

Section: New Results
Autonomous Machine Learning and Applications to Developmental Robotics
Intrinsically Motivated Goal Exploration and Multi-Task Reinforcement Learning
Participants : Sébastien Forestier, Pierre-Yves Oudeyer [correspondant] , Alexandre Péré, Olivier Sigaud, Pierre Manceron, Yoan Mollard.
Intrinsically Motivated Exploration of Spaces of Parameterized Skills/Tasks and Application to Robot Tool Learning
A major challenge in robotics is to learn parametrized policies to solve multi-task reinforcement learning problems in high-dimensional continuous action and effect spaces. Of particular interest is the acquisition of inverse models which map a space of sensorimotor problems to a space of motor programs that solve them. For example, this could be a robot learning which movements of the arm and hand can push or throw an object in each of several target locations, or which arm movements allow to produce which displacements of several objects potentially interacting with each other, e.g. in the case of tool use. Specifically, acquiring such repertoires of skills through incremental exploration of the environment has been argued to be a key target for life-long developmental learning [96].
This year we developed a formal framework called “Unsupervised Multi-Goal Reinforcement Learning”, as well as a formalization of intrinsically motivated goal exploration processes (IMGEPs), that is both more compact and more general than our previous models [89]. We experimented several implementations of these processes in a complex robotic setup with multiple objects 13, associated to multiple spaces of parameterized reinforcement learning problems, and where the robot can learn how to use certain objects as tools to manipulate other objects. We analyzed how curriculum learning is automated in this unsupervised multi-goal exploration process, and compared the trajectory of exploration and learning of these spaces of problems with the one generated by other mechanisms such as hand-designed learning curriculum, or exploration targeting a single space of problems, and random motor exploration. We showed that learning several spaces of diverse problems can be more efficient for learning complex skills than only trying to directly learn these complex skills. We illustrated the computational efficiency of IMGEPs as these robotic experiments use a simple memory-based low-level policy representations and search algorithm, enabling the whole system to learn online and incrementally on a Raspberry Pi 3.
|


In order to run more scientific experiments in a shorter time, we scaled up this experimental setup to a platform of 6 identical Poppy Torso robots, each of them having the same environment to interact with. Every robot can run a different task with a specific algorithm and parameters each 14. In this setup Poppy Torso robots are requesting jobs to a dedicated computer acting as a job manager which monitors execution and distributes jobs to available robots. Moreover, each Poppy Torso can also perceives the motion of a second Poppy Ergo robot, than can be used, this time, as a distractor performing random motions to complicate the learning problem. 12 top cameras and 6 head cameras can dump video streams during experiments, in order to record video datasets. Data and videos are stored on-the-fly on 6 hard disks.
|

