

Section: New Results
Analysis
Object Classification via Planar Abstraction
Participants : Sven Oesau, Florent Lafarge, Pierre Alliez.
In collaboration with EADS ASTRIUM
We contributed a supervised machine learning approach for classification of objects from sampled point data. The main idea consists in first abstracting the input object into planar parts at several scales, then discriminate between the different classes of objects solely through features derived from these planar shapes. Abstracting into planar shapes provides a means to both reduce the computational complexity and improve robustness to defects inherent to the acquisition process. Measuring statistical properties and relationships between planar shapes offers invariance to scale and orientation. A random forest is then used for solving the multiclass classification problem. We demonstrate the potential of our approach on a set of indoor objects from the Princeton shape benchmark and on objects acquired from indoor scenes and compare the performance of our method with other point-based shape descriptors [10]. This work was published in the proceedings of ISPRS.
Fidelity vs. Simplicity: a Global Approach to Line Drawing Vectorization
Participants : Jean-Dominique Favreau, Florent Lafarge.
In collaboration with Adrien Bousseau (GraphDeco Inria team)
Vector drawing is a popular representation in graphic design because of the precision, compactness and editability offered by parametric curves. However, prior work on line drawing vectorization focused solely on faithfully capturing input bitmaps, and largely overlooked the problem of producing a compact and editable curve network. As a result, existing algorithms tend to produce overly-complex drawings composed of many short curves and control points, especially in the presence of thick or sketchy lines that yield spurious curves at junctions. We propose the first vectorization algorithm that explicitly balances fidelity to the input bitmap with simplicity of the output, as measured by the number of curves and their degree. By casting this trade-off as a global optimization, our algorithm generates few yet accurate curves, and also disambiguates curve topology at junctions by favoring the simplest interpretations overall. We demonstrate the robustness of our algorithm on a variety of drawings, sketchy cartoons and rough design sketches (See Figure 1). This work was published at ACM SIGGRAPH 2016 [4].
|
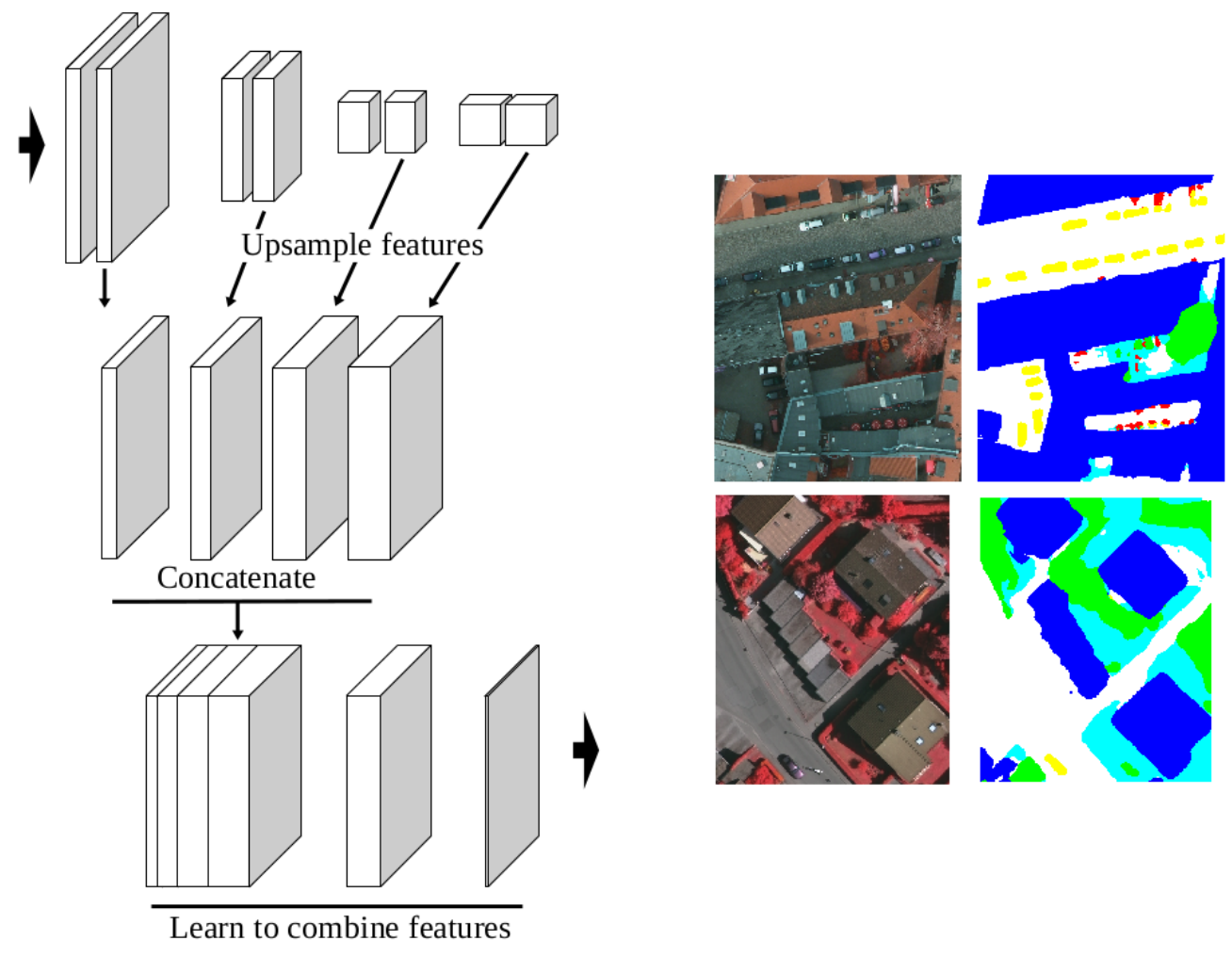
High-Resolution Semantic Labeling with Convolutional Neural Networks
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team)
