

Section: New Results
Representation Learning
Cross-situational noun and adjective learning in an interactive scenario
Participants : David Filliat [correspondant] , Yuxin Chen.
Future intelligent robots are expected to be able to adapt continuously to their environment. For this purpose, recognizing new objects and learning new words through interactive learning with humans is fundamental. Such setup results in ambiguous teaching data which humans have been shown to address using cross-situational learning, i.e. by analyzing common factors between multiple learning situations. Moreover, they have been shown to be more efficient when actively choosing the learning samples, e.g. which object they want to learn. Implementing such abilities on robots can be performed by latent-topic learning models such as Non-Negative Matrix Factorization or Latent Dirichlet Allocation. These cross-situational learning methods tackle referential and linguistic ambiguities, and can be associated with active learning strategies. We propose two such methods: the Maximum Reconstruction Error based Selection (MRES) and Confidence Base Exploration (CBE). We present extensive experiments using these two learning algorithms through a systematic analysis on the effects of these active learning strategies in contrast with random choice. In addition, we study the factors underlying the active learning by focusing on the use of sample repetition, one of the learning behaviors that have been shown to be important for humans. These results have been published in a journal paper [70]
State Representation Learning in the Context of Robotics
Participants : David Filliat [correspondant] , Natalia Diaz Rodriguez, Timothee Lesort, Mathieu Seurin.
Our understanding of the world depends highly on our capacity to produce intuitive and simplified representations which can be manipulated and combined easily to solve problems. We worked on reproducing this simplification process using a neural network to build a low dimensional state representation of the world from images acquired by a robot. As in the approach from Jonschkowski [129], we learn in an unsupervised way using prior knowledge about the world as loss functions called robotic priors.
The robotic priors loss function impose constraint in a low dimension space. We call this space the representation space and it contains the underlying parameters of the robot environment. This constraint are physic related as the time coherence of the representation, the repeatability, the proportionality and causality of the actions inside the representation space.
Imposing those constraint to sequences of images makes it possible to learn a mapping from image to our representation state space. We extend the previous approach to high dimension richer images to learn a 3D representation of the hand position of a robot from RGB images.
We propose a quantitative evaluation of the learned representation using nearest neighbors in the state space that allows to assess its quality and show both the potential and limitations of robotic priors in realistic environments. We augment image size, add distractors and domain randomization, all crucial components to achieve transfer learning to real robots.
Finally, we also contribute a new prior to improve the robustness of the representation. This prior takes profit of the initial state of the robot to bring together representation of different sequences. The applications of such low dimensional state representation range from easing reinforcement learning (RL) and knowledge transfer across tasks, to facilitating learning from raw data with more efficient and compact high level representations.
|
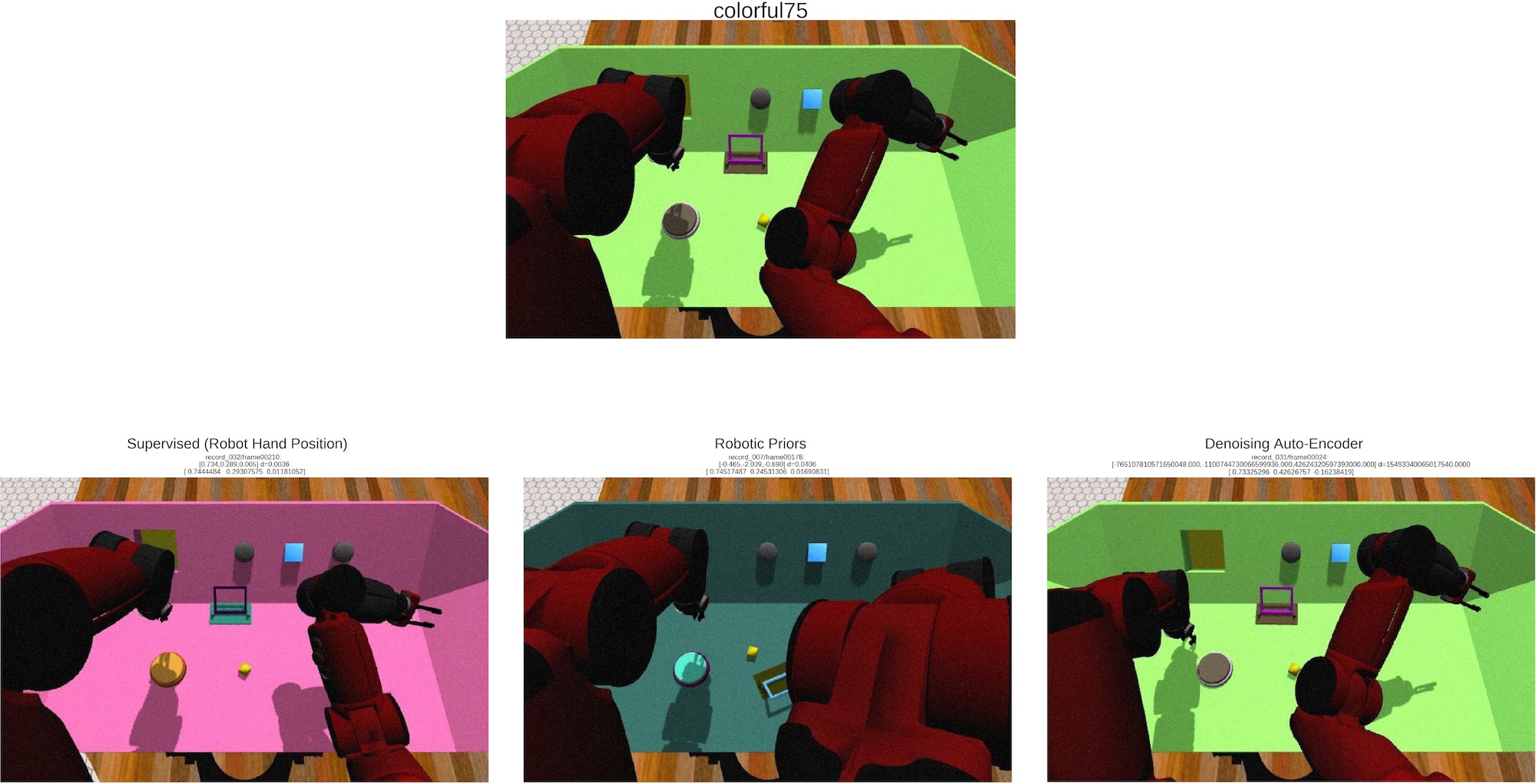
Our experiments [90] (see figure 19 for an illustration) compare results in different setup with state representation in 2 and 3D, with different amount of distractors. The results show that the robotic prior approach is able to extract high level representation such as the 3D position of an arm and organize it into a compact and coherent space of states in a challenging dataset.
Transfer Learning from Simulated to Real World Robotic Setups
Participants : Florian Golemo [correspondant] , Pierre-Yves Oudeyer.