Unsupervised Deep Learning of Goal Spaces for Goal Intrinsically Motivated Goal Exploration
Intrinsically motivated goal exploration algorithms enable machines to discover repertoires of policies that produce a diversity of effects in complex environ- ments. These exploration algorithms have been shown to allow real world robots to acquire skills such as tool use in high-dimensional continuous state and action spaces. However, they have so far assumed that self-generated goals are sampled in a specifically engineered feature space, limiting their autonomy. We have proposed an approach using deep representation learning algorithms to learn an adequate goal space. This is a developmental 2-stage approach: first, in a perceptual learning stage, deep learning algorithms use passive raw sensor observations of world changes to learn a corresponding latent space; then goal exploration happens in a second stage by sampling goals in this latent space. We made experiments with a simulated robot arm interacting with an object, and we show that exploration algorithms using such learned representations can closely match, and even sometimes improve, the performance obtained using engineered representations.
Combining deep reinforcement learning and curiosity-driven exploration
A major challenge of autonomous robot learning is to design efficient algorithms to learn sensorimotor skills in complex and high-dimensional continuous spaces. Deep reinforcement learning (RL) algorithms are natural candidates in this context, because they can be adapted to the problem of learning continuous control policies with low sample complexity. However, these algorithms, such as DDPG (Lillicrap et al., 2016) suffer from exploration issues in the context of sparse or deceptive reward signals.
In this project, we investigate how to integrate deep reinforcement learning algorithms with curiosity-driven exploration methods. A key idea consists in decorrelating the exploration stage from the policy learning stage by using a memory structure used in deep RL called a replay buffer. Curiosity-driven exploration algorithms, also called Goal Exploration Processes (GEPs) are used in a first stage to efficiently explore the state and action space of the problem, and the corresponding data is stored into a replay buffer. Then a DDPG learns a control policy from the content of this replay buffer.
The internship of Pierre Manceron has been dedicated to trying this methodology in practice. Pierre has combined GEPs obtained from the Explauto open-source library (Moulin-Frier et al., 2014) and his own implementation of DDPG, and benchmarked the combination using the openAI Gym toolkit (Duan et al., 2016).
Preliminary results have revealed some stability issues in DDPG, whereas encouraging results where obtained about the combination with GEPs. Beyond getting more robust results and publishing them, our next goal is to envision other ways to integrate deep RL with curiosity-driven exploration processes by using the tools of the former to more efficiently implement the latter.
Social Learning of Interactive Skills
Participants : Manuel Lopes [correspondant] , Baptiste Busch, Yoan Mollard, Thibaut Munzer.
This work was made in collaboration with Marc Toussaint and Guilherme Maeda.
Preference learning on the execution of collaborative human-robot tasks
One important aspect of the human-robot collaboration is to be able to learn the user's preferences on the sequence of actions. By querying the user on the next action, when the uncertainty is high, the robot learns the user preferences (Q-function) to solve the task. From a planning point of view, this Q-function can then be integrated into the solver to select the user preferred route to solve a task when multiple choices are available. Therefore, this work aims at reducing the human cognitive load by:
This work has been accepted for publication in the International Conference on Robotics and Automation (ICRA) 2017 and presented during the conference [80].
Interestingly, this also raises questions on the robot autonomy and its perception by the human coworker. By interacting with a user, the robot starts to learn the preferred actions and will takes initiative to perform them on the next assembly. The question is, how does the user perceives this initiative taking? To answer this question, we have conducted a user study to analyze the impact of robot initiative on the collaboration. Two conditions were considered:
-
a semi-autonomous robot that learns and decides when to execute a supporting action,
-
a support robot that has to be instructed of each action on a collaborative task.
We found that users prefer the semi-autonomous robot and that the behavior was closer to their expectations despite them being more afraid of it. We also found that even if users noticed the robot was learning in one case, they wanted more autonomy in both conditions. This research was published in the companion of the Conference on Human-Robot Interaction (HRI) 2017 and presented during the poster sessions of the conference [82].
Learning legible motions from interaction
In a human-robot collaboration context, understanding and anticipating the robot intentions ease the completion of a joint-task. Whereas previous work has sought to explicitly optimize the legibility of behavior, we investigate legibility as a property that arises automatically from general requirements on the efficiency and robustness of joint human-robot task completion.
Following our previous work on legibility of robot motions [64], we have conducted several user experiments to analyze the effects of the policy representation on the universality of the legibility.
This work lead to a submission of a journal article to the International Journal of Social Robotics (IJSR) [69]
Postural optimization for an ergonomic human-robot interaction
When we, humans, accomplish a task our body posture is (partially) constrained. For example, acting on an object constrains the pose of the hand relatively to the object, and the head faces the object we are acting upon. But due to the large number of degrees of freedom (DOF) of the human body, other body parts are unconstrained and several body postures are viable with respect to the task. However, not all of them are viable in terms of ergonomics. Using a personalized human model, observational postural assessment techniques can be automatized. Optimizing the model body posture is then the logical next step to find an ergonomically correct posture for the worker to accomplish a specific task.
To optimize the subject's model to achieve a specific task, we define an objective function that minimizes the efforts of the whole body posture, based on the Rapid Entire Body Assessment (REBA) technique [124]. The objective function also account for visibility of the target object and worker's laterality. We have also implemented an automatic assessment of the worker's body posture based on the REBA method.
|

