_bbo (Black-Box Optimization for Dynamic Movement Primitives) Matlab library is a direct consequence of the insight that black-box optimization outperforms reinforcement learning when using policies represented as Dynamic Movement Primitives. It implements several variants of the algorithm for direct policy search. It is currently being used and extended by several FLOWERS members (Manuel Lopes, Clément Moulin-Frier) and external collaborators (Jonas Buchli, Hwangbo Jemin of ETH Zurich). In the context of the DIGITEO-funded project “PrActIx” , CEA LIST has now started using this library. In 2014, parts have been made real-time safe for use on the Meka Humanoid robot. This has been fundamental in achieving the results for [65] , [64] .
Self-calibration BCI - Matlab library
Participants : Jonathan Grizou [correspondant] , Iñaki Iturrate, Luis Montesano, Manuel Lopes, Pierre-Yves Oudeyer.
The Matlab software implements the algorithms described in [45] . Downloadable from https://github.com/jgrizou/lfui .
It allows a robot to be instructed a new task by a human using communicative signals initially totally unknown to the robot. It is was extended and improved in the context of EEG-based brain-machine interfaces (BMIs) [44] .
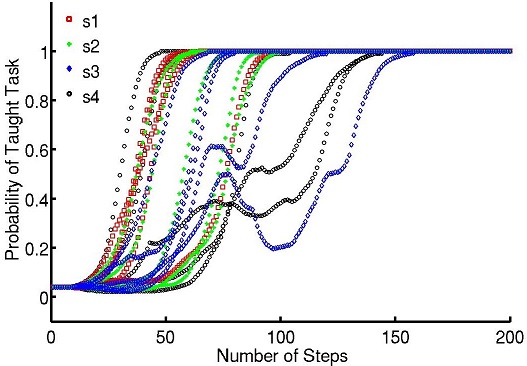
It results in a BCI based control of sequential tasks with feedback signals that do not require any calibration process. As a by-product, the method provides an unsupervised way to train a decoder with the same performance than state-of-the-art supervised classifiers, while keeping the system operational and solving, with a lower performance during the first steps, the unknown task. The algorithm has been tested with online experiments (fig. 2 ), showing that the users were able to guide from scratch an agent to a desired position.
|
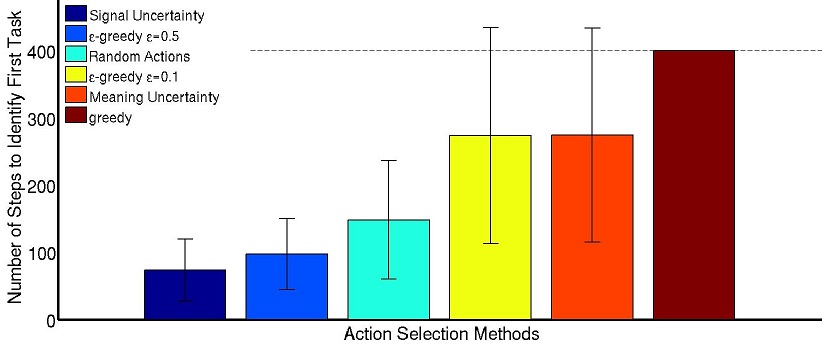
To improve the efficiency of the algorithm, we introduced a new planning method that uses the uncertainty in the signal-target estimation. This planner is inspired by exploration methods with exploration bonuses that allow guiding to reduce the uncertainty in an efficient way. We showed that trying to follow the best hypothesis does not explore the space significantly to reduce uncertainty and thus identify the correct task. Only through an approach that plans how to reduce the uncertainty multiple steps ahead are we sure that the agent will reach states that can only be explained by the correct hypothesis.
|
DyNAMoS: parallel multi-process simulation of distributed neural architectures
Participants : Alexander Gepperth [correspondant] , Mathieu Lefort.
This simulation software comes in the form of a PYTHON module and allows a user to define and simulate complex neural architectures while making use of the parallelism inherent to modern multi-core processors. A special focus lies on on-line learning, processing inputs one by one, in contrast to batch processing of whole databases at a time.
The connectivity of an architecture, as well as neural dynamics and learning rules, are defined by editing simple text-based configuration files. A simple instantiation of a pre-defined simulator class together with the name of the configuration file launches the simulation. Users can provide continuous input to the architecture, as well as inspect and visualize all elements of the simulation, by subclassing the simulator class and redefining the appropriate methods in a clean and Pythonic way. DyNAMoS can be, and is in fact meant to be, extended by user-defined learning methods and dynamics models, which is possible through a well-documented interface all such functions must respect. DyNAMoS distributes computation across multiple processes that are spawned dynamically, possibly on multiple computers, which communicate by TCP/IP or Linux interprocess communication depending on whether they are on the same computer. All aspects of multi-process handling and communication are completely hidden from the user who may merely specify which neural map is executed on which physical process if he wishes to.
This software has been used to speed up computations and provides a common platform for implementing online and incremental learning algorithms. Up to now, we have included linear and logistic regression, various versions of self-organizing maps, MLP and LWPR. It will be made available on GitHub in 2015 after final tests have been concluded.
pyStreamPlayer: synchronized replay of multiple sensor recordings and supplementary data
Participant : Alexander Gepperth [correspondant] .