Convolutional neural networks (CNNs) were initially conceived for image categorization, i.e., the problem of assigning a semantic label to an entire input image. We have address the problem of dense semantic labeling, which consists in assigning a semantic label to every pixel in an image. Since this requires a high spatial accuracy to determine where labels are assigned, categorization CNNs, intended to be highly robust to local deformations, are not directly applicable. By adapting categorization networks, many semantic labeling CNNs have been recently proposed. Our first contribution is an in-depth analysis of these architectures. We establish the desired properties of an ideal semantic labeling CNN, and assess how those methods stand with regard to these properties. We observe that even though they provide competitive results, these CNNs often do not leverage properties of semantic labeling that could lead to more effective and efficient architectures. Out of these observations, we then derive a CNN framework specifically adapted to the semantic labeling problem [13]. In addition to learning features at different resolutions, it learns how to combine these features. By integrating local and global information in an efficient and flexible manner, it outperforms previous techniques. We evaluate the proposed framework and compare it with state-of-the-art architectures on public benchmarks of high-resolution aerial image labeling.
|
Learning Iterative Processes with Recurrent Neural Networks to Correct Satellite Image Classification Maps
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team)
While initially devised for image categorization, convolutional neural networks (CNNs) are being increasingly used for the pixelwise semantic labeling of images. However, the proper nature of the most common CNN architectures makes them good at recognizing but poor at localizing objects precisely. This problem is magnified in the context of aerial and satellite image labeling, where a spatially fine object outlining is of paramount importance.
Different iterative enhancement algorithms have been presented in the literature to progressively improve the coarse CNN outputs, seeking to sharpen object boundaries around real image edges. However, one must carefully design, choose and tune such algorithms. Instead, our goal is to directly learn the iterative process itself. For this, we formulate a generic iterative enhancement process inspired from partial differential equations, and observe that it can be expressed as a recurrent neural network (RNN). Consequently, we train such a network from manually labeled data for our enhancement task. In a series of experiments we show that our RNN effectively learns an iterative process that significantly improves the quality of satellite image classification maps [12].
