

Section: New Results
Analysis
Pyramid scene parsing network in 3D: improving semantic segmentation of point clouds with multi-scale contextual information
Participants : Hao Fang, Florent Lafarge.
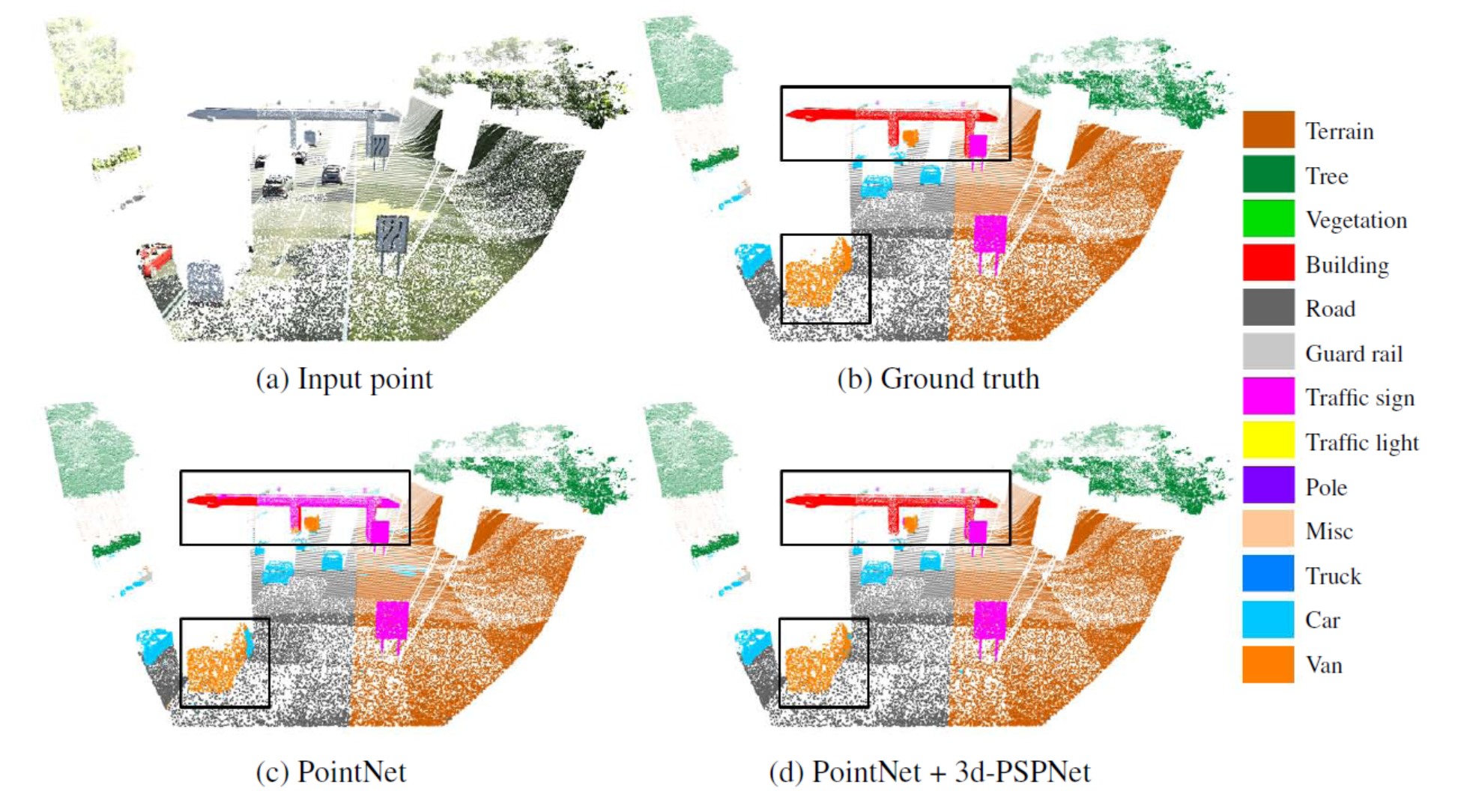
Analyzing and extracting geometric features from 3D data is a fundamental step in 3D scene understanding. Recent works demonstrated that deep learning architectures can operate directly on raw point clouds, i.e. without the use of intermediate grid-like structures. These architectures are however not designed to encode contextual information in-between objects efficiently. Inspired by a global feature aggregation algorithm designed for images, we propose a 3D pyramid module to enrich pointwise features with multi-scale contextual information. Our module can be easily coupled with 3D semantic segmantation methods operating on 3D point clouds. We evaluated our method on three large scale datasets with four baseline models. Experimental results show that the use of enriched features brings significant improvements to the semantic segmentation of indoor and outdoor scenes (See Figure 1). This work was published in the ISPRS journal of Remote Sensing and Photogrammetry [6].
|
Low-power neural networks for semantic segmentation of satellite images
Participants : Gaetan Bahl, Florent Lafarge.