This Python software is intended to facilitate the application of machine learning algorithms by avoiding to work directly with an embodied agent but instead with data recorded in such an agent. Assuming that non-synchronous data from multiple sensors (e.g., camera, Kinect, laser etc.) have been recorded according to a flexible format defined by the pyStreamPlayer architecture, pyStreamPlayer can replay these data while retaining the exact temporal relations between different sensor measurements. As long as the current task does not involve the generation of actions, this software allows to process sensor data as if it was coming from an agent which is usually considerably easier. At the same time, pyStreamPlayer allows to replay arbitrary supplementary information such as, e.g., object information, as if it was coming from a sensor. In this way, supervision information can be stored and accessed together with sensory measurements using an unified interface. pyStreamPlayer has been used to facilitate real-world object recognition tasks, and several of the major databases in this field (CalTech Pedestrian database, HRI RoadTraffic traffic objects database, CVC person database, KITTI traffic objects database) have been converted to the pyStreamPlaer format and now serve as a source of training and test data for learning algorithms.
pyStreamPlayer has been integrated into a ROS node as well, allowing th replay and transmission across networks of distributed processes.
Multimodal: framework around the NMF algorithm for multimodal learning
Participant : Olivier Mangin [correspondant] .
The python code provides a minimum set of tools and associated libraries to reproduce the experiments in [98] , together with the choreography datasets. The code, publicly available at https://github.com/omangin/multimodal , under the new BSD license, is primarily intended for reproduction of the mulimodal learning experiment mentioned above. It has already been reused in several experimentations by other member of the team and is expected to play an important role in further collaborations. It is also expected that the public availability of the code encourages further experimentation by other scientists with data coming from other domains, thus increasing both the impact of the aforementioned publication and the knowledge on the algorithm behaviors. The nonnegative matrix factorization algorithm used in the experiments is also available as a third party extension to http://scikit-learn.org .
Explauto: an autonomous exploration library
Participants : Clément Moulin-Frier [correspondant] , Pierre Rouanet.
Explauto is a framework developed to study, model and simulate curiosity-driven learning and exploration in virtual and robotic agents. The code repository is available at: https://github.com/flowersteam/explauto .
This library provides high-level API for an easy definition of:
It is crossed-platform and has been tested on Linux, Windows and Mac OS. It has been released under the GPLv3 license.
Explauto's scientific roots trace back from Intelligent Adaptive Curiosity algorithmic architecture [15] , which has been extended to a more general family of autonomous exploration architecture by [3] and recently expressed as a compact and unified formalism [102] . The library is detailed in [60] .
This library has been used in many experiments including:
-
the exploration of the inverse kinematics of a poppy humanoid (both on the real robot and on the simulated version)
Explorers Framework
Participants : Benureau Fabien [correspondant] , Pierre-Yves Oudeyer.
The Explorers framework is aimed at creating, testing and comparing autonomous exploration strategies for sensorimotor spaces in robots. The framework is largely strategy-agnostic, and is aimed as expressing motor babbling, goal babbling and intrinsically motivated exploration algorithms, among other. It is also able to express strategies that feature transfer learning, such as the reuse algorithm we introduce in [34] .
At the center of the framework, an explorer receives observations and provides motor commands for the environment to execute.
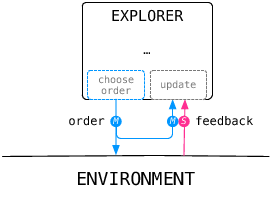
We can then easily express a typical goal babbling architecture (the feedback update is not pictured).
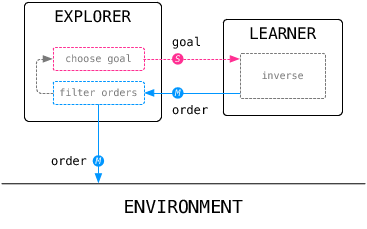
Here, the explorer interacts with the environment, rather than the inverse model. Such an architecture allows to filter motor commands that are proposed by the inverse model, and eventually to select another goal if the motor command is not satisfactory or possible to execute. The framework is organized in a modular way. This allows to create flexible hierarchical architectures made of several, atomic or themselves composite, exploration strategies.
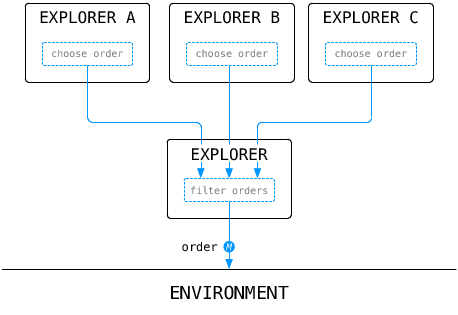
The framework has been released this year under the OpenScience license (http://fabien.benureau.com/openscience.html ), and made available on github (https://github.com/humm/explorers ). Using provided examples, users can easily modify the exploration parameters and investigate for instance the differences between motor and goal babbling exploration strategies.
PyQMC: Python library for Quasi-Metric Control
Participant : Steve Nguyen [correspondant] .
PyQMC (https://github.com/SteveNguyen/pyqmc) is a python library implementing the control method described in http://dx.doi.org/10.1371/journal.pone.0083411 It allows to solve discrete markovian decision processes by computing a Quasi-Metric on the state space. This model based method has the advantage to be goal independant and thus can produce a policy for any goal with relatively few recomputation. New addition to this method is the possibility of online learning of the transition model and the Quasi-Metric.