|

Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team)
We propose an end-to-end framework for the dense, pixelwise classification of satellite imagery with convolutional neural networks (CNNs). In our framework, CNNs are directly trained to produce classification maps out of the input images. We first devise a fully convolutional architecture and demonstrate its relevance to the dense classification problem. We then address the issue of imperfect training data through a two-step training approach: CNNs are first initialized by using a large amount of possibly inaccurate reference data, then refined on a small amount of accurately labeled data. To complete our framework we design a multi-scale neuron module that alleviates the common trade-off between recognition and precise localization. A series of experiments show that our networks take into account a large amount of context to provide fine-grained classification maps. This work was published in IEEE Transactions on Geoscience and Remote Sensing (TGRS) [5].
|

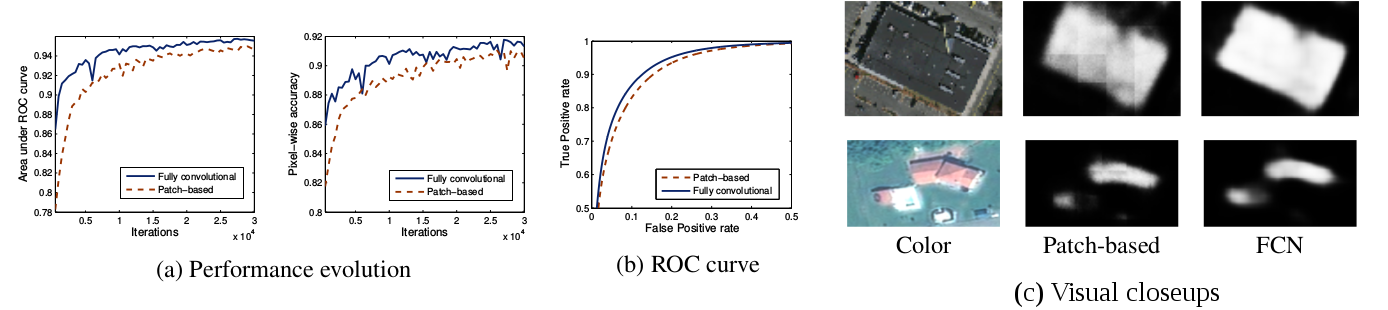
Fully Convolutional Neural Networks for Remote Sensing Image Classification
Participants : Emmanuel Maggiori, Yuliya Tarabalka, Pierre Alliez.
In collaboration with Guillaume Charpiat (Inria TAO team)
We propose a convolutional neural network (CNN) model for remote sensing image classification, i.e. the assignment of a class to every pixel in an image. Using CNNs provides us with a means of learning contextual features for large-scale image labeling. Our network consists of four stacked convolutional layers that downsample the image and extract relevant features. On top of these, a deconvolutional layer upsamples the data back to the initial resolution, producing a final dense image labeling. Contrary to previous frameworks, our architecture is a fully convolutional network (FCN), contains only convolution and deconvolution operations and no fully connected layers as in previous work. The fact of being fully convolutional removes the artifacts present in previous work by construction and is considerably more efficient. Experiments on aerial images show that our network produces more accurate classifications in lower computational time. This work was published in the proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS) [9].
|
Large-scale Remote Sensing Image Segmentation and Classification
Participants : Chunlin Xiao, Emmanuel Maggiori, Yuliya Tarabalka.
In collaboration with Guillaume Charpiat (Inria TAO team)
The representation of images with binary partition trees (BPTs) has proven to be very efficient for multiscale analysis, object detection and classification of high-resolution images. We propose a new framework for multi-class image segmentation using a binary partition tree. The region model is composed of three components : color component, probability component and shape component, some of which can be used or omitted depending on the information available and the application itself. The problem to extract a segmentation is formulated as the minimization of an energy function which can be solved with dynamical programming efficiently. However, BPT represents a hierarchy of the image regions at different scales. For large-scale images such representation can be demanding in terms of both memory and computation resources. We propose a tile-based scheme to extend the framework for processing arbitrarily large images. Experiments (see Fig. 6) prove that the algorithm can segment large images efficiently while ensuring quite similar results with respect to processing the whole image at once. This work has not been published yet.