In collaboration with Lionel Daniel and Matthieu Moretti (IRT Saint-Exupéry).
Semantic segmentation methods have made impressive progress with deep learning. However, while achieving higher and higher accuracy, state-of-the-art neural networks overlook the complexity of architectures, which typically feature dozens of millions of trainable parameters. As a result, these networks requires high computational resources and are mostly not suited to perform on edge devices with tight resource constraints, such as phones, drones, or satellites. In this work, we propose two highly-compact neural network architectures for semantic segmentation of images, which are up to 100 000 times less complex than state-of-the-art architectures while approaching their accuracy. To decrease the complexity of existing networks, our main ideas consist in exploiting lightweight encoders and decoders with depth-wise separable convolutions and decreasing memory usage with the removal of skip connections between encoder and decoder. Our architectures are designed to be implemented on a basic FPGA such as the one featured on the Intel Altera Cyclone V family. We demonstrate the potential of our solutions in the case of binary segmentation of remote sensing images, in particular for extracting clouds and trees from RGB satellite images. This work was published in the Low-Power Computer Vision ICCV workshop [13].
A learning approach to evaluate the quality of 3D city models
Participants : Oussama Ennafii, Florent Lafarge.
In collaboration with Arnaud Le Bris and Clément Mallet (IGN).
The automatic generation of 3D building models from geospatial data is now a standard procedure. An abundant literature covers the last two decades and several softwares are now available. However, urban areas are very complex environments. Inevitably, practitioners still have to visually assess, at city-scale, the correctness of these models and detect frequent reconstruction errors. Such a process relies on experts, and is highly time-consuming with approximately two hours per square kilometer for one expert. This work proposes an approach for automatically evaluating the quality of 3D building models. Potential errors are compiled in a novel hierarchical and versatile taxonomy. This allows, for the first time, to disentangle fidelity and modeling errors, whatever the level of detail of the modeled buildings. The quality of models is predicted using the geometric properties of buildings and, when available, Very High Resolution images and Digital Surface Models. A baseline of handcrafted, yet generic, features is fed into a Random Forest classifier. Both multi-class and multi-label cases are considered: due to the interdependence between classes of errors, it is possible to retrieve all errors at the same time while simply predicting correct and erroneous buildings. The proposed framework was tested on three distinct urban areas in France with more than 3,000 buildings. F-score values are attained for the most frequent errors. For scalability purposes, the impact of the urban area composition on the error prediction was also studied, in terms of transferability, generalization and representativeness of the classifiers. It shows the necessity of multimodal remote sensing data and mixing training samples from various cities to ensure stability of the detection ratios, even with very limited training set sizes. This work was presented at the IGARSS conference [16] and published in the PE&RS journal [5].
Robust joint image reconstruction from color and monochrome cameras
Participant : Muxingzi Li.
In collaboration with Peihan Tu (Uni. of Maryland) and Wolfgang Heidrich (KAUST).
Recent years have seen an explosion of the number of camera modules integrated into individual consumer mobile devices, including configurations that contain multiple different types of image sensors. One popular configuration is to combine an RGB camera for color imaging with a monochrome camera that has improved performance in low-light settings, as well as some sensitivity in the infrared. In this work we introduce a method to combine simultaneously captured images from such a two-camera stereo system to generate a high-quality, noise reduced color image. To do so, pixel-to-pixel alignment has to be constructed between the two captured monochrome and color images, which however, is prone to artifacts due to parallax. The joint image reconstruction is made robust by introducing a novel artifact-robust optimization formulation. We provide extensive experimental results based on the two-camera configuration of a commercially available cell phone. This work was presented at the BMVC conference [18].
Noisy supervision for correcting misaligned cadaster maps without perfect Ground Truth data
Participants : Nicolas Girard, Yuliya Tarabalka.
In collaboration with Guillaume Charpiat (Tau Inria project-team).
In machine learning the best performance on a certain task is achieved by fully supervised methods when perfect ground truth labels are available. However, labels are often noisy, especially in remote sensing where manually curated public datasets are rare. We study the multi-modal cadaster map alignment problem for which available annotations are misaligned polygons, resulting in noisy supervision. We subsequently set up a multiple-rounds training scheme which corrects the ground truth annotations at each round to better train the model at the next round. We show that it is possible to reduce the noise of the dataset by iteratively training a better alignment model to correct the annotation alignment. This work was presented at the IGARSS conference [10].