This work was made in collaboration with Adrien Ali Taiga and Aaron Courville. Reinforcement learning with function approximation has demonstrated remarkable performance in recent years. Prominent examples include playing Atari games from raw pixels, learning complex policies for continuous control, or surpassing human performance on the game of Go. However most of these successes were achieved in non-physical environments (simulations, video games, etc.). Learning complex policies on physical systems remains an open challenge. Typical reinforcement learning methods require a lot of data which makes it unsuitable to learn a policy on a physical system like a robot, especially for dynamic tasks like throwing or catching a ball. One approach to this problem is to use simulation to learn control policies before applying them in the real world. This raises new problems as the discrepancies between simulation and real world environments ("reality gap") prevent policies trained in simulation from performing well when transfered to the real world. This is an instance of domain adaption where the input distribution of a model changes between training (in simulation) and testing (in real environment). The focus of this work is in settings where resetting the environment frequently in order to learn a policy directly in the real environment is highly impractical. In these settings the policy has to be learned entirely in simulation but is evaluated in the real environment, as zero-shot transfer.
In simulation there are differences in physical properties (like torques, link weights, noise, or friction) and in control of the agent, specifically joint control in robots. We propose to compensate for both of these source of issues with a generative model to bridge the gap between the source and target domain. By using data collected in the target domain through task-independent exploration we train our model to map state transitions from the source domain to state transition in the target domain. This allows us to improve the quality of our simulated robot by grounding its trajectories in realistic ones. With this learned transformation of simulated trajectories we are able to run an arbitrary RL algorithm on this augmented simulator and transfer the learned policy directly to the target task. We evaluate our approach in several OpenAI gym environments that were modified to allow for drastic torque and link length differences.
Measuring Uncertainty in Deep Learning Networks
Participants : Florian Golemo [correspondant] , Manuel Lopes.
As precursor to the main objective of the IGLU project, we investigated methods that would enable deep neural networks to judge their knowledge about a domain.
Neural networks, especially deep ones, have been shown to be able to model arbitrarily complex problems, and thus offer powerful tools for machine learning. Yet they come with a significant flaw of not being inherently able to represent certainty of their predictions. By adding a measure of uncertainty to neural networks, this technology could be applied to autonomous exploration and open-ended learning tasks.
Thus the goal of this project was to find a method to measure how much knowledge a neural network has about about an unlabeled data item (measure of uncertainty), and to apply this new measure in an active learning context. The objective of the latter was to demonstrate the efficiency in handpicking interesting data, to optimally extend the system's own capabilities.
We were successful in finding a measure of uncertainty that would reliably distinguish data that the network has seen before, from data that was generally unfamiliar to the network. This measure was created by measuring the entropy of the network's last layer across a batch of stochastic samples generated by adding Poisson noise to the inputs.
The measure failed however to outperform random sampling in several active learning scenarios. Yarin Gal published related work as part of his dissertation [117] after this project was concluded. He elaborated that deep neural networks are very effective in canceling out input noise. The author suggested to use existing "Dropout" layers instead for stochastic sampling, but he reaches the same conclusion of using the last layer entropy as measure of uncertainty.