Using a spherical object, carried by a Baxter humanoid robot as illustrated in Fig. 15, we mimic an industrial scenario where the robot helps the worker by positioning and orienting an object in which the worker has to insert specific shapes. In a user-study with forty participants, we compare three different robot's behaviors, one of them being the result of the postural optimization of the subject's personalized model. By the mean of a survey session, and the online assessment of the subject's posture during the interaction, we prove that our method leads to a safer posture, and is perceived as more comfortable.
This work has been published to the International Conference on Intelligent Robots and Systems (IROS) [75] and was presented during the conference.
Planning ergonomic sequences of actions in human-robot interaction
Following our work on physical ergonomics [75], we have extended our method to include it in the Logic-Geometric Program (LGP) [171]. This method allows us to solve Task and Motion Planning (TAMP) problems simultaneously while optimizing for maximum ergonomics on the human side.
In a simulated experimented we prove that the solver is able to choose the logic actions (e.g. “the robot places the screwdriver on the table”) that provides maximum ergonomics throughout the interaction. By the mean of an experiment on our Baxter robot, we also prove that optimizing ergonomics over the full sequences of actions, as opposed to the step-wise approach we were considering in [75] where ergonomics was optimized for single atomic actions, lead to a more ergonomic interaction.
As both human and robot agents are capable of performing the same task, this creates a need to communicate the planned sequence of actions efficiently to the human. Two problems are raised by this dynamic task allocation. First, the human need to understand the current action performed by the robot to anticipate and react if necessary. Second, the human must know beforehand or during the executions the actions that he or she has to perform and when to perform them.
|
To this purpose, we also introduce a graphical interface that displays the current action and the geometric of the scene as illustrated in figure 16. This graphical interface can be used offline to train the human on the steps required for the whole task. It can also be displayed online to show the current action to reduce the human cognitive load of understanding the action performed by the robot and understanding the action that he or her is expected to perform.
This work was submitted to the International Conference on Robotics and Automation (ICRA) and is currently under review.
Active incremental learning of robot movement primitives
A robot coworker acting as a third hand brings the challenge that its skills must be augmented and tailored as needed, over time. To this end, imitation learning can rely on the presence of the human coworker as a teacher. However, imitation learning has primarily addressed how to endow and refine robots with motor skills but not when the learning should take place. Reasoning when improvement is actually needed is, nevertheless, an essential and difficult problem to be solved. We propose an active learning algorithm that allows a robot to reason about the confidence of its movement primitives. It allows the robot to decide when a demonstration is required, making active requests to the human coworker depending on its confidence.
This capability also sheds light onto the problem of deciding how many demonstrations are needed to construct a probabilistic model when learning from demonstrations. Under active learning, the number of demonstrations is indicated by the robot, on-demand. The method can be used on a single demonstration, in a one-shot learning fashion. If the extrapolation is, however, beyond the scope of the existing demonstration—indicated by the uncertainty—an active request will be made. The proposed method also offers a principled way to train Dynamical Movement Primitives (DMPs) with contextualized demonstrations encoded by Gaussian Processes (GPs)— details can be found in [79].

The method is based on a combination of GPs and DMPs, where the former provides the confidence bounds in which the demonstrations are being extrapolated, and the latter accounts for prediction errors due to the nonlinearities of the function being approximated. Algorithm 17 shows a pseudocode of the proposed method.
|
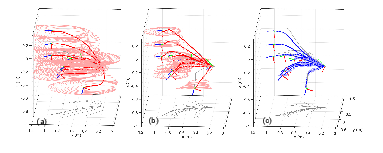
Figure 18 shows the decrease of the uncertainty on the prediction of 10 trajectories as the number of demonstrations increase (the ellipses represent the projections of one standard deviation along the trajectory). Figure 18(a)(b) and (c) show the predictions after one, two and five demonstrations, respectively. The blue color in (c) indicates that the robot has confidence it can execute the 10 predicted trajectories.