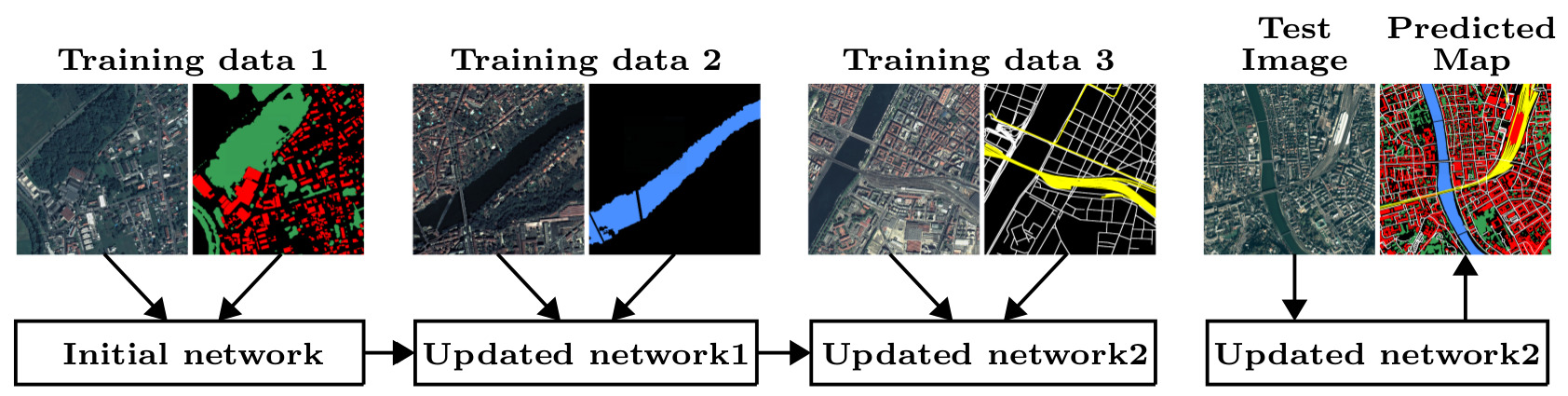
Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data
Participants : Onur Tasar, Pierre Alliez, Yuliya Tarabalka.
In spite of remarkable success of the convolutional neural networks on semantic segmentation, they suffer from catastrophic shortcomings: a significant performance drop for the already learned classes when new classes are added on the data having no annotations for the old classes. We propose an incremental learning methodology, enabling to learn segmenting new classes without hindering dense labeling abilities for the previous classes, although the entire previous data are not accessible. The key points of the proposed approach are adapting the network to learn new as well as old classes on the new training data, and allowing it to remember the previously learned information for the old classes. For adaptation, we keep a frozen copy of the previously trained network, which is used as a memory for the updated network in absence of annotations for the former classes. The updated network minimizes a loss function, which balances the discrepancy between outputs for the previous classes from the memory and updated networks, and the mis-classification rate between outputs for the new classes from the updated network and the new ground-truth. We either regularly feed samples from the stored, small fraction of the previous data or use the memory network, depending on whether the new data are collected from completely different geographic areas or from the same city (see Figure 2). Our experimental results prove that it is possible to add new classes to the network, while maintaining its performance for the previous classes, despite the whole previous training data are not available. This work was published in the IEEE journal of Selected Topics in Applied Earth Observations and Remote Sensing [9].
|
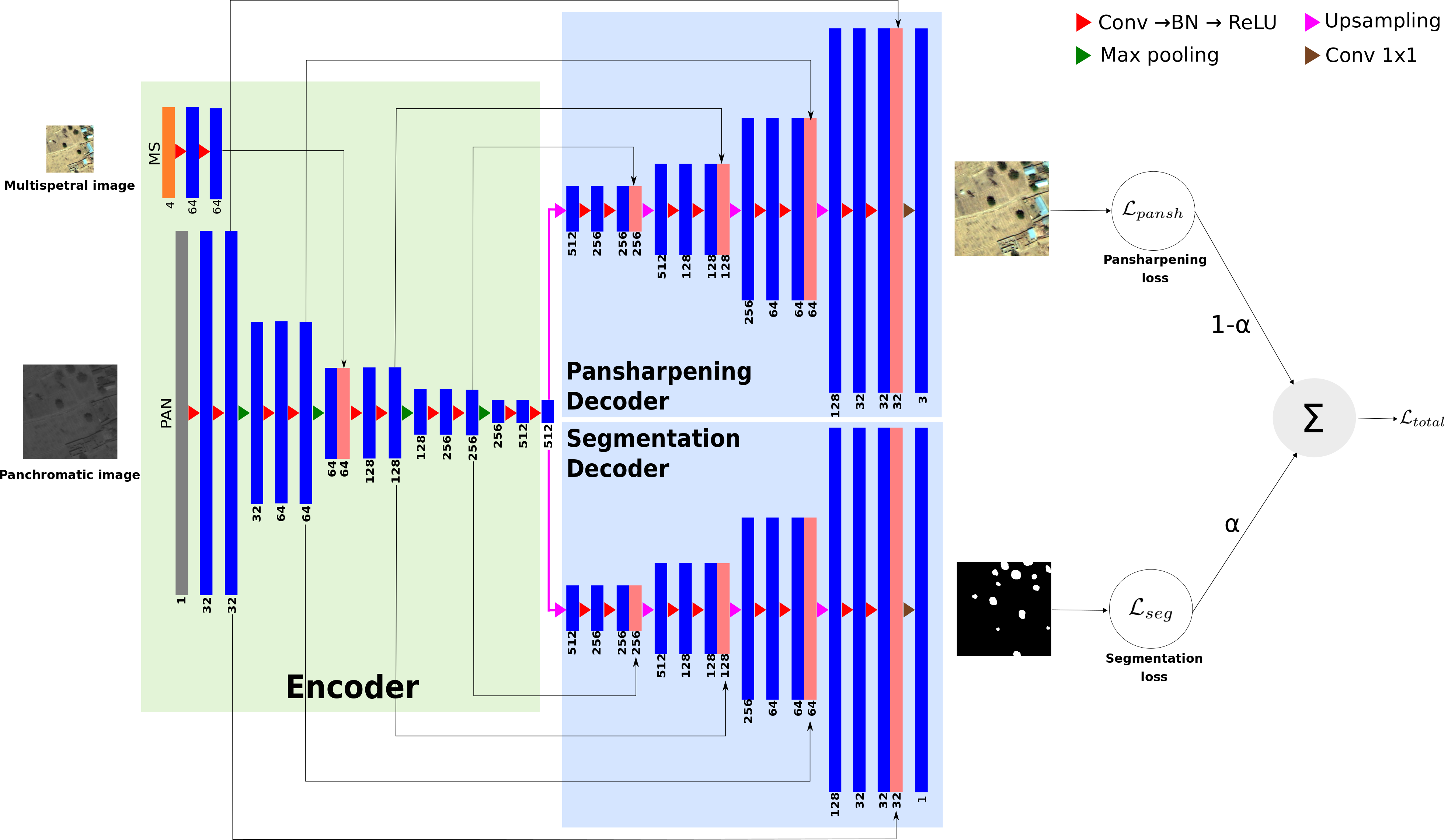
Multi-Task Deep Learning for Satellite Image Pansharpening and Segmentation
Participants : Onur Tasar, Yuliya Tarabalka.
In collaboration with Andrew Khalel (Cairo University), Guillaume Charpiat (Inria, TAU team)
In this work, we propose a novel multi-task framework, to learn satellite image pansharpening and segmentation jointly (Figure 3). Our framework is based on the encoder-decoder architecture, where both tasks share the same encoder but each one has its own decoder. We compare our framework against single-task models with different architectures. Results show that our framework outperforms all other approaches in both tasks. This work was presented at the IGARSS conference [11].
|
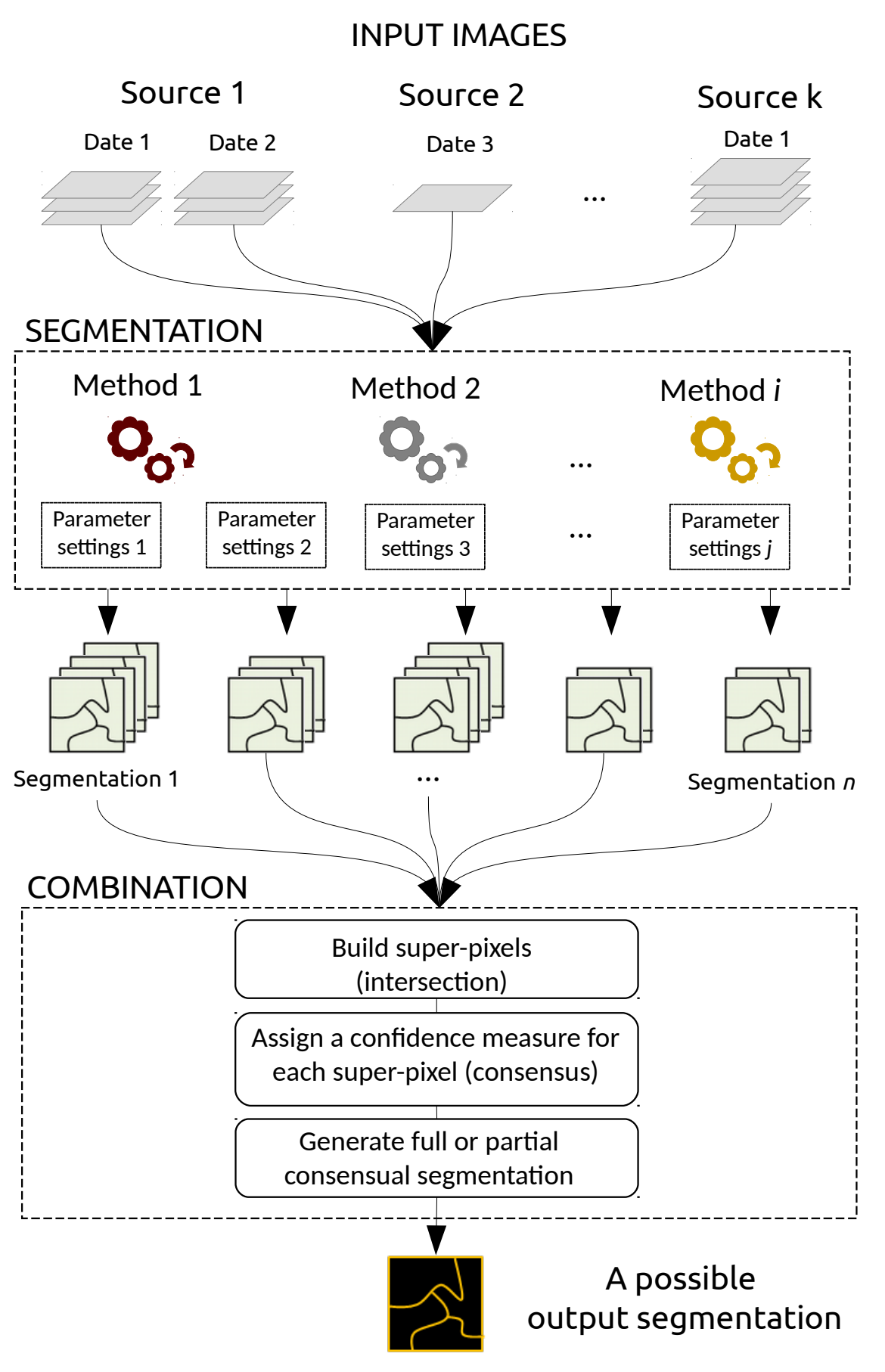
A Generic Framework for Combining Multiple Segmentations in Geographic Object-Based Image Analysis
Participant : Onur Tasar.
In collaboration with Sébastien Lefèvre (Université Bretagne Sud, IRISA) and David Sheeren (DYNAFOR, University of Toulouse, INRA)
The Geographic Object-Based Image Analysis (GEOBIA) paradigm relies strongly on the segmentation concept, i.e., partitioning of an image into regions or objects that are then further analyzed. Segmentation is a critical step, for which a wide range of methods, parameters and input data are available. To reduce the sensitivity of the GEOBIA process to the segmentation step, here we consider that a set of segmentation maps can be derived from remote sensing data. Inspired by the ensemble paradigm that combines multiple weak classifiers to build a strong one, we propose a novel framework for combining multiple segmentation maps (Figure 4). The combination leads to a fine-grained partition of segments (super-pixels) that is built by intersecting individual input partitions, and each segment is assigned a segmentation confidence score that relates directly to the local consensus between the different segmentation maps. Furthermore, each input segmentation can be assigned some local or global quality score based on expert assessment or automatic analysis. These scores are then taken into account when computing the confidence map that results from the combination of the segmentation processes. This means the process is less affected by incorrect segmentation inputs either at the local scale of a region, or at the global scale of a map. In contrast to related works, the proposed framework is fully generic and does not rely on specific input data to drive the combination process. We assess its relevance through experiments conducted on ISPRS 2D Semantic Labeling. Results show that the confidence map provides valuable information that can be produced when combining segmentations, and fusion at the object level is competitive w.r.t. fusion at the pixel or decision level. This work was published in the ISPRS journal of Geo-Information [8].